Date: 2월 15, 2018
태그: SQL Server 2014, Windows Server 2012
DataKeeper를 사용하여 SQL Server 2014 장애 조치 (Failover) 클러스터 인스턴스 만들기
업데이트 – 도입 된 새로운 기능으로 인해 Azure에서 SQL Server 클러스터를 배포하는 방법에 대한 지침을 업데이트했습니다. 최신 기사는 다음에서 찾을 수 있습니다. https://clusteringformeremortals.com/2015/01/01/step-by-step-how-to-configure-a-sql-server-failover-cluster-instance-fci-in- microsoft-azure-iaas-sqlserver-azure-sanless /
이것은 Windows Azure의 고 가용성 및 재해 복구 시리즈의 3 번째 게시물입니다. 이 게시물에는 다른 오류 도메인에있는 두 개의 클러스터 노드 사이에서 Windows Azure Cloud에 Windows Server 장애 조치 (Failover) 클러스터를 구현하기위한 단계별 지침이 나와 있습니다. 이 게시물은 SQL Server 2014 장애 조치 (Failover) 클러스터 인스턴스 구축에 중점을두고 있지만 다음 단계를 약간 조정하면 모든 클러스터 인식 응용 프로그램을 보호 할 수 있습니다. 다음 글에서는 아주 강력한 재해 복구 계획을 위해이 클러스터를 다른 데이터 센터의 세 번째 노드로 확장하는 방법을 설명합니다. Azure에는 클러스터 된 저장소 옵션이 없으므로 클러스터 저장소로 DataKeeper Cluster Edition이라는 타사 솔루션을 사용합니다.
이 게시물은 사용자가 Azure에서 가상 네트워크를 만들고 Azure에 이미 프로비저닝 된 첫 번째 DC를 가지고 있다고 가정합니다. 아직 해보지 않았다면이 주제에 대한 처음 두 개의 게시물을 살펴 보시기 바랍니다.
http://www.sios-apac.com/2018/02/extending-datacenter-azure-cloud/
기본 데이터 센터에 대한 VPN 연결을 만드는 것은 필수 조건은 아니지만이를 수행하는 것이 좋습니다. 이 방법으로 다음 게시물에서 논의 할 하이브리드 재해 복구 구성을 준비 할 수 있습니다.
이 글에서 설명 할 상위 단계는 다음과 같습니다.
- 두 개의 Windows Server 2012 R2 서버 프로비저닝
- 도메인에 서버 추가
- 장애 조치 (Failover) 클러스터링 기능 사용
- 클러스터 만들기
- DataKeeper Cluster Edition을 사용하여 복제 된 볼륨 클러스터 리소스 만들기
- SQL 2014 장애 조치 (Failover) 클러스터 인스턴스 설치
두 개의 Windows Server 2012 R2 서버 프로비저닝
왼쪽 열의 가상 컴퓨터 탭을 클릭 한 다음 왼쪽 하단에있는 새로 만들기 단추를 클릭하십시오.

갤러리에서 새 가상 컴퓨터 선택

우리 클러스터에서는 Windows 2012 R2 Datacenter를 선택할 것입니다.

최신 버전 릴리스 날짜를 선택하고 VM 및 크기를 지정합니다. 사용자 이름과 암호는 구성을 완료하기 위해 VM에 로그인 할 때 사용할 로컬 관리자 계정입니다.

이 다음 페이지에서 다음을 선택할 것입니다.
클라우드 서비스 : 첫 번째 VM을 프로비저닝 할 때 작성한 것과 동일한 클라우드 서비스를 선택합니다. 클라우드 서비스 문서는로드 밸런싱에 사용된다고 말하지만 모든 클라우드 VM과 DC를 동일한 클라우드 서비스에 두어 관리가 쉽지는 않습니다. 기존 클라우드 서비스를 선택하면 가상 네트워크와 서브넷이 자동으로 선택됩니다.
스토리지 계정 : 기존 스토리지 계정 선택
가용성 세트 : 이것은 매우 중요합니다. 모든 VM이 동일한 가용성 세트에 있는지 확인하려고합니다. 모든 가용 VM을 동일한 가용 세트에 넣으면 VM이 모두 다른 오류 도메인에서 실행되는 것을 보장 할 수 있습니다.

