| Mei 8, 2019 |
Pertimbangan Penyimpanan Untuk Menjalankan SQL Server Di AzurePertimbangan Penyimpanan Untuk Menjalankan SQL Server Di AzureMenyebarkan SQL Server di Azure, atau platform Cloud apa pun? Alih-alih hanya menyediakan penyimpanan seperti yang Anda lakukan untuk penyebaran di tempat Anda selama bertahun-tahun, mempertimbangkan penyimpanan di Azure tidak persis seperti penyimpanan yang mungkin Anda miliki akses ke di tempat. Beberapa "praktik terbaik" tradisional mungkin berakhir dengan biaya tambahan uang dan memberi Anda kinerja yang kurang optimal. Namun, sambil tidak memberikan Anda manfaat yang diinginkan. Banyak hal yang akan saya bahas juga dijelaskan dalam Pedoman Kinerja untuk Azure di SQL Server Virtual Machines. Jenis DiskSaya di sini bukan untuk memberi tahu Anda bahwa Anda harus menggunakan UltraSSD, Penyimpanan Premium, atau jenis disk apa pun lainnya. Anda hanya perlu menyadari bahwa Anda memiliki opsi, dan apa yang dibawa oleh masing-masing tipe disk ke tabel. Tentu saja, seperti hal lain di cloud, semakin banyak uang yang Anda habiskan, semakin banyak kekuatan, kecepatan, throughput, dll., Yang akan Anda raih. Caranya adalah menemukan konfigurasi optimal yang sesuai dengan pertimbangan penyimpanan Anda sehingga Anda menghabiskan cukup banyak untuk mencapai hasil yang diinginkan. Ukuran Tidak PeduliSeperti banyak hal di awan, spesifikasi tertentu diikat bersama. Untuk server jika Anda menginginkan lebih banyak RAM, Anda sering mendapatkan lebih banyak CPU, bahkan jika Anda TIDAK MEMBUTUHKAN lebih banyak CPU. Untuk penyimpanan, IOPS, throughput, dan ukuran semuanya terikat bersama. Jika Anda ingin lebih banyak IOPS, Anda memerlukan disk yang lebih besar. Jika Anda membutuhkan lebih banyak ruang, Anda juga mendapatkan lebih banyak IOPS. Tentu saja Anda dapat melompat di antara kelas penyimpanan untuk menghindari hal itu sampai batas tertentu, tetapi tetap berlaku bahwa jika Anda membutuhkan lebih banyak IOPS, Anda juga mendapatkan lebih banyak ruang pada salah satu dari jenis penyimpanan yang berbeda. Ukuran instance mesin virtual Anda juga penting. Terlepas dari konfigurasi penyimpanan apa yang akhirnya Anda gunakan, throughput keseluruhan akan dibatasi pada ukuran instance apa pun yang memungkinkan. Jadi sekali lagi, Anda mungkin perlu membayar lebih banyak RAM dan CPU daripada yang Anda butuhkan, hanya untuk mencapai kinerja penyimpanan yang Anda inginkan. Pastikan Anda memahami apa ukuran instance Anda dapat mendukung dalam hal throughput IOPS dan MBps maks. Banyak kali ukuran instance akan berubah menjadi hambatan dalam masalah kinerja penyimpanan yang dirasakan di Azure. Gunakan Raid 0RAID 0 secara tradisional rel ketiga dari opsi konfigurasi penyimpanan. Meskipun memberikan kombinasi