| Desember 6, 2018 |
12 Item Daftar Periksa untuk Memilih Solusi Berkesediaan Tinggi |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Desember 5, 2018 |
Apakah Anda Tahu Berapa Banyak Bandwidth Untuk Mendukung Replikasi Real-Time? |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Desember 3, 2018 |
Solusi Ketersediaan Tinggi SAP Untuk Linux |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| November 30, 2018 |
Cara Membuat Cluster MySQL 2-Node Tanpa Penyimpanan Bersama – Bagian 2 |




















|
Bidang |
Tips |
| Jenis Sumber Daya | Pilih Alamat IP sebagai jenis sumber daya dan klik Berikutnya. |
| Jenis Switchback | Pilih Cerdas dan klik Berikutnya. |
| Server | Pilih server tempat sumber IP akan dibuat. Pilih server utama Anda dan klik Berikutnya. |
| Sumber Daya IP | Masukkan informasi IP virtual dan klik Next. (Ini adalah alamat IP yang tidak digunakan di mana pun di jaringan Anda. Semua klien akan menggunakan alamat ini untuk terhubung ke sumber daya yang dilindungi.) |
| Netmask | Masukkan subnet mask IP yang akan digunakan oleh TCP / IP Anda di server target. Setiap netmask standar untuk kelas alamat sumber TCP / IP tertentu adalah valid. Subnet mask, dikombinasikan dengan alamat IP, menentukan subnet yang akan digunakan oleh TCP / IP dan harus konsisten dengan konfigurasi jaringan. Konfigurasi sampel ini 255.255.255.0 digunakan untuk subnet mask pada kedua jaringan. |
| Koneksi jaringan | Memasuki kartu Ethernet fisik dengan antarmuka alamat IP. Pilih koneksi jaringan yang akan memungkinkan alamat IP virtual Anda dapat dirutekan. Pilih NIC yang benar dan klik Next. |
| Tag Sumber Daya IP | Terima nilai default dan klik Berikutnya. Nilai ini hanya mempengaruhi bagaimana IP ditampilkan di GUI. Sumber daya IP akan dibuat di server utama. |
LifeKeeper membuat dan memvalidasi sumber daya Anda. Setelah menerima pesan bahwa sumber daya telah berhasil dibuat, klik Berikutnya. Langkah 13: Tinjau pemberitahuan tentang penciptaan sumber day a yang sukses Sekarang Anda dapat menyelesaikan proses perluasan sumber daya IP ke server sekunder. Langkah 14: Perluas sumber daya IP ke server seku
a yang sukses Sekarang Anda dapat menyelesaikan proses perluasan sumber daya IP ke server sekunder. Langkah 14: Perluas sumber daya IP ke server seku nder Proses memperluas sumber daya IP dimulai secara otomatis setelah Anda selesai membuat sumber daya alamat IP dan klik Berikutnya. Anda juga dapat memulai proses ini dari sumber alamat IP yang ada, dengan mengklik kanan sumber daya aktif dan memilih Extend Resource Hierarchy. Gunakan informasi dalam tabel berikut untuk menyelesaikan prosedur.
nder Proses memperluas sumber daya IP dimulai secara otomatis setelah Anda selesai membuat sumber daya alamat IP dan klik Berikutnya. Anda juga dapat memulai proses ini dari sumber alamat IP yang ada, dengan mengklik kanan sumber daya aktif dan memilih Extend Resource Hierarchy. Gunakan informasi dalam tabel berikut untuk menyelesaikan prosedur.