마지막 페이지에는이 VM에 도달 할 수있는 포트가 표시됩니다.

VM이 생성되면 Azure 포털에 새 VM으로 표시됩니다.

다음 단계는 VM에 스토리지를 추가하는 것입니다. Azure 모범 사례를 사용하면 데이터베이스와 로그 파일을 같은 볼륨에 넣을 수 있습니다. 그렇지 않으면 기본적으로 활성화 된 지오 – 복제 기능을 비활성화해야합니다. 다음 문서에서는이 문제점에 대해 자세히 설명합니다. http://msdn.microsoft.com/en-us/library/jj870962.aspx#BKMK_GEO
VM에 스토리지를 추가하려면 VM을 클릭 한 다음 Dashboard를 클릭하여 VM 대시 보드로 이동하십시오. 일단 거기에 연결을 클릭하십시오.
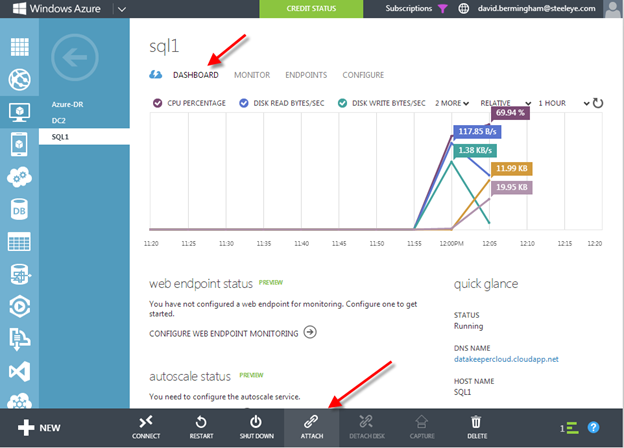
SQL Server의 저장소 옵션을 고려할 때 고려해야 할 사항이 많이 있습니다. 가장 안전하고 쉬운 방법은이 글에서 사용할 방법입니다. 데이터 및 로그 파일에 단일 볼륨을 사용하고 캐싱을 사용하지 않도록 설정합니다. Azure에 대한 SQL Server 성능 고려 사항 및 모범 사례에 대한 최신 정보를 보려면이 기사를 읽어야합니다.
http://msdn.microsoft.com/en-us/library/windowsazure/dn133149.aspx

