
Mengelola Pemulihan Real-Time Dalam Pemadaman Awan Besar
Bencana terjadi, membuat kenyataan downtime tiba-tiba. Tetapi ada hal-hal yang dapat dilakukan oleh semua pelanggan untuk bertahan hidup dari pemadaman cloud apa pun. Banyak hal terjadi. Kegagalan — besar dan kecil — tidak bisa dihindari. Apa yang tidak bisa dihindari adalah periode downtime yang diperpanjang. Pertimbangkan hari ketika awan Azure Wilayah Microsoft Tengah Selatan AS mengalami kegagalan yang dahsyat. Sebuah badai ganas menyebabkan serangkaian masalah yang akhirnya meruntuhkan seluruh pusat data. Dalam apa yang oleh beberapa orang disebut "Hari Azure Cloud Jatuh dari Langit," kebanyakan pelanggan offline, tidak hanya selama beberapa detik atau menit, tetapi untuk satu hari penuh. Beberapa offline selama lebih dari dua hari. Sementara Microsoft sejak itu telah menangani banyak masalah yang menyebabkan pemadaman, insiden itu akan lama diingat oleh para profesional TI. Itu berita buruknya. Berita baiknya adalah: Ada hal-hal yang bisa dilakukan pelanggan Azure untuk bertahan hidup dari hampir semua gangguan. Itu bisa dari satu server gagal ke seluruh pusat data menjadi offline. Faktanya, pelanggan Azure yang menerapkan ketersediaan tinggi dan / atau ketentuan pemulihan bencana, lengkap dengan replikasi data real-time dan failover otomatis yang cepat, dapat berharap tidak mengalami kehilangan data, dan sedikit atau tidak ada downtime ketika bencana terjadi. Lihat juga: Nutanix melihat cloud perusahaan memenangkan perlombaan cloud
Mengelola Pemadaman Awan
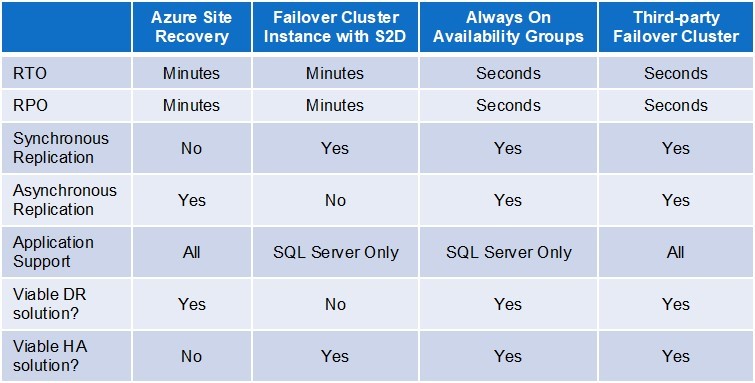
Artikel ini membahas empat opsi untuk menyediakan perlindungan pemulihan bencana (DR) dan ketersediaan tinggi (HA) dalam konfigurasi cloud hybrid dan Azure murni. Dua opsi khusus untuk database Microsoft SQL Server, yang merupakan aplikasi populer di Azure cloud; dua opsi lainnya adalah agnostik aplikasi. Keempat opsi, yang juga dapat digunakan dalam berbagai kombinasi, dibandingkan dalam tabel dan termasuk:
- Layanan Azure Site Recovery (ASR)
- Contoh SQL Server Failover Cluster dengan Ruang Penyimpanan Langsung
- SQL Server Selalu Di Ketersediaan Grup
- Perangkat Lunak Failover Clustering pihak ketiga
RTO dan RPO 101
Sebelum menjelaskan keempat opsi, perlu memiliki pemahaman dasar tentang dua metrik yang digunakan untuk menilai efektivitas ketentuan DR dan HA: Sasaran Waktu Pemulihan dan Sasaran Titik Pemulihan. Mereka yang akrab dengan RTO dan RPO dapat melewati bagian ini. RTO adalah durasi pemadaman maksimum yang dapat ditoleransi. Aplikasi pemrosesan transaksi online umumnya memiliki RTO terendah, dan aplikasi yang sangat kritis sering memiliki RTO hanya beberapa detik. RPO adalah periode maksimum di mana kehilangan data dapat ditoleransi. Jika tidak ada kehilangan data yang dapat ditoleransi, maka RPO adalah nol. RTO biasanya akan menentukan jenis perlindungan HA dan / atau DR yang dibutuhkan. Waktu pemulihan yang rendah biasanya menuntut ketentuan HA yang kuat yang melindungi terhadap kegagalan sistem dan perangkat lunak yang rutin, sementara RTO yang lebih lama dapat puas dengan ketentuan DR dasar yang dirancang untuk melindungi terhadap bencana yang lebih luas, tetapi jauh lebih jarang terjadi. Replikasi data yang digunakan dengan ketentuan HA dan DR dapat menciptakan