terbaik dari kinerja dan pemanfaatan penyimpanan dari setiap opsi RAID, ia melakukannya dengan risiko kegagalan besar. Seluruh set strip gagal jika hanya satu disk dalam set strip RAID 0 gagal. Dengan demikian, secara tradisional RAID 0 hanya digunakan dalam skenario di mana kehilangan data dapat diterima dan kinerja tinggi diinginkan. Namun, dalam perangkat lunak Azure, RAID 0 diinginkan dan bahkan direkomendasikan dalam banyak situasi. Bagaimana kita bisa lolos dengan RAID 0 di Azure? Jawabannya mudah. Setiap disk yang Anda tampilkan di mesin virtual Azure sudah memiliki tiga redundansi di backend. Berarti Anda harus mengalami beberapa kegagalan sebelum Anda kehilangan set strip Anda. Dengan menggunakan RAID 0, Anda dapat menggabungkan beberapa disk. Kinerja keseluruhan set strip gabungan akan meningkat sebesar 100% untuk setiap disk tambahan yang Anda tambahkan ke set strip. Jadi misalnya, Anda memiliki persyaratan 10.000 IOPS, Anda mungkin berpikir bahwa Anda memerlukan UltraSSD karena Premium Storage mencapai 7,500 IOPS dengan P50. Namun, dengan meletakkan dua P50 dalam RAID 0, Anda sekarang memiliki potensi untuk mencapai hingga 15.000 IOPS. Itu dengan asumsi Anda menjalankan Standard_F16s_v2 atau ukuran instance yang sama besar yang mendukung banyak IOPS. Di Windows 2012 dan yang lebih baru, RAID 0 dicapai dengan menciptakan Ruang Penyimpanan Sederhana. Di Windows Server 2008 R2, Anda dapat menggunakan Disk Dinamis untuk membuat Volume Bergaris RAID 0. Hanya kata-kata peringatan. Jika Anda akan menggunakan Ruang Penyimpanan lokal dan juga mengkonfigurasi Grup Ketersediaan atau Mesin Virtual Cluster SANless dengan DataKeeper, yang terbaik adalah mengkonfigurasi penyimpanan Anda SEBELUM Anda membuat sebuah cluster. Hanya pengingat. Anda hanya memiliki sekitar dua bulan lagi untuk memindahkan instance SQL Server 2008 R2 Anda ke Azure. Lihat posting saya tentang cara menggunakan SQL Server 2008 R2 FCI di Azure untuk memastikan ketersediaan tinggi. Jangan repot-repot memisahkan Log dan file dataSecara tradisional log dan file data akan berada di disk fisik yang berbeda. File log cenderung memiliki banyak aktivitas tulis dan file data cenderung memiliki lebih banyak aktivitas membaca. Oleh karena itu terkadang penyimpanan akan dioptimalkan berdasarkan karakteristik tersebut. Itu juga diinginkan untuk menyimpan log dan file data pada disk yang berbeda untuk tujuan pemulihan. Jika Anda harus kehilangan satu atau yang lain, dengan strategi cadangan yang tepat, Anda dapat memulihkan database Anda tanpa kehilangan data. Dengan penyimpanan berbasis cloud, kemungkinan kehilangan hanya satu volume sangat rendah. Sekarang Anda berpikir tentang pertimbangan penyimpanan. Jika kebetulan Anda kehilangan penyimpanan, kemungkinan