이 추가 볼륨을 추가 한 후에는 각 VM을 열고 디스크 관리를 사용하여 볼륨을 초기화하고 포맷해야합니다. 이 데모를 위해이 볼륨을 "F : "드라이브로 포맷합니다.
이제 SQL1이라는 VM 하나가 생겼습니다. 다른 VM을 프로비저닝하고 SQL2라고하는 것과 동일한 프로세스를 완료하여 동일한 클라우드 서비스, 가용성 세트 및 스토리지 계정에 넣었는지 확인해야합니다. 또한 SQL1에 대해했던 것처럼 다른 볼륨을 SQL2에 첨부하고 F : 드라이브로 포맷하십시오.
두 VM의 프로비저닝이 끝나면 다음 단계로 넘어 가서 도메인에 추가합니다.
도메인에 그들을 추가하십시오
도메인에 SQL1 및 SQL2를 추가하는 것은 간단한 프로세스입니다. 이전 게시물과 함께 따라 왔다고 가정하면 이미 도메인을 만들고 SQ1 및 SQL2와 동일한 클라우드 서비스에 DC2라는 DC가 준비되어 있습니다. 도메인에 추가하는 것은 일반 온 – 프레미스 네트워크에서와 마찬가지로 VM에 연결하고 VM을 도메인에 추가하는 것처럼 간단합니다. 가상 네트워크를 올바르게 구성한 경우 로컬 DC2와 도메인 컨트롤러를 지정하는 DHCP에 의해 할당 된 IP 주소로 새 VM을 부팅해야합니다.
연결을 클릭하여 SQL1 및 SQL2에 대한 RDP 세션을 엽니 다.
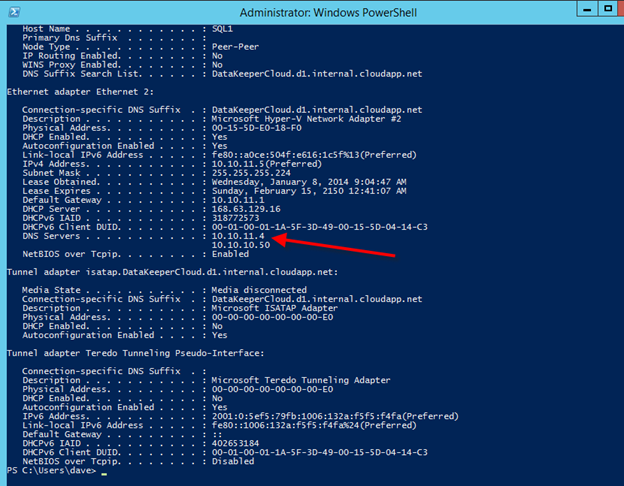
IPconfig / all은 현재 IP 구성을 보여줍니다. Windows Azure에서는 DHCP 서버를 사용하도록 설정된 주소를 그대로 두어야하지만 IP 주소는 VM 수명 동안 변경되지 않습니다. DNS 서버가 앞에서 이전에 만든 로컬 DNS 서버로 설정되어 있는지 확인해야합니다.
도메인에 SQL1과 SQL2를 추가하고 다음 단계를 계속하십시오.
장애 조치 (failover) 클러스터링 기능 사용
SQL1과 SQL2 모두에서 장애 조치 클러스터링 기능을 사용할 수 있습니다.

클러스터 만들기
클러스터링에 익숙하다면 몇 가지 예외를 제외하고 다음 단계는 매우 친숙해야하므로 Windows Azure에 클러스터를 배포 할 때 발생하는 문제를 피하려면주의하십시오.
우리는 하나의 노드 클러스터를 생성함으로써 시작할 것입니다. 그러면 두 번째 노드를 클러스터에 추가하기 전에 클러스터 이름 리소스에 필요한 조정을 할 수 있습니다. 장애 조치 (Failover) 클러스터 관리자를 사용하고 클러스터 만들기를 선택하여 시작하십시오. 선택한 서버에 SQL1을 추가하고 다음을 클릭하십시오.

SQL Server 2014를 이후 단계에서 클러스터에 설치하려면 클러스터 유효성 검사를 완료해야합니다.
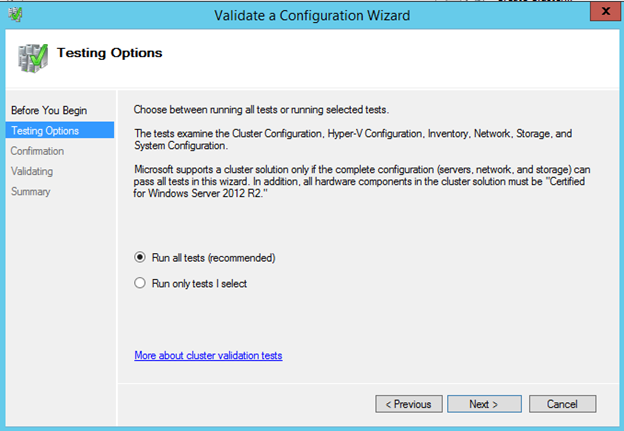