kebutuhan untuk tradeoff potensial antara RTO dan RPO. Dalam lingkungan LAN latensi rendah, di mana replikasi dapat disinkronkan, kumpulan data primer dan sekunder dapat diperbarui secara bersamaan. Hal ini memungkinkan pemulihan penuh terjadi secara otomatis dan dalam waktu nyata, sehingga memungkinkan untuk memenuhi waktu pemulihan yang paling menuntut dan tujuan titik pemulihan (masing-masing beberapa detik dan nol) tanpa ada tradeoff yang diperlukan. Di seberang WAN, sebaliknya, memaksa primer untuk menunggu sekunder untuk mengkonfirmasi penyelesaian pembaruan untuk setiap transaksi akan berdampak buruk pada kinerja. Untuk alasan ini, replikasi data dalam WAN biasanya tidak sinkron. Ini dapat menciptakan tradeoff antara mengakomodasi RTO dan RPO yang biasanya menghasilkan peningkatan waktu pemulihan. Inilah alasannya: Untuk memenuhi RPO nol, proses manual diperlukan untuk memastikan semua data (misalnya dari log transaksi) telah sepenuhnya direplikasi pada sekunder sebelum kegagalan dapat terjadi. Upaya ekstra ini memperpanjang waktu pemulihan, dan itulah sebabnya konfigurasi seperti itu sering digunakan untuk DR dan bukan HA.
Layanan Pemulihan Situs Azure (ASR)
ASR adalah penawaran DR-as-a-service (DRaaS) Azure. ASR mereplikasi mesin fisik dan virtual ke situs Azure lain, berpotensi di wilayah lain, atau dari instance lokal ke cloud Azure. Layanan ini memberikan pemulihan yang cukup cepat dari pemadaman sistem dan situs, dan juga memfasilitasi pemeliharaan yang direncanakan dengan menghilangkan waktu henti selama pemutakhiran perangkat lunak bergulir. Seperti semua penawaran DRaaS, ASR memiliki beberapa keterbatasan, yang paling serius adalah ketidakmampuan untuk mendeteksi dan gagal secara otomatis dari banyak kegagalan yang menyebabkan downtime tingkat aplikasi. Tentu saja, inilah mengapa layanan ini dikarakterisasi sebagai untuk DR dan bukan untuk HA. Dengan ASR, waktu pemulihan biasanya 3-4 menit tergantung, tentu saja, pada seberapa cepat administrator dapat secara manual mendeteksi dan merespons masalah. Seperti dijelaskan di atas, kebutuhan untuk replikasi data tidak sinkron di WAN selanjutnya dapat meningkatkan waktu pemulihan untuk aplikasi dengan RPO nol.
Contoh SQL Server Failover Cluster dengan Ruang Penyimpanan Langsung
SQL Server menawarkan dua opsi HA / DR-nya sendiri: Mesin Virtual Failover Cluster (dibahas di sini) dan Grup Ketersediaan Selalu Aktif (dibahas berikutnya). FCI memberikan dua keuntungan: Fitur ini tersedia dalam Edisi Standar SQL Server yang lebih murah, dan tidak tergantung pada penyimpanan bersama seperti halnya cluster HA tradisional. Keuntungan yang terakhir ini penting karena penyimpanan bersama tidak tersedia di cloud — dari Microsoft atau penyedia layanan cloud lainnya. Pilihan populer untuk penyimpanan di Azure cloud adalah Storage Spaces Direct (S2D), yang mendukung berbagai aplikasi, dan dukungannya untuk SQL Server melindungi seluruh instance dan bukan hanya database. Kelemahan utama S2D adalah bahwa server harus berada dalam satu pusat data tunggal, membuat opsi ini cocok untuk beberapa kebutuhan HA tetapi tidak untuk DR. Untuk perlindungan multi-situs HA dan DR, replikasi data yang diperlukan harus disediakan oleh pengiriman log atau solusi pengelompokan failover pihak ketiga.