seluruh cluster penyimpanan Anda, bersama dengan tiga cadangan, pergi untuk makan siang. Jadi, meskipun mungkin merasa benar untuk meletakkan log di E: log dan data dalam F: data, Anda benar-benar merugikan diri sendiri. Misalnya, Anda menyediakan P20 untuk log dan P20 untuk data. Setiap volume akan berukuran 512 GiB dan ditutup pada 2.300 IOPS. Bayangkan saja, Anda mungkin tidak perlu semua ukuran itu untuk file log. Tapi itu mungkin tidak memberi Anda banyak ruang untuk tumbuh untuk file data Anda. Pada akhirnya akan membutuhkan pindah ke P30 lebih mahal hanya untuk ruang ekstra. Tidakkah akan jauh lebih baik untuk memisahkan kedua volume itu menjadi volume 1 TB yang bagus yang mendukung 4.600 IOPS? Dengan melakukan itu, baik file log dan data dapat memanfaatkan peningkatan IOPS. Dan, Anda juga baru saja mengoptimalkan pemanfaatan penyimpanan Anda dan mengurangi biaya penyimpanan cloud Anda dengan menunda perpindahan ke disk P30 untuk file data Anda. Hal yang sama juga berlaku pada file dan filegroup. Benar-benar berpikir keras tentang apa yang Anda lakukan. Apakah itu masih masuk akal setelah Anda pindah ke cloud. Apa yang masuk akal mungkin berlawanan dengan apa yang telah Anda lakukan di masa lalu. Jika ragu, ikuti aturan KISS, Keep It Simple Stupid! Keindahan cloud adalah Anda selalu dapat menambahkan lebih banyak penyimpanan, menambah ukuran instance, atau melakukan apa pun untuk mengoptimalkan kinerja vs. biaya. Apa yang Harus Dilakukan Tentang TempDBGunakan SSD lokal, alias, drive D:. Drive D akan menjadi lokasi terbaik untuk tempdb Anda. Karena ini adalah drive lokal, data dianggap "sementara". Berarti bisa hilang jika server dipindahkan, reboot, dll. Tidak apa-apa. Tempdb diciptakan kembali setiap kali SQL dimulai. SSD lokal akan menjadi cepat dan memiliki latensi rendah. Tetapi karena ini bersifat lokal, baca dan tulis tidak berkontribusi pada batas IOPS penyimpanan keseluruhan dari ukuran instance. Jadi secara efektif, IOPS GRATIS! Kenapa tidak mengambil keuntungan? Jika Anda sedang membangun SANless SQL Server FCI dengan SIOS DataKeeper, pastikan untuk membuat sumber daya volume yang tidak dicerminkan dari drive D. Dengan cara ini Anda tidak perlu meniru TempDB. Poin Gunung Menjadi UsangMount Points biasanya digunakan dalam konfigurasi SQL Server FCI ketika beberapa contoh SQL Server diinstal pada Windows Cluster yang sama. Ini mengurangi biaya keseluruhan lisensi SQL Server. Ini dapat membantu menghemat biaya dengan mendorong pemanfaatan server yang lebih tinggi. Seperti yang kita bahas di masa lalu, biasanya mungkin ada lima atau lebih drive yang terkait dengan setiap instance SQL Server. Jika masing-masing drive tersebut harus menggunakan huruf drive, Anda akan kehabisan huruf hanya dalam