다음과 같이 클러스터 생성 프로세스의 나머지 단계를 수행하십시오. 우리는이 클러스터를 SQLCLUSTER라고 부를 것이고, 이것은 단순히 우리가 클러스터를 관리하는 데 사용하는 이름입니다. 이것은 클라이언트 응용 프로그램이 결국 연결할 이름이 아닙니다.
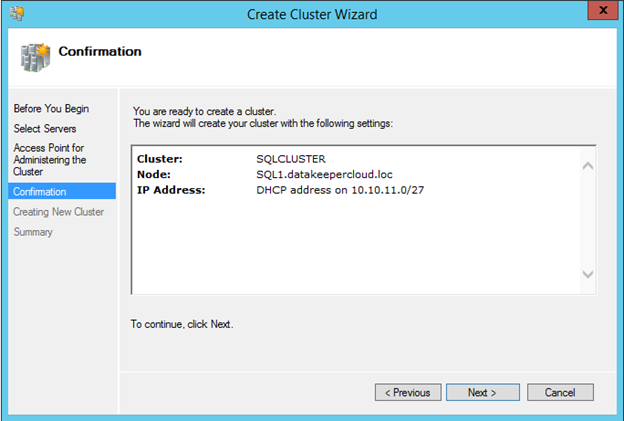

클러스터 작성 프로세스가 완료되면 클러스터 이름 리소스가 온라인 상태가되지 않는 것을 알 수 있습니다.

IP 리소스가 온라인 상태가 아니기 때문에 이름 리소스를 온라인 상태로 만들지 못했습니다. DHCP 서버가 전달한 주소가 서버의 실제 주소 (이 경우 10.10.11.5)와 같기 때문에 IP 주소가 온라인 상태가되지 못했습니다. 따라서 중복되는 IP 주소 충돌이 있습니다.
이 문제를 해결하려면 IP 주소 리소스의 속성으로 이동하여 현재 사용되지 않는 동일한 서브넷의 다른 주소로 주소를 변경해야합니다. 미래에 새로운 VM을 배치 할 가능성을 줄이기 위해 서브넷 범위의 상위 끝에있는 주소를 선택하면 Azure는 클러스터 IP 주소를 나눠주고 IP 주소 충돌을 일으킬 가능성을 줄입니다. 이러한 가능성을 없애기 위해 Microsoft는 DHCP 주소 풀에 대해 더 많은 제어권을 허용해야합니다. 현재로서는 그 가능성을 완전히 없애는 유일한 방법은 가상 사설망에 새 서브넷을 만들어 나중에 배포 할 수있는 새 VM을 만드는 것이므로이 클러스터 만이 서브넷에 있습니다. 이 서브넷에 더 많은 VM을 배포하려는 경우 동시에 사용할 수있는 모든 VM을 배포하여 사용할 IP 주소를 알 수 있으므로 클러스터에 사용할 IP 주소를 모두 사용할 수 있습니다. .
IP 주소를 변경하려면 IP 주소 클러스터 자원의 등록 정보를 선택하고 새 주소를 지정하십시오.

주소가 변경되면 클러스터 이름 리소스를 마우스 오른쪽 단추로 클릭하고 온라인 상태가되도록합니다.
이제 두 번째 노드를 클러스터에 추가 할 준비가되었습니다. 장애 조치 (Failover) 클러스터 관리자에서 노드 추가를 선택합니다.
두 번째 노드를 찾아 추가를 클릭하십시오.