SQL Server Selalu Di Ketersediaan Grup
Sementara Always On Availability Groups adalah penawaran SQL Server yang paling mampu untuk HA dan DR, itu membutuhkan lisensi Enterprise Edition yang lebih mahal. Opsi ini dapat memberikan waktu pemulihan 5-10 detik dan titik pemulihan detik atau kurang. Itu juga menawarkan sekunder dibaca untuk query database (dengan lisensi yang sesuai), dan tidak menempatkan batasan pada ukuran database atau jumlah instance sekunder. Konfigurasi Always On Availability Groups yang menyediakan perlindungan HA dan DR terdiri dari pengaturan tiga simpul dengan dua node dalam satu Set Ketersediaan atau Zona, dan yang ketiga di Azure Region terpisah. Satu batasan penting adalah bahwa hanya database yang direplikasi dan bukan seluruh instance SQL, yang harus dilindungi oleh beberapa cara lain. Selain menjadi penghalang biaya untuk beberapa aplikasi database, pendekatan ini memiliki kelemahan lain. Khusus untuk aplikasi memerlukan departemen TI untuk mengimplementasikan ketentuan HA dan DR lainnya untuk semua aplikasi lainnya. Penggunaan beberapa solusi HA / DR dapat secara substansial meningkatkan kompleksitas dan biaya (untuk perizinan, pelatihan, implementasi dan operasi yang sedang berlangsung), menjadikan ini alasan lain mengapa organisasi semakin memilih menggunakan solusi pihak ketiga agnostik aplikasi.
Perangkat Lunak Failover Clustering pihak ketiga
Dengan desain aplikasi-agnostik dan platform-agnostik, perangkat lunak failover clustering mampu memberikan solusi HA dan DR lengkap untuk hampir semua aplikasi di lingkungan cloud pribadi, publik, dan hybrid. Ini termasuk untuk Windows dan Linux. Menjadi agnostik aplikasi menghilangkan kebutuhan untuk memiliki ketentuan HA / DR yang berbeda untuk aplikasi yang berbeda. Menjadi platform-agnostik memungkinkan untuk memanfaatkan berbagai kemampuan dan layanan di Azure cloud, termasuk Fault Domains, Kumpulan dan Zona Ketersediaan, Pasangan Wilayah, dan Pemulihan Situs Azure. Sebagai solusi lengkap, perangkat lunak ini mencakup, sekurang-kurangnya, replikasi data waktu-nyata, pemantauan berkelanjutan yang mampu mendeteksi kegagalan pada tingkat aplikasi, dan kebijakan yang dapat dikonfigurasi untuk failover dan failback. Sebagian besar solusi juga menawarkan berbagai kemampuan bernilai tambah yang memungkinkan cluster failover untuk memberikan waktu pemulihan di bawah 20 detik dengan kehilangan data minimal atau tidak ada sama sekali untuk memenuhi hampir semua kebutuhan HA / DR.
Menjadikannya Nyata
Keempat opsi, apakah beroperasi secara terpisah atau bersamaan, dapat memiliki peran untuk dimainkan dalam membuat kontinum perlindungan DR dan HA lebih efektif dan terjangkau untuk spektrum penuh aplikasi perusahaan. Ini termasuk dari mereka yang dapat mentolerir beberapa kehilangan data dan periode waktu henti yang panjang, hingga mereka yang membutuhkan pemulihan waktu nyata untuk mencapai lima hingga 9 waktu kerja dengan kehilangan data yang minimal atau tidak sama sekali. Untuk selamat dari pemadaman cloud berikutnya di dunia nyata, pastikan bahwa ketentuan DR dan / atau HA apa pun yang Anda pilih dikonfigurasikan dengan setidaknya dua node yang tersebar di dua situs. Pastikan juga untuk memahami seberapa baik ketentuan memenuhi waktu pemulihan masing-masing aplikasi dan tujuan titik pemulihan. Serta segala keterbatasan yang mungkin ada, termasuk kebutuhan akan proses manual yang diperlukan untuk mendeteksi semua kemungkinan kegagalan, dan memicu kegagalan dengan cara yang memastikan kesinambungan aplikasi dan integritas data.
Tentang Jonathan Meltzer
Jonathan Meltzer adalah Direktur, Manajemen Produk, di SIOS Technology. Ia memiliki lebih dari 20 tahun pengalaman dalam manajemen produk dan pemasaran untuk perangkat lunak dan produk SaaS yang membantu pelanggan mengelola, mengubah, dan mengoptimalkan sumber daya manusia dan sumber daya TI mereka. Direproduksi dari RTinsight