tiga hingga empat contoh. Jadi, alih-alih memberikan setiap drive huruf, mount point digunakan sehingga setiap instance hanya bisa dilayani oleh huruf drive tunggal, root drive. Drive root memiliki titik pemasangan yang memetakan untuk memisahkan disk fisik yang tidak memiliki huruf drive. Namun, seperti yang kita diskusikan di atas, konsep menggunakan sekelompok disk individu benar-benar tidak masuk akal di cloud. Karenanya poin mount menjadi usang di awan. Sebagai gantinya, buatlah RAID 0 stripe seperti yang dijelaskan. Setiap contoh berkerumun SQL Server hanya akan memiliki volume sendiri yang dioptimalkan untuk ruang, kinerja, dan biaya. Ini menyelesaikan masalah kehabisan huruf drive. Selain itu, memberi Anda pemanfaatan dan kinerja penyimpanan yang jauh lebih baik, sekaligus juga mengurangi biaya penyimpanan cloud Anda. KesimpulanPosting ini dimaksudkan sebagai titik awal, bukan panduan yang pasti. Poin utama dari posting ini adalah membuat Anda berpikir secara berbeda tentang pertimbangan cloud dan penyimpanan terkait dengan menjalankan SQL Server di Azure. Jangan hanya mengambil apa yang Anda lakukan di tempat dan membuatnya kembali di cloud. Itu hampir selalu menghasilkan kinerja yang kurang optimal dan tagihan penyimpanan yang jauh lebih besar dari yang diperlukan. Diproduksi ulang dengan izin dari Clusteringformeremortals.com |
| April 24, 2019 |
Mengkonfigurasi contoh SQL Server 2008 R2 Failover Cluster pada Windows Server 2008 R2 di AzureLangkah-demi-Langkah: Cara Mengkonfigurasi Instance Failover Cluster SQL Server 2008 R2 Pada Windows Server 2008 R2 Di AzureIntroPada 9 Juli 2019, dukungan untuk SQL Server 2008 dan 2008 R2 akan berakhir. Itu berarti akhir dari pembaruan keamanan reguler. Namun, jika Anda memindahkan instance SQL Server ke Azure, Microsoft akan memberi Anda Pembaruan Keamanan Diperpanjang tiga tahun tanpa biaya tambahan. Jika saat ini Anda menjalankan SQL Server 2008/2008 R2 dan Anda tidak dapat memperbarui ke versi SQL Server yang lebih lama sebelum batas waktu 9 Juli, Anda akan ingin mengambil keuntungan dari penawaran ini daripada menjalankan risiko menghadapi kerentanan keamanan di masa depan. . Contoh SQL Server yang tidak ditambal dapat menyebabkan kehilangan data, downtime atau pelanggaran data yang menghancurkan. Salah satu tantangan yang akan Anda hadapi ketika menjalankan SQL Server 2008/2008 R2 di Azure adalah memastikan ketersediaan tinggi. Di tempat Anda mungkin menjalankan contoh SQL Server Failover Cluster (FCI) untuk ketersediaan tinggi, atau mungkin Anda menjalankan SQL Server di mesin virtual dan mengandalkan VMware HA atau cluster Hyper-V untuk ketersediaan. Saat pindah ke Azure, tidak ada opsi itu yang tersedia. Downtime di Azure adalah kemungkinan yang sangat nyata