모든 유효성 검사를 다시 한 번 실행하십시오.
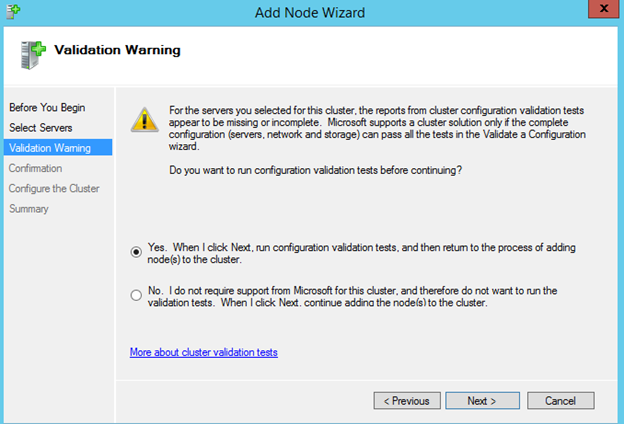

완료를 클릭하면 노드가 성공적으로 추가되었음을 알 수 있지만 Azure에 공유 저장소가 없으므로 쿼럼에 대한 디스크 감시가 생성 될 수 없습니다. 우리는 다음에 그것을 고칠 것이다.
이제 두 개의 노드 클러스터에 대한 쿼럼 요구 사항이 충족되는지 확인하기 위해 클러스터에 File Share Witness를 추가해야합니다. 파일 공유 감시는 Azure Cloud에서도 실행중인 도메인 컨트롤러 인 DC2 서버에서 구성됩니다.
Azure Private Cloud의 도메인 컨트롤러에 대한 RDP 세션을 엽니 다.
도메인 컨트롤러에 연결하고 "Quorum"이라는 파일 공유를 만듭니다. 이 예제에서는 SQLCluster라는 클러스터 컴퓨터 이름 개체에 공유 수준과 보안 (NTFS) 수준에서 읽기 / 쓰기 권한을 부여해야합니다. 파일 공유 감시를 만드는 데 익숙하지 않은 경우 이전 게시물을 검토하여 자세한 내용을 확인하십시오.


파일 공유 감시 폴더가 도메인 컨트롤러에 만들어지면 SQL1의 장애 조치 (Failover) 클러스터 관리자를 사용하여 미러링 모니터 서버를 클러스터 구성에 추가해야합니다




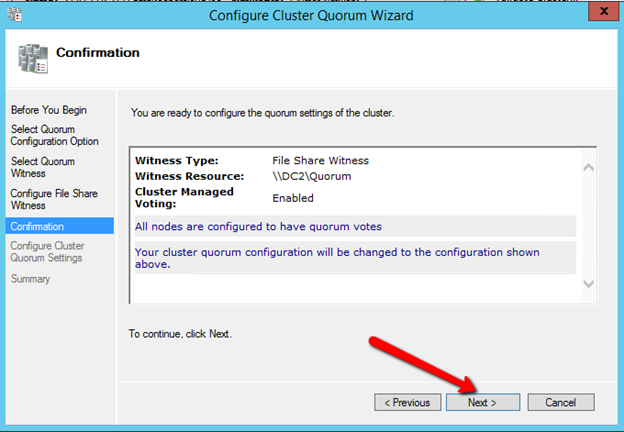
이제 파일 공유 감시가 아래와 같이 구성되어야합니다.

DataKeeper Cluster Edition을 사용하여 복제 된 볼륨 클러스터 리소스 만들기
일반적인 장애 조치 클러스터에는 SAN과 같은 공유 저장 장치가 필요합니다. Azure IaaS 클라우드는 클러스터 디스크로 사용할 수있는 저장소 솔루션을 제공하지 않으므로 DataKeeper Cluster Edition이라는 타사 데이터 복제 솔루션을 사용합니다.이 솔루션을 사용하면 다음에서 사용할 수있는 복제 볼륨 리소스를 만들 수 있습니다. 공유 디스크의 위치. 14 일 평가판 라이센스는 일반적으로 요청시 테스트가 가능합니다.
DataKeeper를 다운로드하고 설치 한 다음 SQL1과 SQL2에 라이센스를 부여하고 서버를 재부팅하십시오. 서버가 재부팅되면 SQL1에 연결하고 DataKeeper UI를 시작한 후 아래 단계를 완료하십시오.
SQL1과 SQL2 모두에 "연결"


이제 "Create Job (작업 작성)"을 클릭하고 아래에 설명 된 단계에 따라 미러 및 DataKeeper 볼륨 클러스터 리소스를 만듭니다.