|
Bidang |
Entri atau Catatan yang Disarankan |
| Jenis Switchback | Tinggalkan sebagai cerdas dan klik Next. |
| Prioritas Template | Tinggalkan sebagai default (1). |
| Prioritas Target | Tinggalkan sebagai default (10). |
| Antarmuka Jaringan | Ini adalah kartu Ethernet fisik dengan antarmuka alamat IP. Pilih koneksi jaringan yang akan memungkinkan alamat IP virtual Anda dapat dirutekan. NIC fisik yang benar harus dipilih secara default. Verifikasi dan kemudian klik Berikutnya. |
| Tag Sumber Daya IP | Tinggalkan sebagai default. |
| Mode Kembalikan Target | Pilih Aktifkan dan klik Berikutnya. |
| Targetkan Pemulihan Lokal | Pilih Ya untuk mengaktifkan pemulihan lokal untuk sumber daya SQL pada server target. |
| Prioritas Backup | Terima nilai default. |
Setelah menerima pesan bahwa operasi ekstensi hierarki selesai, klik Selesai dan kemudian klik Done. Sumber daya IP Anda (contoh: 192.168.197.151) sekarang sepenuhnya terlindung dan dapat mengapung di antara node klaster, sesuai kebutuhan. Dalam GUI LifeKeeper, Anda dapat melihat bahwa sumber daya IP terdaftar sebagai Aktif pada node klaster utama dan Standby pada simpul klaster sekunder. Langkah 15: Tinjau status sumber daya IP pada nodus primer dan sekunder 
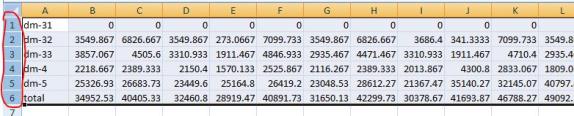
Membuat Cermin Dan Memulai Replikasi Data
Setengah untuk Membuat Cluster 2-Node MySQL Tanpa Penyimpanan Bersama! Anda siap untuk menyiapkan dan mengonfigurasi sumber replikasi data, yang akan Anda gunakan untuk menyinkronkan data MySQL antara node cluster. Untuk contoh ini, data yang akan direplikasi berada di partisi / var / lib / mysql pada simpul klaster utama. Volume sumber harus dipasang di server utama, volume target tidak boleh dipasang di server sekunder, dan ukuran volume target harus sama dengan atau lebih besar dari ukuran volume sumber. Screenshot berikut mengilustrasikan serangkaian langkah berikutnya. Langkah 16: Buat hierarki sumber day a. Langkah 17: Pilih ARK Replikasi Data
a. Langkah 17: Pilih ARK Replikasi Data . Gunakan nilai-nilai ini di panduan Replikasi Data.
. Gunakan nilai-nilai ini di panduan Replikasi Data.
|
Bidang |
Entri atau Catatan yang Disarankan |
| Jenis Switchback | Pilih Cerdas. |
| Server | Pilih LinuxPrimary (node cluster utama atau sumber cermin). |
| Tipe Hirarki | Pilih Replicate Any Filesystem. |
| Existing Mount Point | Pilih partisi yang dipasang untuk ditiru; dalam contoh ini, / var / lib / mysql. |
| Tag Sumber Daya Replikasi Data | Tinggalkan sebagai default. |
| File Resource Resource System | Tinggalkan sebagai default. |
| File Bitmap | Tinggalkan sebagai default. |
| Aktifkan Replikasi Asinkron | Tinggalkan sebagai default (Ya). |
Klik Berikutnya untuk memulai pembuatan hirarki sumber daya replikasi data. GUI akan menampilkan pesan berikut. Langkah 18: Mulai membuat sumber daya Replikasi Data Klik Berikutnya untuk memulai proses memperluas sumber daya replikasi data. Terima semua pengaturan default. Ketika ditanya tentang target disk, pilih partisi gratis pada server target Anda yang Anda buat sebelumnya dalam proses ini. Pastikan untuk memilih partisi yang lebih besar atau lebih besar dari volume sumber dan yang tidak terpasang pada sistem target. Langkah 19: Mulai ekstensi sumber Replikasi Data
Klik Berikutnya untuk memulai proses memperluas sumber daya replikasi data. Terima semua pengaturan default. Ketika ditanya tentang target disk, pilih partisi gratis pada server target Anda yang Anda buat sebelumnya dalam proses ini. Pastikan untuk memilih partisi yang lebih besar atau lebih besar dari volume sumber dan yang tidak terpasang pada sistem target. Langkah 19: Mulai ekstensi sumber Replikasi Data  Akhirnya, Anda diminta untuk memilih jaringan tempat replikasi yang Anda inginkan berlangsung. Secara umum, memisahkan lalu lintas pengguna dan aplikasi dari lalu lintas replikasi Anda adalah praktik terbaik. Konfigurasi contoh ini memiliki dua antarmuka jaringan terpisah, "NIC publik" kami pada subnet 192.168.197.X dan "private / backend NIC" pada subnet 192.168.198.X. Kami akan mengkonfigurasi replikasi untuk melewati jaringan back-end 192.168.198.X, sehingga lalu lintas pengguna dan aplikasi tidak bersaing dengan replikasi. Langkah 20: Pilih jaringan untuk lalu lintas replikasi.