sehingga Anda harus mengambil langkah-langkah untuk mengurangi. Untuk mengurangi kemungkinan downtime dan memenuhi syarat untuk Azure 99,95% atau SLA 99,99%, Anda harus memanfaatkan SIOS DataKeeper. DataKeeper mengatasi kurangnya penyimpanan bersama Azure dan memungkinkan Anda untuk membangun SQL Server FCI di Azure yang memanfaatkan penyimpanan terlampir secara lokal pada setiap instance. SIOS DataKeeper tidak hanya mendukung SQL Server 2008 R2 dan Windows Server 2008 R2 seperti yang didokumentasikan dalam panduan ini, ia mendukung semua versi Windows Server, dari 2008 R2 hingga Windows Server 2019 dan versi SQL Server apa pun dari dari SQL Server 2008 hingga SQL Server 2019 . Panduan ini akan berjalan melalui proses membuat dua simpul SQL Server 2008 R2 Failover Cluster Instance (FCI) di Azure, berjalan pada Windows Server 2008 R2. Meskipun SIOS DataKeeper juga mendukung cluster yang menjangkau Zona Ketersediaan atau Wilayah, panduan ini mengasumsikan setiap node berada di Wilayah Azure yang sama, tetapi Domain Fault yang berbeda. SIOS DataKeeper akan digunakan sebagai pengganti penyimpanan bersama yang biasanya diperlukan untuk membuat SQL Server 2008 R2 FCI. Buat contoh SQL Server pertama di AzurePanduan ini akan memanfaatkan SQL Server 2008R2SP3 pada gambar Windows Server 2008R2 yang diterbitkan di Azure Marketplace. 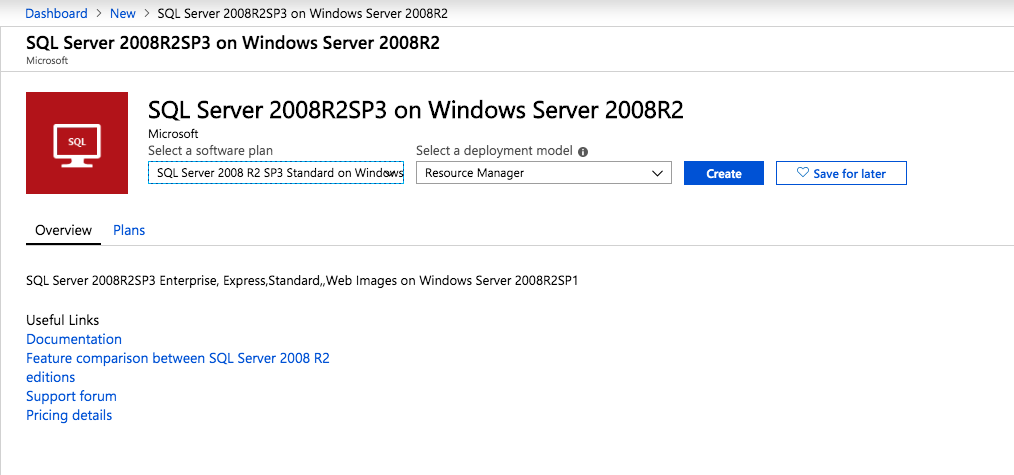 Ketika Anda memberikan instance pertama Anda harus membuat Set Ketersediaan baru. Selama proses ini pastikan untuk meningkatkan jumlah Domain Kesalahan ke 3. Ini memungkinkan dua node cluster dan saksi file berbagi masing-masing untuk berada di Domain Kesalahan mereka sendiri. 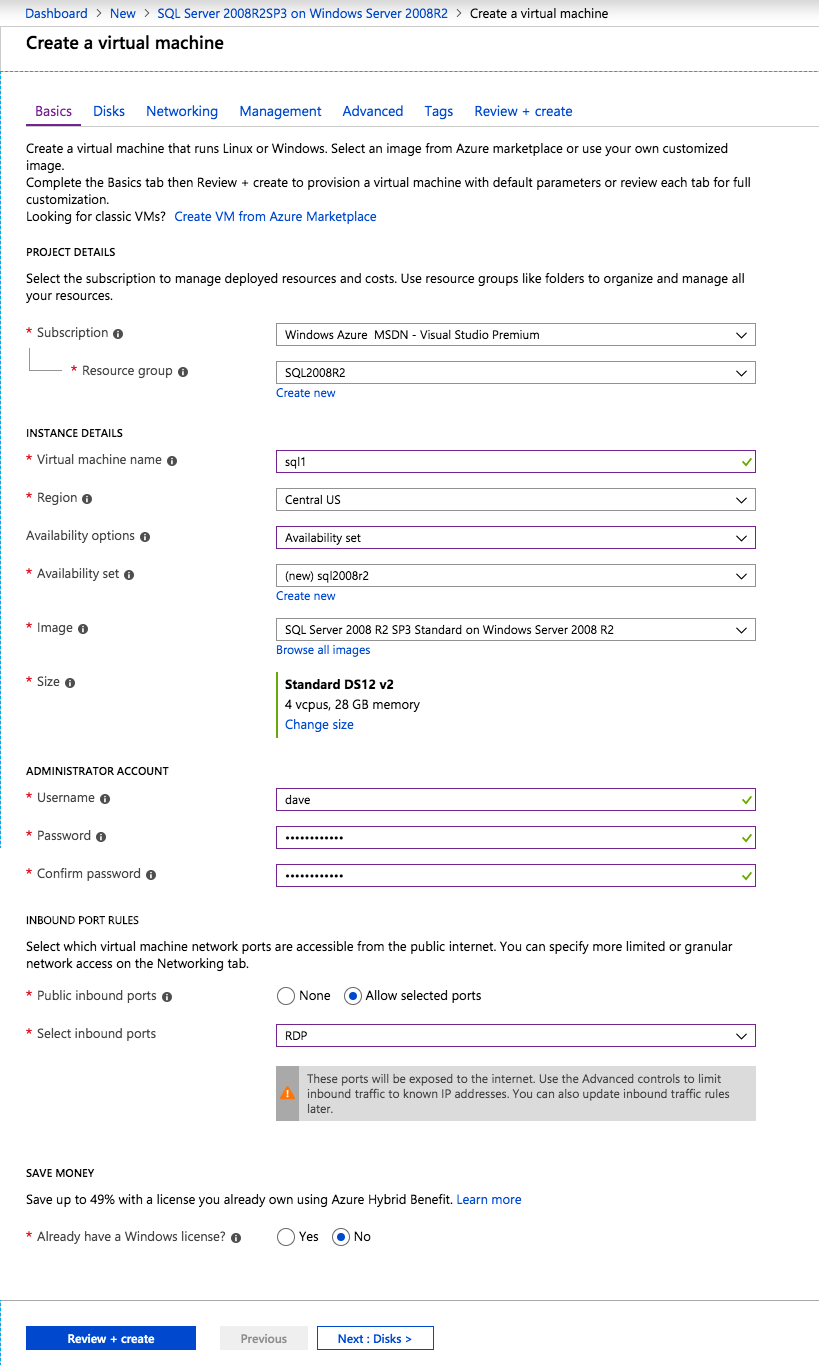 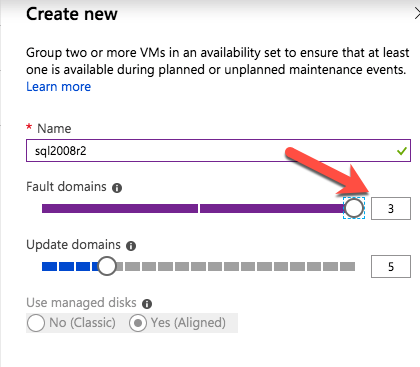  Tambahkan disk tambahan untuk setiap instance. Direkomendasikan Premium atau Ultra SSD. Nonaktifkan caching pada disk yang digunakan untuk file log SQL. Aktifkan caching hanya-baca pada disk yang digunakan untuk file data SQL. Lihat pedoman Kinerja untuk SQL Server di Mesin Virtual Azure untuk informasi tambahan tentang praktik terbaik penyimpanan. 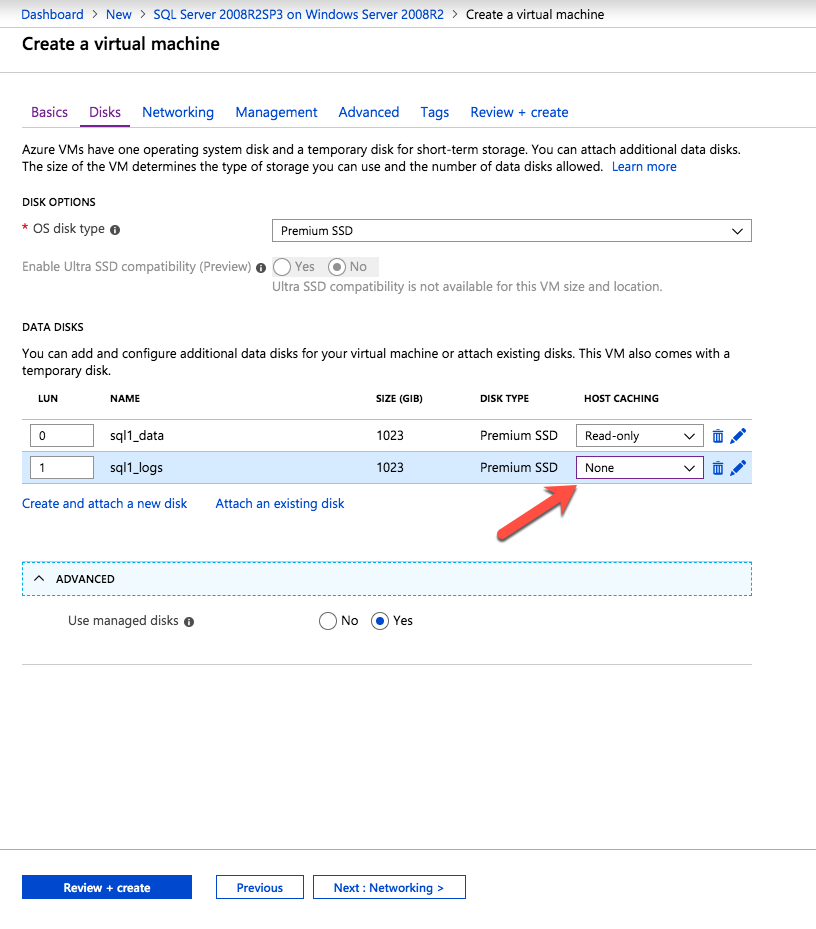 Jika Anda belum memiliki jaringan virtual yang dikonfigurasi, izinkan panduan pembuatan untuk membuat yang baru untuk Anda. 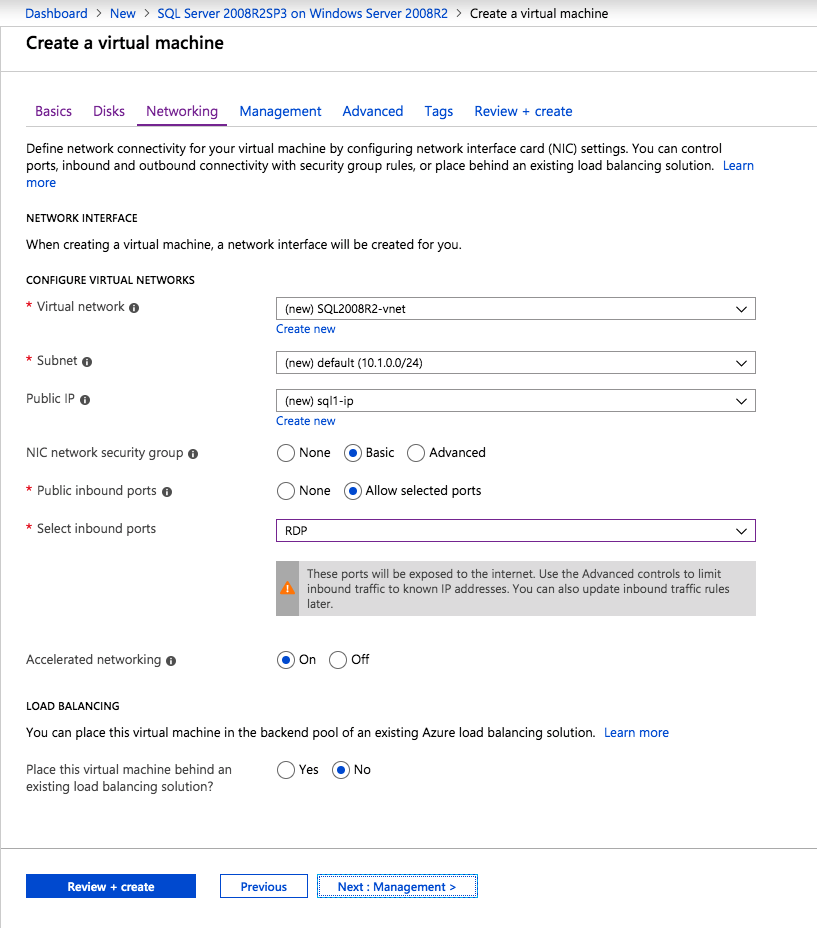 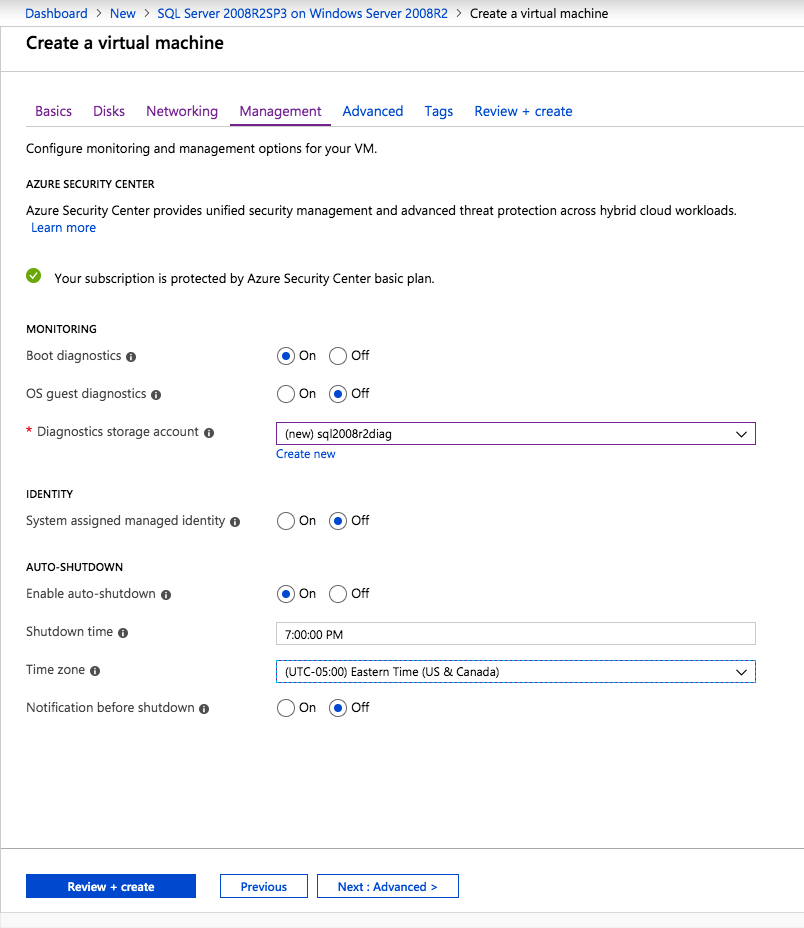 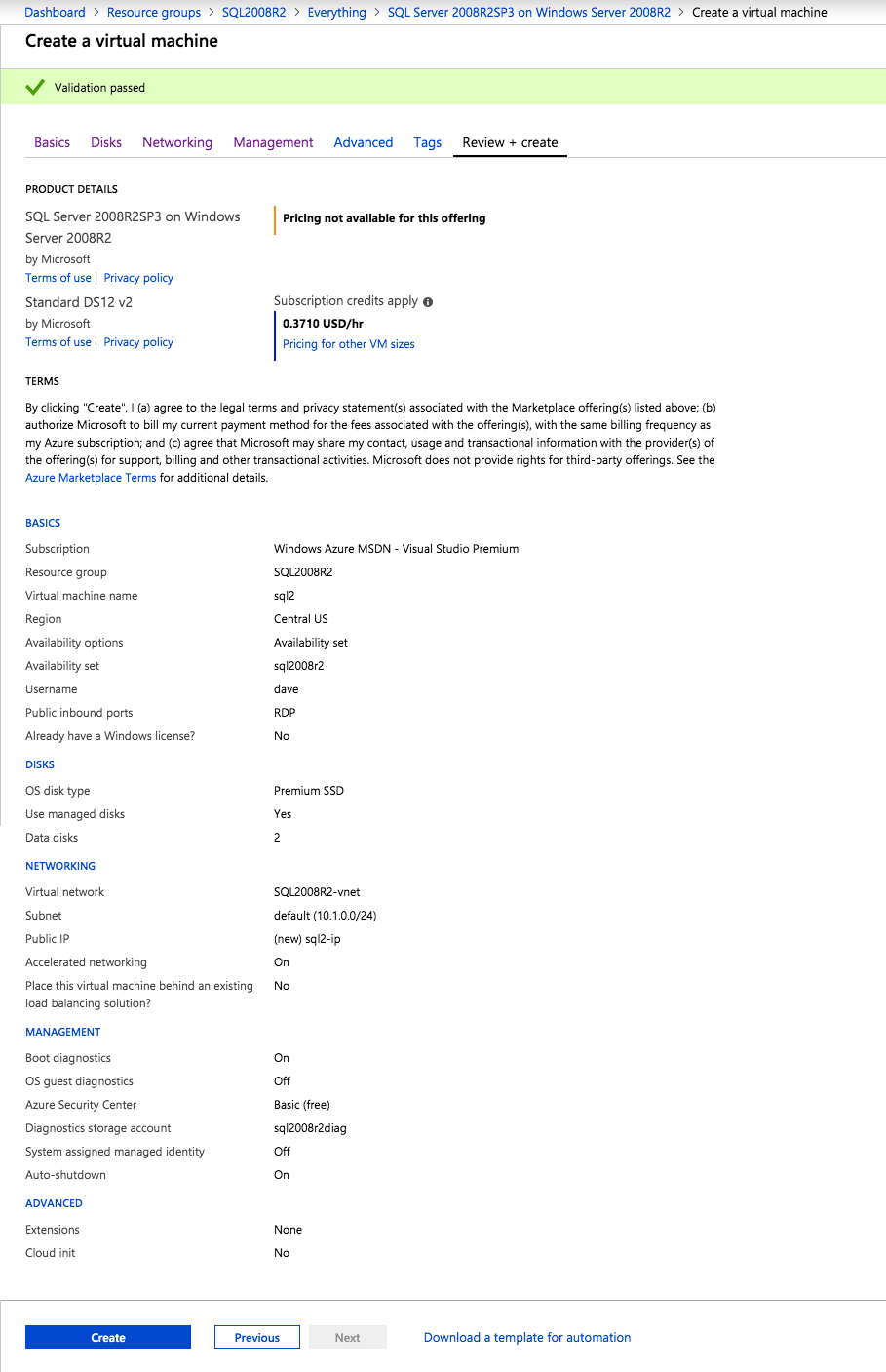 Setelah instance dibuat, masuk ke konfigurasi IP dan buat alamat IP Privat statis. Ini diperlukan untuk SIOS DataKeeper dan merupakan praktik terbaik untuk instance berkerumun. 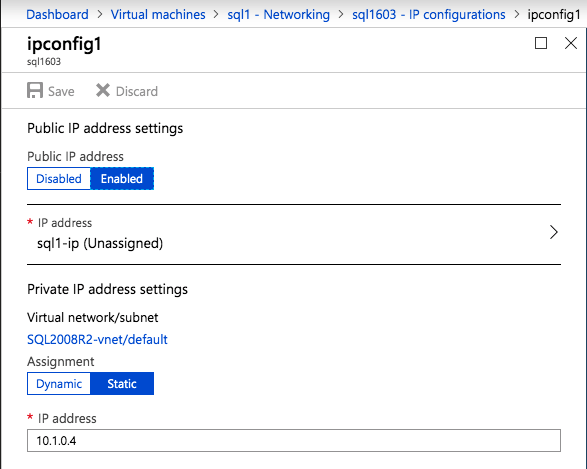 Pastikan jaringan virtual Anda dikonfigurasi untuk mengatur server DNS menjadi pengontrol Windows AD lokal. Ini untuk memastikan Anda dapat bergabung dengan domain pada langkah selanjutnya. 