미러 소스를 선택하십시오. 소스 및 대상의 IP 주소를 선택할 때 서버 자체의 IP 주소를 선택해야합니다. 클러스터 IP 주소를 선택하지 마십시오!


두 노드가 Azure Cloud에있는이 구현의 경우, 아래 그림과 같이 압축없이 동기 복제를 선택하십시오.

완료를 클릭하면 Windows 서버 장애 조치 (Failover) 클러스터링에이 미러를 등록할지 묻는 메시지가 표시됩니다. 예를 클릭하십시오.
Windows Server 장애 조치 (Failover) 클러스터 GUI를 열면 사용 가능한 저장소에 DataKeeper 볼륨 리소스가 있음을 알 수 있습니다.
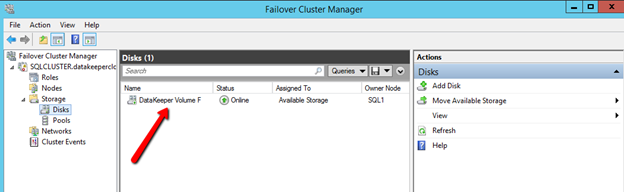
이제 SQL Server를 클러스터에 설치할 준비가되었습니다.
SQL Server 2014 장애 조치 (Failover) 클러스터 인스턴스 설치
SQL Server 2014 클러스터 설치를 시작하려면 SQL 2014 ISO를 SQL1 및 SQL2로 다운로드해야합니다. 간단한 두 노드 클러스터에 SQL Server 2014 Standard Edition을 사용할 수 있습니다. 다음 게시글에서 설명 할 재해 복구를 위해이 클러스터를 제 3의 사이트로 확장하려는 경우 Standard Edition은 2 노드 클러스터 만 지원하기 때문에 Enterprise Edition이 필요합니다. SQL Server Standard Edition보다 단순한 두 노드 솔루션 만 찾는다면 훨씬 경제적 인 솔루션이 될 수 있습니다.
SQL Server 2014가 서버에 다운로드되면 ISO를 탑재하고 설치 프로그램을 실행합니다. 우리가 원하는 옵션은 고급 탭에 있습니다. 고급 탭을 열고 "고급 클러스터 준비"를 실행하십시오. 제 좋은 친구이자 동료 인 Cluster MVP 인 Robert Smit이 고급 옵션 사용에 관해 저에게 이야기했습니다. 기본적으로 고급 옵션을 사용하면 설치를 두 개의 다른 프로세스, 준비 및 완료로 나눌 수 있습니다. 일반적으로 활성 디렉터리 및 권한과 관련된 클러스터 설치에서는 많은 문제가 발생할 수 있습니다. 표준 설치 방법을 사용하는 경우 설치가 완료되기까지 20 분 이상 기다릴 수 있습니다. 단, 마지막 순간에 클러스터가 CNO를 활성 디렉토리에 등록 할 수없고 전체 설치가 실패한다는 것을 알아야합니다. 전체 설치가 실패했을뿐만 아니라 부분적으로 설치된 SQL Server 클러스터가있을 수 있으며 정리해야 할 혼란이 있습니다. 고급 방법을 사용하면 클러스터 완료 중 위험 부분을 막 끝에 놓아 위험을 최소화 할 수 있습니다. 클러스터 완료가 실패하면 문제를 진단하고 클러스터 완료 프로세스 만 다시 실행하면됩니다.
정말로 시간을 절약하고 싶다면 로버트의 구성 파일에 SQL 클러스터 설치에 관한 기사를 읽어보십시오. 설치하기가 아주 쉽고 여러 번 설치하는 경우 많은 시간을 절약 할 수 있습니다. 그러나 우리의 목적을 위해서 우리는 아래와 같이 GUI로 SQL 설치를 진행할 것입니다.