Akhirnya, Anda diminta untuk memilih jaringan tempat replikasi yang Anda inginkan berlangsung. Secara umum, memisahkan lalu lintas pengguna dan aplikasi dari lalu lintas replikasi Anda adalah praktik terbaik. Konfigurasi contoh ini memiliki dua antarmuka jaringan terpisah, "NIC publik" kami pada subnet 192.168.197.X dan "private / backend NIC" pada subnet 192.168.198.X. Kami akan mengkonfigurasi replikasi untuk melewati jaringan back-end 192.168.198.X, sehingga lalu lintas pengguna dan aplikasi tidak bersaing dengan replikasi. Langkah 20: Pilih jaringan untuk lalu lintas replikasi. Klik Selanjutnya untuk melanjutkan melalui wisaya. Setelah selesai, hierarki sumber daya Anda akan terlihat seperti ini: Langkah 21: Meninjau hierarki sumber Replikasi Data
Klik Selanjutnya untuk melanjutkan melalui wisaya. Setelah selesai, hierarki sumber daya Anda akan terlihat seperti ini: Langkah 21: Meninjau hierarki sumber Replikasi Data 
Membuat Hirarki Sumber Daya MySQL
Anda perlu membuat sumber daya MySQL untuk melindungi database MySQL dan membuatnya sangat tersedia antara node cluster. Pada titik ini, MySQL harus berjalan di server utama tetapi tidak berjalan di server sekunder. Dari toolbar GUI, klik Create Resource Hierarchy. Pilih Database MySQL dan klik Berikutnya. Lanjutkan melalui wizard Sumber Daya Kreasi, dengan memberikan nilai-nilai berikut.
|
Bidang |
Entri atau Catatan yang Disarankan |
| Jenis Switchback | Pilih Cerdas. |
| Server | Pilih LinuxPrimary (node cluster utama). |
| Lokasi my.cnf | Masukkan / var / lib / mysql. (Sebelumnya dalam proses konfigurasi MySQL, Anda membuat file my.cnf di direktori ini.) |
| Lokasi MySQL dapat dieksekusi | Tinggalkan sebagai default (/ usr / bin) karena Anda menggunakan instalasi / konfigurasi standar MySQL dalam contoh ini. |
| Tag basis data | Tinggalkan sebagai default. |
Klik Buat untuk menentukan hirarki sumber daya MySQL di server utama. Klik Berikutnya untuk memperluas sumber daya sistem file ke server sekunder. Di Wisaya Perluas, pilih Terima Default. Klik Selesai untuk keluar dari panduan Perpanjang. Hierarki sumber daya Anda akan terlihat seperti ini: Langkah 22: Tinjau hierarki sumber daya MySQL 
Menciptakan Ketergantungan Alamat IP MySQL
Selanjutnya, Anda akan mengonfigurasi MySQL agar bergantung pada IP virtual (192.168.197.151) sehingga alamat IP mengikuti database MySQL saat ia bergerak. Dari toolbar GUI, klik kanan sumber daya mysql. Pilih Buat Ketergantungan dari menu konteks. Di menu tarik-turun Tag Sumber Daya Anak, pilih ip-192.168.197.151. Klik Berikutnya, klik Buat Ketergantungan, lalu klik Selesai. Hirarki sumber daya Anda sekarang akan terlihat seperti ini: Langkah 23: Tinjau hirarki sumber daya MySQL IP Pada titik ini dalam evaluasi, Anda telah sepenuhnya dilindungi MySQL dan sumber daya dependen (alamat IP dan penyimpanan yang direplikasi). Uji lingkungan Anda, dan Anda siap untuk pergi. Anda dapat menemukan lebih banyak informasi dan langkah-langkah terperinci untuk setiap tahap proses evaluasi di SIOS SteelEye Protection Suite untuk Linux MySQL dengan Panduan Evaluasi Replikasi Data. Untuk mengunduh salinan evaluasi SPS untuk Linux, kunjungi situs web SIOS atau hubungi SIOS di info@us.sios.com. Tertarik untuk belajar Membuat 2-Node MySQL Cluster Tanpa Penyimpanan Bersama, inilah kisah sukses masa lalu kami dengan klien yang puas. Direproduksi dengan izin dari Linuxclustering