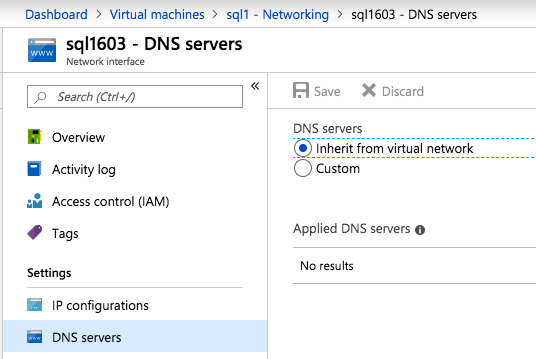 Buat Instance SQL Server Akhir Di AzureIkuti langkah-langkah yang sama seperti di atas. Kecuali pastikan untuk menempatkan instance ini di jaringan virtual yang sama dan Set Ketersediaan yang Anda buat dengan instance 1. Buat File Berbagi Saksi (FSW) InstanceAgar Windows Server Failover Cluster (WSFC) untuk bekerja secara optimal Anda diminta untuk membuat contoh Windows Server lain dan menempatkannya di Ketersediaan yang sama seperti contoh SQL Server. Dengan menempatkannya di Set Ketersediaan yang sama, Anda memastikan bahwa setiap node cluster dan FSW berada di Domain Kesalahan yang berbeda. Dengan demikian memastikan cluster Anda tetap on line seandainya seluruh Fault Domain keluar jalur. Contoh ini tidak memerlukan SQL Server. Ini bisa menjadi Windows Server sederhana karena yang perlu dilakukan hanyalah menjadi tuan rumah berbagi file sederhana. Contoh ini akan menjadi tuan rumah saksi berbagi file yang diperlukan oleh WSFC. Instance ini tidak perlu memiliki ukuran yang sama, juga tidak memerlukan disk tambahan untuk dilampirkan. Satu-satunya tujuan adalah meng-host berbagi file sederhana. Itu sebenarnya bisa digunakan untuk tujuan lain. Di lingkungan lab saya, FSW saya juga pengontrol domain saya. Hapus instalasi SQL Server 2008 R2Masing-masing dari dua contoh SQL Server yang disediakan sudah memiliki SQL Server 2008 R2 yang diinstal pada mereka. Namun, mereka diinstal sebagai contoh SQL Server mandiri, bukan contoh berkerumun. SQL Server harus dihapus dari masing-masing instance ini sebelum kita dapat menginstal instance cluster. Cara termudah untuk melakukannya adalah dengan menjalankan SQL Setup seperti yang ditunjukkan di bawah ini. Ketika Anda menjalankan setup.exe / Action-RunDiscovery Anda akan melihat semua yang sudah diinstal 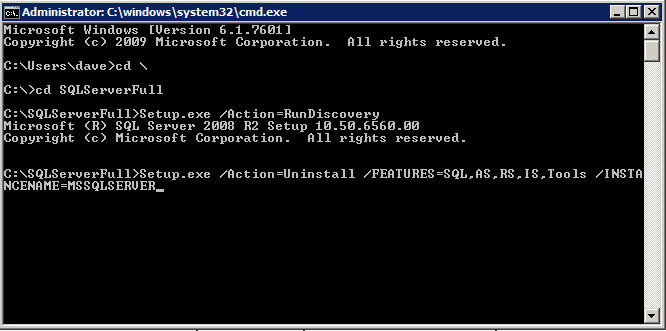  Menjalankan setup.exe / Action = Uninstall / FITUR = SQL, AS, RS, IS, Tools / INSTANCENAME = MSSQLSERVER memulai proses penghapusan instalasi 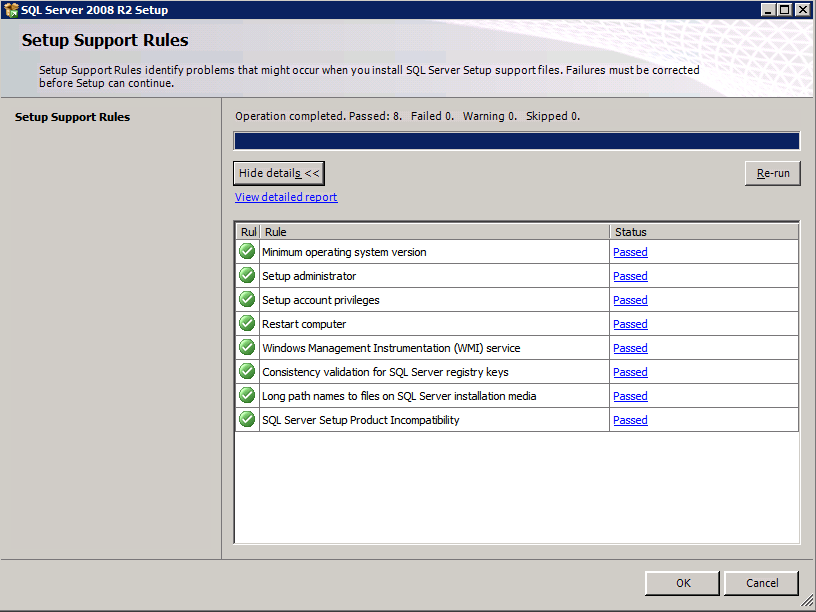  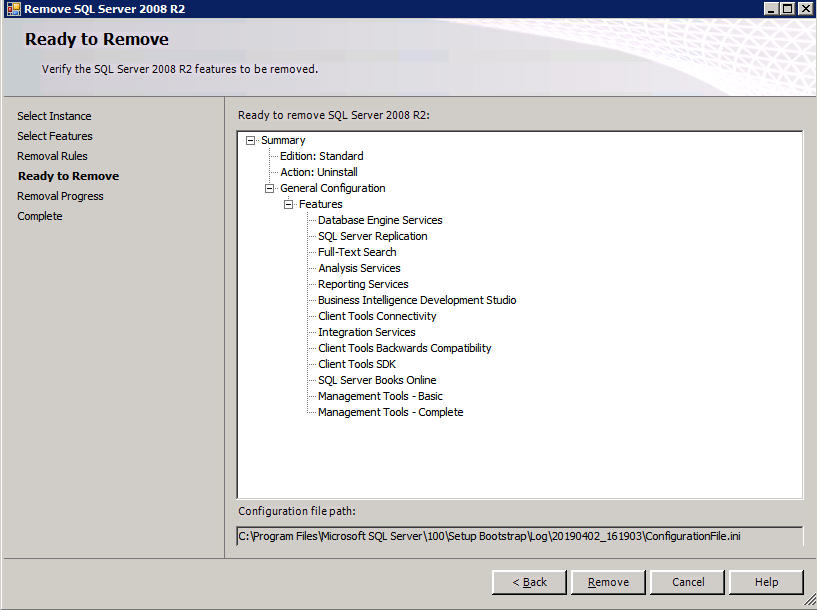 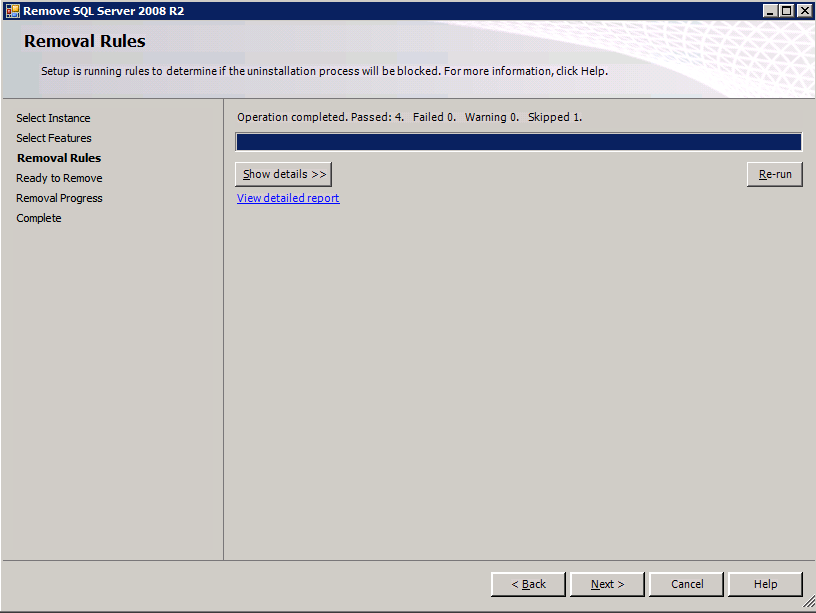 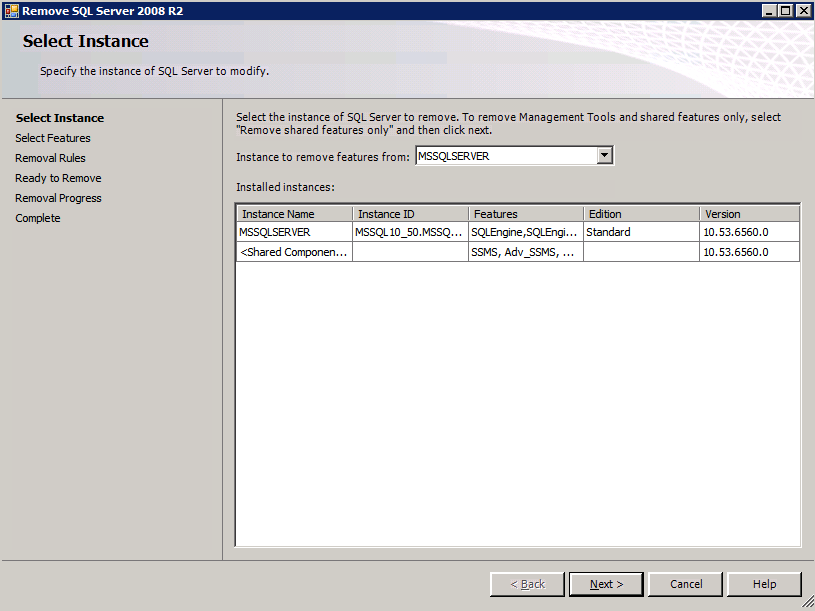 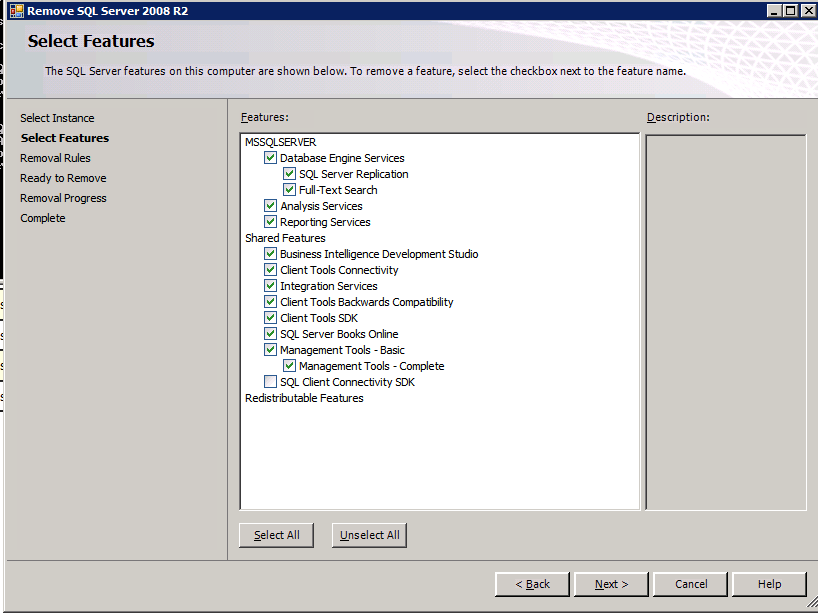 Menjalankan setup.exe / Action-RunDiscovery mengkonfirmasi penghapusan instalan selesai 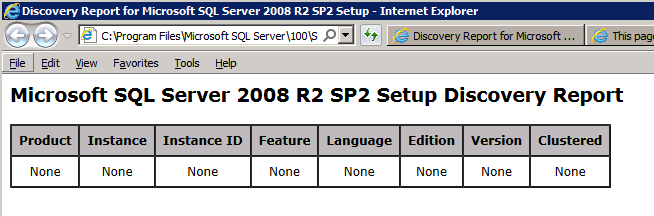 Jalankan lagi proses penghapusan instalasi ini pada instance ke-2. Tambahkan Mesin Virtual ke DomainKetiga contoh ini perlu ditambahkan ke Domain Windows. 