데모 목적으로 각 서비스에 대한 관리자 계정을 사용했습니다. 프로덕션 환경에서는 각 서비스에 대한 별도의 계정을 모범 사례로 만들어야합니다.


설치가 완료되면 다음과 같이 보입니다.
이제 우리는 설치의 두 번째 파트 인 Advanced Cluster Completion으로 이동할 준비가되었습니다.

SQL 인스턴스에 이름을 지정하십시오. 이것은 클라이언트가 연결할 이름입니다. 이 경우 SQLINSTANCE1이라고했습니다.

이것은 마술이 일어나는 곳입니다. 앞에서 설명한 것처럼 DataKeeper에서 미러를 구성한 경우 실제로 복제 된 볼륨 쌍일 때 DataKeeper 볼륨이 사용 가능한 공유 디스크로 표시됩니다.

클러스터 네트워크 구성 페이지 중 하나 인 경우 IPv4를 선택하고 서브넷에서 사용하지 않는 주소를 지정하는 것이 중요합니다. 앞에서 설명한 것처럼이 주소는 Azure가 나중에 다른 VM에 할당 할 위험을 최소화하기 위해 DHCP 범위의 가장 높은 끝 부분에 있어야합니다. Windows Azure가 IP 주소와 DHCP 범위를보다 강력하게 제어 할 때까지 가능한 충돌을 피하기 위해 클러스터 전용 서브넷을 준비하는 것이 좋습니다. 나중에 클러스터를 만든 후에이 클라이언트 액세스 지점을 삭제하고 http://blogs.msdn.com/b/sqlalwayson/archive/2013/08/06/availability-ko에 설명 된대로 클라이언트 액세스 지점을 추가해야합니다. group-listener-in-windows-azure-now-supported-and-scripts-for-cloud-only-configuration.aspx가 있습니다. 앞으로이 프로세스에 대해 자세히 설명하는 블로그 게시물을 게시 할 예정입니다.

이 페이지에서 현재 사용자 추가를 클릭하거나 SQL Server를 관리하는 데 사용할 계정을 지정하십시오.
SQL Server 2012부터 tempdb는 더 이상 SQL Server 클러스터에 속하지 않아도됩니다. tempdb를 복제되지 않은 볼륨으로 이동하는 경우 각 노드에 디렉터리 구조가 있는지 확인해야합니다. tempdb의 위치를 변경하려면 데이터 디렉터리 탭을 클릭하고 tempdb가있는 위치를 변경합니다.
SQL1에서 설치가 완료되면 SQL2에서 SQL 설치 프로그램을 실행하고 두 번째 노드를 클러스터에 추가합니다. SQL2에서 설치 프로그램을 실행하고 SQL Server 장애 조치 클러스터에 노드 추가를 선택하십시오.

설치가 완료되면 이제 Azure Cloud에서 실행되는 완전한 기능의 SQL Server 2014 장애 조치 (Failover) 클러스터 인스턴스를 갖게됩니다. 각 인스턴스는 다른 장애 도메인에 있으므로 높은 수준의 복원력을 제공합니다. 내 게시물에 설명 된대로 클라이언트 액세스 포인트로 클라이언트 액세스 포인트를 교체해야합니다 …
이 시리즈의 다음 글에서는이 두 노드 클러스터를 다중 사이트 클러스터의 세 번째 노드로 확장하는 방법을 설명합니다. 이 세 번째 노드는 사내 구축 형 데이터 센터에 배치되어 고 가용성 및 재해 복구의 궁극적 인면을 제공합니다.
SQL Server 2014 장애 조치 (Failover) 클러스터 인스턴스에 대한 자세한 내용은 여기를 참조하십시오.
https://clusteringformeremortals.com/2014/01/10/creating-a-sql-server-2014-alwayson-failover-cluster-fci-instance-in-windows-azure-iaas-azure-cloud/에서 허락을 받아 재현했습니다.