IP Pada titik ini dalam evaluasi, Anda telah sepenuhnya dilindungi MySQL dan sumber daya dependen (alamat IP dan penyimpanan yang direplikasi). Uji lingkungan Anda, dan Anda siap untuk pergi. Anda dapat menemukan lebih banyak informasi dan langkah-langkah terperinci untuk setiap tahap proses evaluasi di SIOS SteelEye Protection Suite untuk Linux MySQL dengan Panduan Evaluasi Replikasi Data. Untuk mengunduh salinan evaluasi SPS untuk Linux, kunjungi situs web SIOS atau hubungi SIOS di info@us.sios.com. Tertarik untuk belajar Membuat 2-Node MySQL Cluster Tanpa Penyimpanan Bersama, inilah kisah sukses masa lalu kami dengan klien yang puas. Direproduksi dengan izin dari Linuxclustering
Cara Membuat Cluster MySQL 2-Node Tanpa Penyimpanan Bersama – Bagian 1

Langkah-demi-Langkah: Cara Membuat Cluster MySQL 2-Node Tanpa Penyimpanan Bersama, Bagian 1
Keuntungan utama menjalankan cluster MySQL jelas ketersediaan tinggi (HA). Untuk mendapatkan hasil maksimal dari jenis solusi ini, Anda akan ingin menghilangkan sebanyak mungkin potensi titik kegagalan tunggal. Kearifan konvensional mengatakan bahwa Anda tidak dapat membentuk kluster tanpa beberapa jenis penyimpanan bersama, yang secara teknis mewakili satu titik kegagalan dalam arsitektur pengelompokan Anda. Namun, ada solusinya. SteelEye Protection Suite (SPS) untuk Linux memungkinkan Anda untuk menghilangkan penyimpanan sebagai satu titik kegagalan dengan menyediakan replikasi data real-time antara node cluster. Mari kita lihat skenario tipikal: Anda membentuk kluster yang memanfaatkan penyimpanan lokal, yang direplikasi untuk melindungi database MySQL.
Untuk membuat membuat 2-Node MySQL Cluster Tanpa Penyimpanan Bersama, kami akan menganggap Anda bekerja dengan salinan evaluasi SPS di lingkungan lab. Kami juga menganggap Anda telah mengonfirmasi bahwa server primer dan sekunder dan jaringan semuanya memenuhi persyaratan untuk menjalankan jenis penyiapan ini. (Anda dapat menemukan rincian persyaratan ini di SIOS SteelEye Protection Suite untuk Linux MySQL dengan Panduan Evaluasi Replikasi Data.)
Langkah pertama untuk membuat Cluster MySQL 2-Node Tanpa Penyimpanan Bersama
Sebelum Anda mulai menyiapkan kluster Anda, Anda harus mengonfigurasi penyimpanan. Data yang ingin Anda tirukan harus berada pada sistem file terpisah atau volume logis. Perlu diingat bahwa ukuran disk target, apakah Anda menggunakan partisi atau volume logis, harus sama dengan atau lebih besar dari sumbernya. Dalam contoh ini, kami menganggap bahwa Anda menggunakan partisi disk. (Namun, LVM juga didukung sepenuhnya.) Pertama, partisi penyimpanan lokal untuk digunakan dengan SteelEye DataKeeper. Pada server utama, identifikasikan partisi disk yang gratis dan tidak terpakai untuk digunakan sebagai repositori MySQL atau buat partisi baru. Gunakan utilitas fdisk untuk mempartisi disk, kemudian format partisi dan pasang sementara di / mnt. Pindahkan semua data yang ada dari / var / lib / mysql / ke dalam partisi disk baru ini (dengan asumsi konfigurasi default MySQL). Lepas dan pasang kembali partisi di / var / lib / mysql. Anda tidak perlu menambahkan partisi ini ke / etc / fstab, karena akan dipasang secara otomatis oleh SPS. Di server sekunder, konfigurasikan disk seperti yang Anda lakukan di server utama.