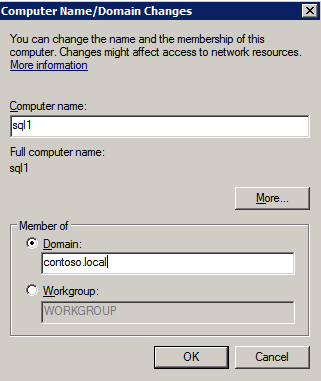 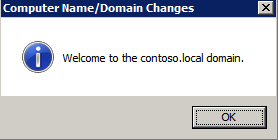 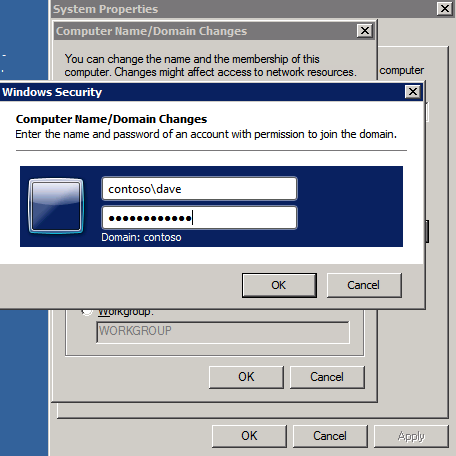 Tambahkan Fitur Clustering Windows FailoverFitur Failover Clustering perlu ditambahkan ke dua contoh SQL Server 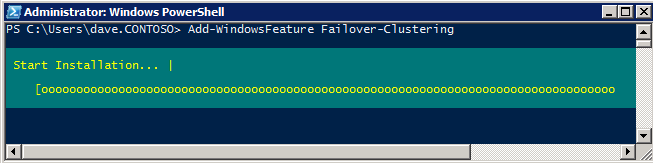 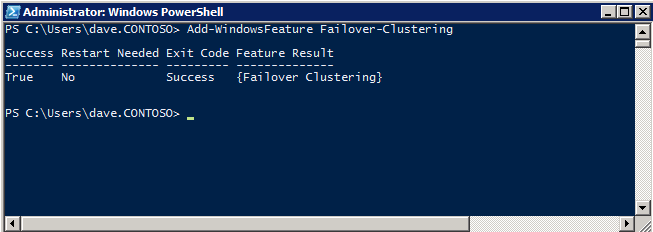 Matikan Windows FirewallDemi kesederhanaan, matikan Windows Firewall selama instalasi dan konfigurasi SQL Server FCI. Konsultasikan Praktik Terbaik Keamanan Jaringan Azure untuk saran tentang pengamanan sumber daya Azure Anda. Rincian tentang port Windows yang diperlukan dapat ditemukan di sini, port SQL Server di sini dan port SIOS DataKeeper di sini, The Internal Load Balancer yang akan kami konfigurasikan nanti juga memerlukan akses port 59999. Jadi pastikan untuk memperhitungkannya dalam konfigurasi keamanan Anda. 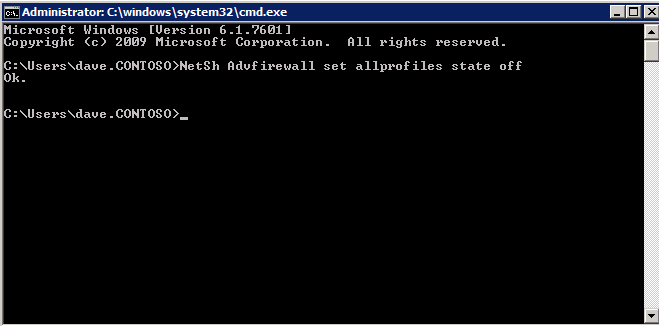 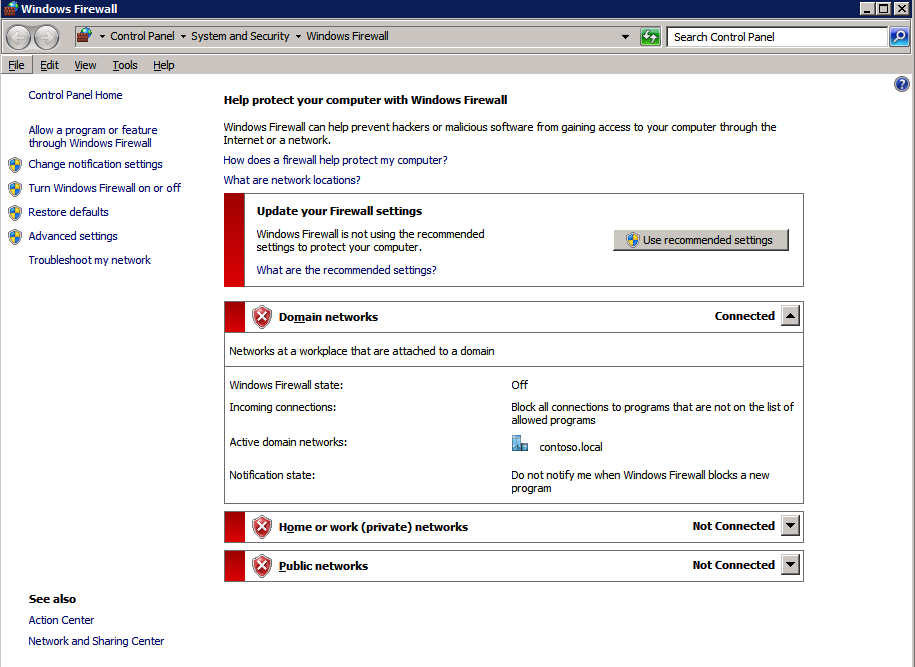 Instal Pembaruan Kenyamanan Rollup Untuk Windows Server 2008 R2 SP1Ada pembaruan kritis (kb2854082) yang diperlukan untuk mengkonfigurasi contoh Windows Server 2008 R2 di Azure. Pembaruan itu dan banyak lagi yang termasuk dalam Pembaruan Kenyamanan Rollup untuk Windows Server 2008 R2 SP1. Instal pembaruan ini di masing-masing dari dua contoh SQL Server. 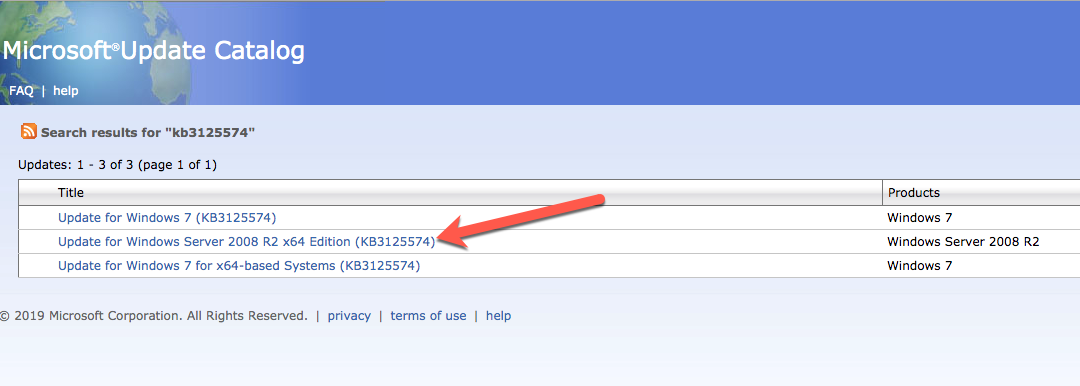   Format PenyimpananDisk tambahan yang dilampirkan ketika dua contoh SQL Server disediakan harus diformat. Lakukan hal berikut untuk setiap volume pada setiap instance. 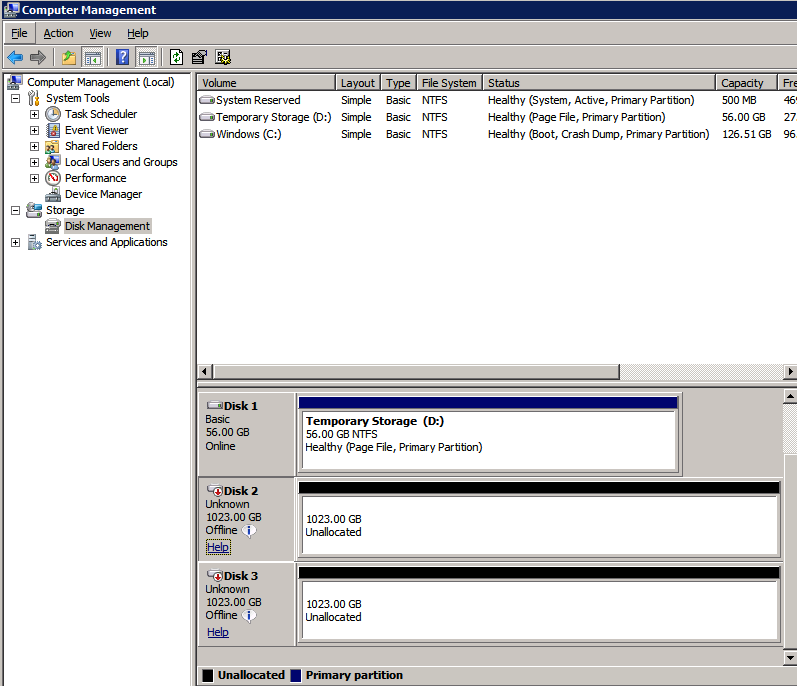 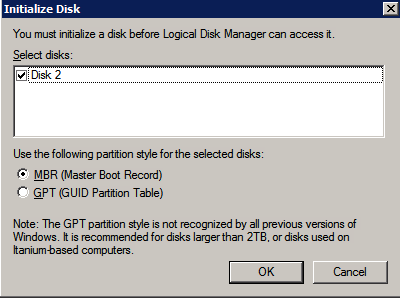  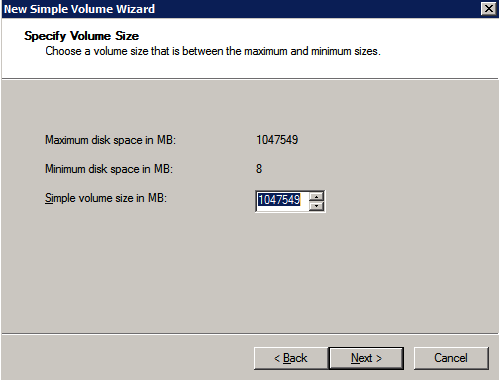 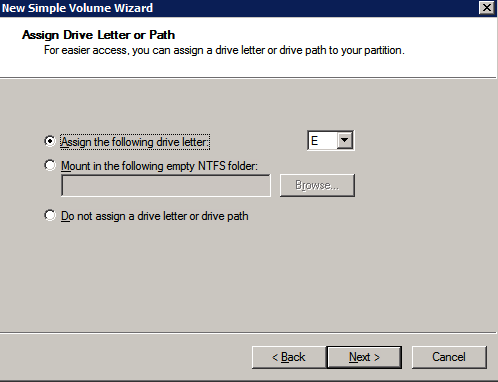 Praktik terbaik Microsoft mengatakan berikut ini … "Ukuran unit alokasi NTFS: Saat memformat disk data, disarankan agar Anda menggunakan ukuran unit alokasi 64-KB untuk data dan file log serta TempDB." 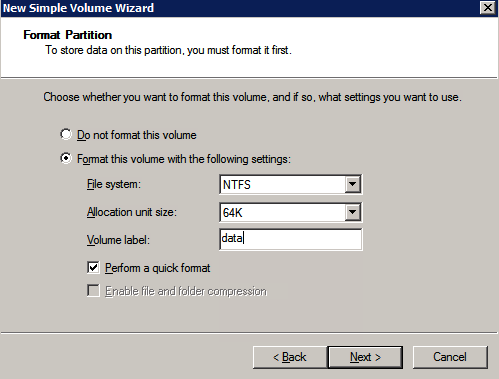 Jalankan Validasi ClusterJalankan validasi kluster untuk memastikan semuanya siap untuk dikelompokkan. 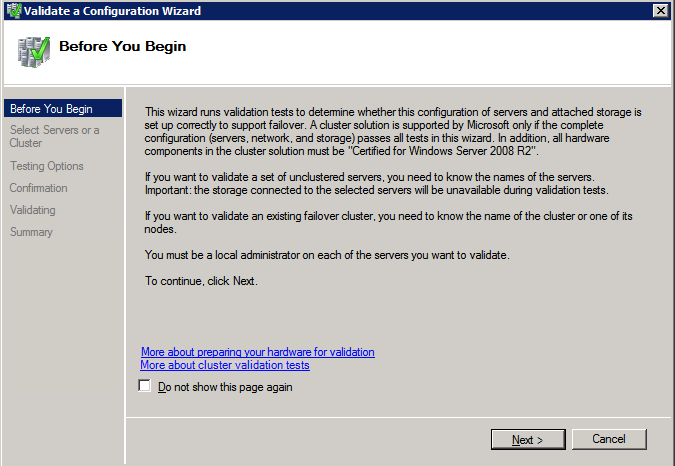 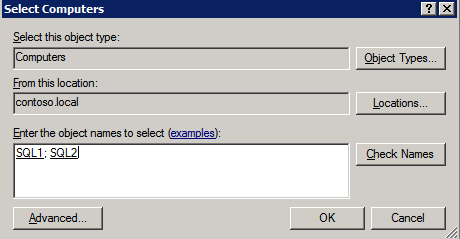 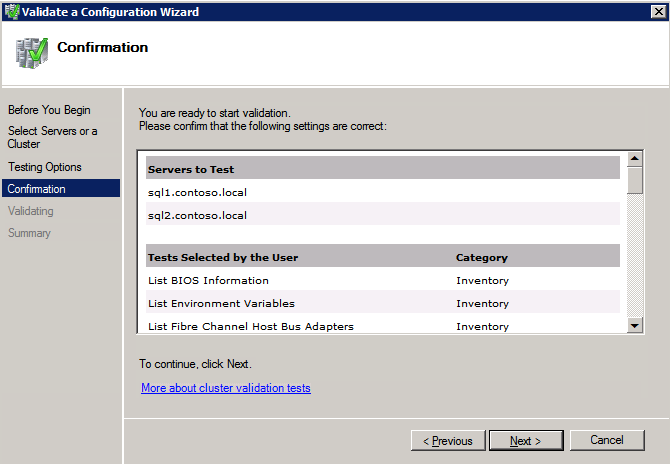 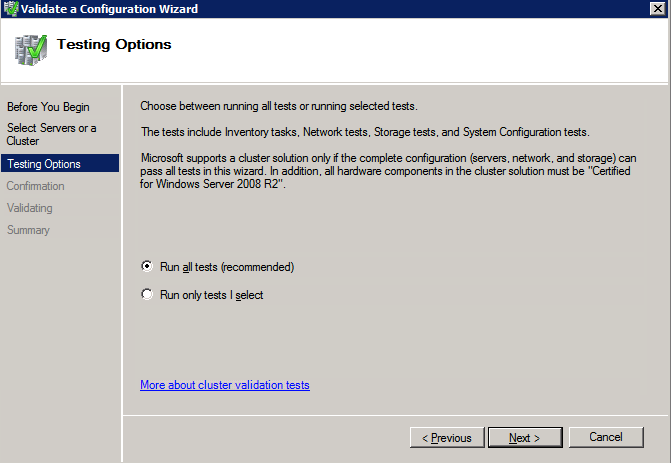 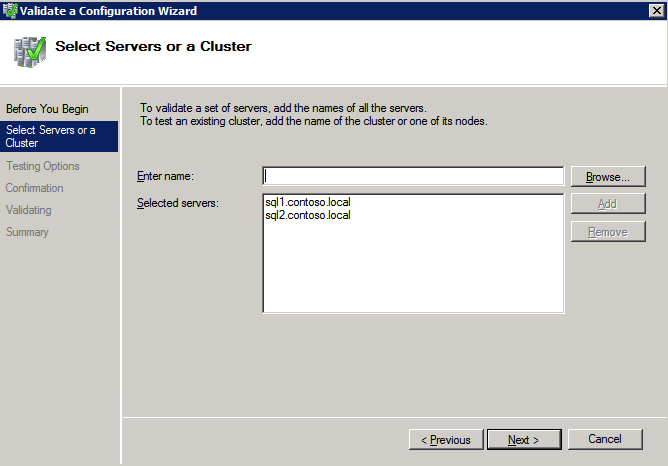 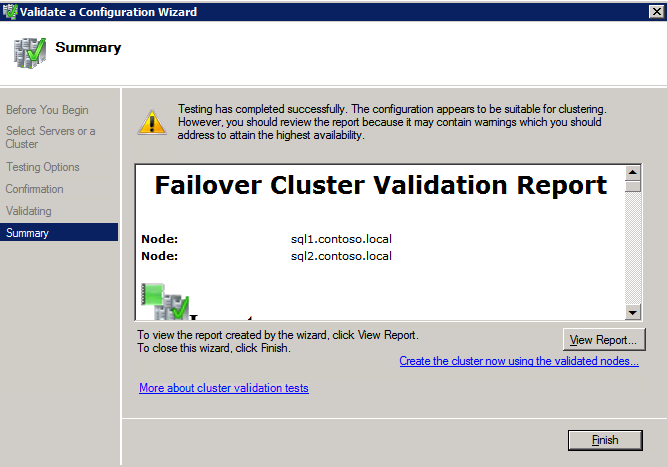 Laporan Anda akan berisi PERINGATAN tentang Penyimpanan dan Jaringan. Anda dapat mengabaikan peringatan tersebut karena kami tahu tidak ada disk bersama dan hanya ada satu koneksi jaringan antara server. Anda juga dapat menerima peringatan tentang pesanan pengikatan jaringan yang juga dapat diabaikan. Jika Anda menemukan KESALAHAN, Anda harus mengatasinya sebelum melanjutkan. 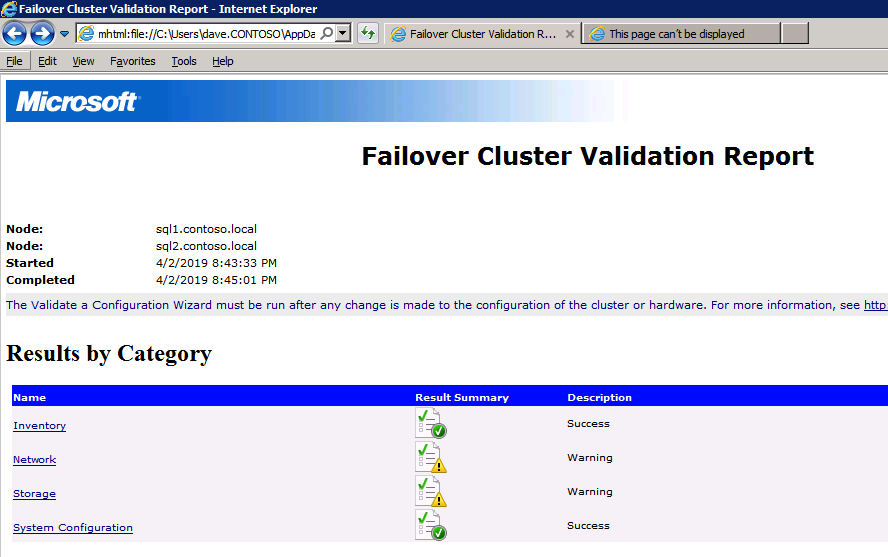 Buat ClusterPraktik terbaik untuk membuat cluster di Azure adalah dengan menggunakan Powershell seperti yang ditunjukkan di bawah ini. Powershell memungkinkan kita untuk menentukan Alamat IP Statis, sedangkan metode GUI tidak. Sayangnya, implementasi DHCP Azure tidak berfungsi dengan baik dengan Windows Server Failover Clustering. Jika Anda menggunakan metode GUI Anda akan berakhir dengan alamat IP duplikat sebagai Alamat IP Cluster. Ini bukan akhir dunia, tetapi Anda harus memperbaikinya seperti yang saya tunjukkan. Seperti yang saya katakan, metode Powershell umumnya bekerja paling baik. Namun, untuk beberapa alasan, tampaknya gagal pada Windows Server 2008 R2 seperti yang ditunjukkan di bawah ini. 