Memasang MSQL
Selanjutnya Anda akan berurusan dengan MySQL. Pada server utama, instal paket mysql dan mysql-server RPM (jika mereka belum ada di sistem) dan terapkan dependensi yang diperlukan. Verifikasi bahwa partisi disk lokal Anda masih terpasang di / var / lib / mysql. Jika perlu, inisialisasi database contoh MySQL. Pastikan bahwa semua file dalam direktori data MySQL Anda (/ var / lib / mysql) memiliki izin dan kepemilikan yang benar, dan kemudian secara manual memulai daemon MySQL dari baris perintah. (Catatan: Jangan memulai MySQL melalui perintah layanan atau skrip /etc/init.d/.) Terhubung dengan klien mysql untuk memverifikasi bahwa MySQL sedang berjalan. Perbarui dan verifikasi kata sandi root untuk konfigurasi MySQL Anda. Kemudian buat file konfigurasi MySQL, seperti file contoh yang ditampilkan di sini: ———- # cat /var/lib/mysql/my.cnf [mysqld] datadir = / var / lib / mysql socket = / var / lib / mysql /mysql.sock pid-file = / var / lib / mysql / mysqld.pid user = root port = 3306 # Default untuk menggunakan format kata sandi lama untuk kompatibilitas dengan klien mysql 3.x # (yang menggunakan paket kompatibilitas mysqlclient10). old_passwords = 1 # Menonaktifkan tautan simbolik direkomendasikan untuk mencegah berbagai macam risiko keamanan; # untuk melakukannya, hapus tanda komentar baris ini: # symbolic-links = 0 [mysqld_safe] log-error = / var / log / mysqld.log pid-file = / var / run / mysqld / mysqld.pid [client] user = root password = SteelEye ———- Dalam contoh ini, kita menempatkan file ini di direktori yang sama yang nantinya akan kita tiru (/var/lib/mysql/my.cnf). Hapus file konfigurasi MySQL asli (di / etc). Pada server sekunder, instal paket mysql dan mysql-server RPM jika perlu, terapkan setiap dependensi, dan pastikan bahwa semua file dalam direktori data MySQL Anda (/ var / lib / mysql) memiliki izin dan kepemilikan yang benar.
Menginstal SPS untuk Linux
Selanjutnya, instal SPS untuk Linux. Untuk kemudahan instalasi, SIOS menyediakan skrip instalasi terpadu (disebut "setup") untuk SPS untuk Linux. Petunjuk tentang cara mendapatkan perangkat lunak ini adalah melalui email yang dilengkapi dengan kunci lisensi evaluasi SPS untuk Linux. Unduh perangkat lunak dan kunci lisensi evaluasi pada server primer dan sekunder. Pada setiap server, jalankan skrip pemasang, yang akan menginstal beberapa RPM prasyarat, perangkat lunak pengelompokan inti, dan setiap ARK opsional yang diperlukan. Dalam hal ini, Anda akan ingin menginstal MySQL ARK (steeleye-lkSQL) dan DataKeeper (yaitu, Data Replika) ARK (steeleye-lkDR). Terapkan kunci lisensi melalui perintah / opt / LifeKeeper / bin / lkkeyins dan mulai SPS untuk Linux melalui skrip awalnya, / opt / LifeKeeper / lkstart. Pada titik ini Anda telah menginstal SPS, berlisensi, dan berjalan di kedua node Anda, dan disk Anda dan database MySQL yang ingin Anda lindungi dikonfigurasikan. Di pos berikutnya, kita akan melihat langkah-langkah yang tersisa dalam proses pengelompokan tanpa-berbagi: Buat yang berikut
- Jalur komunikasi (Comm), yaitu detak jantung, antara server utama dan target
- Sumber daya IP
- Cermin dan meluncurkan replikasi data
- Sumber daya database MySQL
- MySQL alamat IP ketergantungan
Tertarik untuk mengetahui cara membuat 2-Node MySQL Cluster Tanpa Penyimpanan Bersama untuk proyek Anda, mengobrol dengan kami atau membaca kisah sukses kami. Direproduksi dengan izin dari Linuxclustering