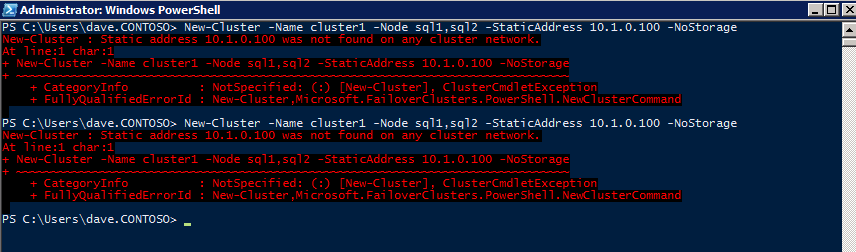 Anda dapat mencoba metode itu dan jika itu berhasil untuk Anda – hebat! Saya perlu kembali dan menyelidiki ini sedikit lebih untuk melihat apakah itu kebetulan. Opsi lain yang perlu saya jelajahi jika Powershell tidak berfungsi adalah Cluster.exe. Menjalankan cluster / create /? memberikan sintaks yang tepat untuk digunakan untuk membuat cluster dengan perintah cluster.exe yang sudah tidak digunakan lagi. Namun, jika Powershell atau Cluster.exe gagal Anda, langkah-langkah di bawah ini mengilustrasikan cara membuat cluster melalui UI Server Windows Failover Clustering, termasuk memperbaiki alamat IP duplikat yang akan ditugaskan ke cluster.   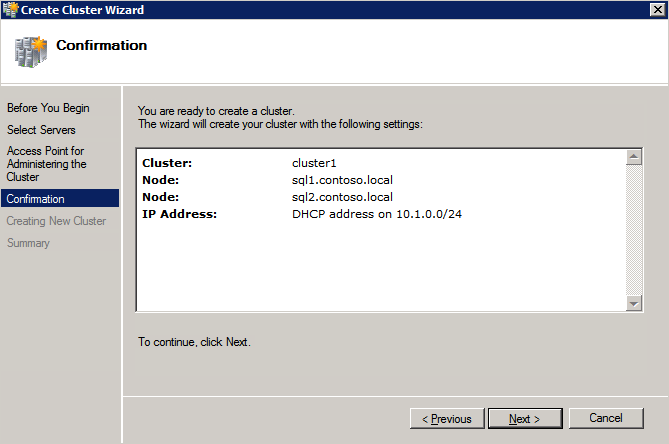 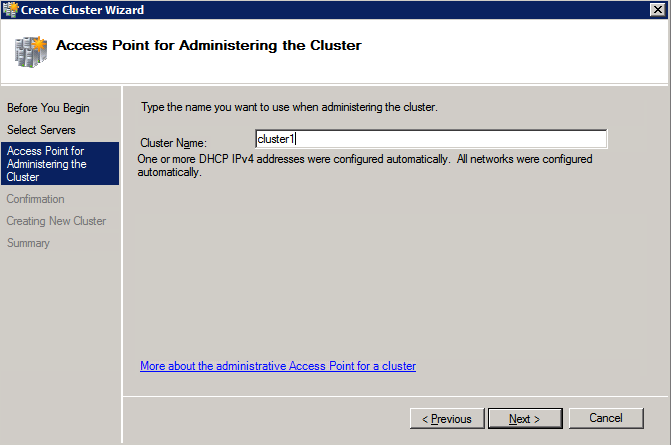 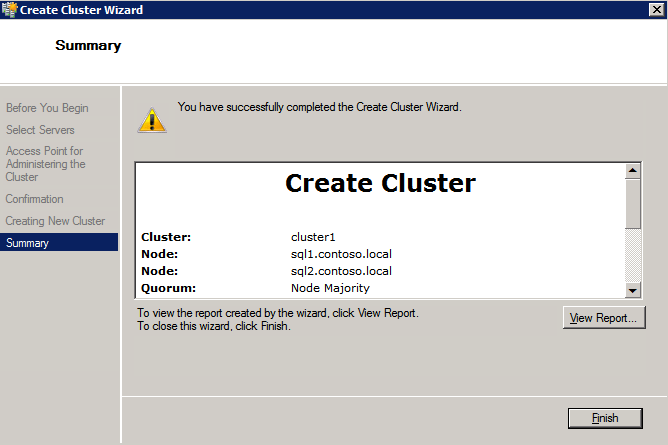 Ingat, nama yang Anda tentukan di sini hanyalah Cluster Name Object (CNO). Ini bukan nama yang akan digunakan klien SQL Anda untuk terhubung ke cluster; kita akan mendefinisikan itu selama pengaturan kluster SQL Server di langkah selanjutnya. Pada titik ini, cluster dibuat, tetapi Anda mungkin tidak dapat terhubung dengan itu dengan Windows Server Failover Clustering UI karena masalah alamat IP duplikat. Perbaiki Alamat IP GandakanSeperti yang saya sebutkan sebelumnya, jika Anda membuat cluster menggunakan GUI, Anda tidak diberi kesempatan untuk memilih alamat IP untuk cluster. Karena instance Anda dikonfigurasikan untuk menggunakan DHCP (diperlukan di Azure), GUI ingin secara otomatis memberikan Anda alamat IP menggunakan DHCP. Sayangnya, implementasi DHCP Azure tidak berfungsi seperti yang diharapkan dan cluster akan menetapkan alamat yang sama yang sudah digunakan oleh salah satu node. Meskipun cluster akan membuat dengan benar, Anda akan kesulitan menghubungkan ke cluster sampai Anda memperbaiki masalah ini. Untuk memperbaiki masalah ini, dari salah satu node jalankan perintah berikut untuk memastikan layanan Cluster dimulai pada node itu. 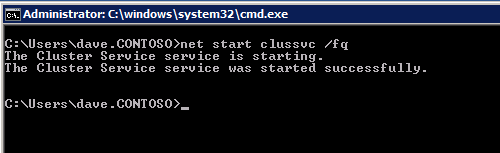 Pada simpul yang sama Anda sekarang harus dapat terhubung ke UI Clustering Windows Server Failover, di mana Anda akan melihat Alamat IP telah gagal untuk online. 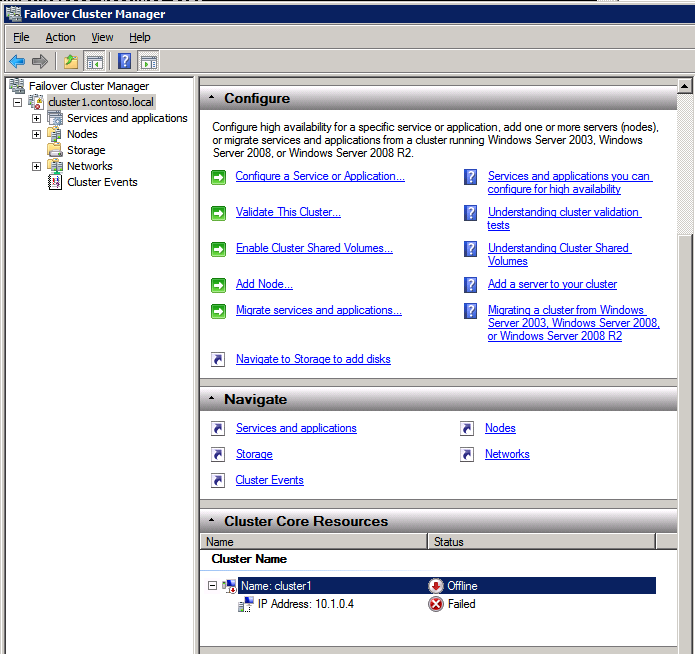 Buka properti alamat IP Cluster dan ubah dari DHCP ke Statis, dan tetapkan alamat IP yang tidak digunakan. 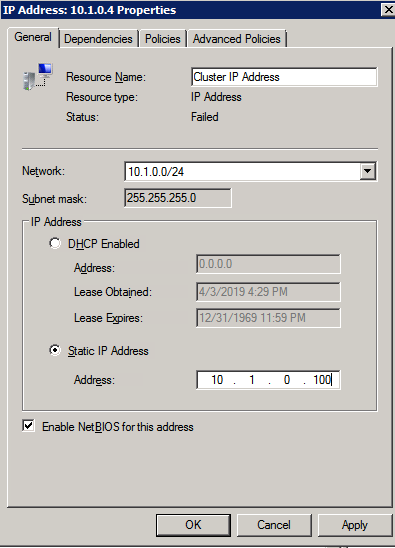 Bawa sumber Nama online 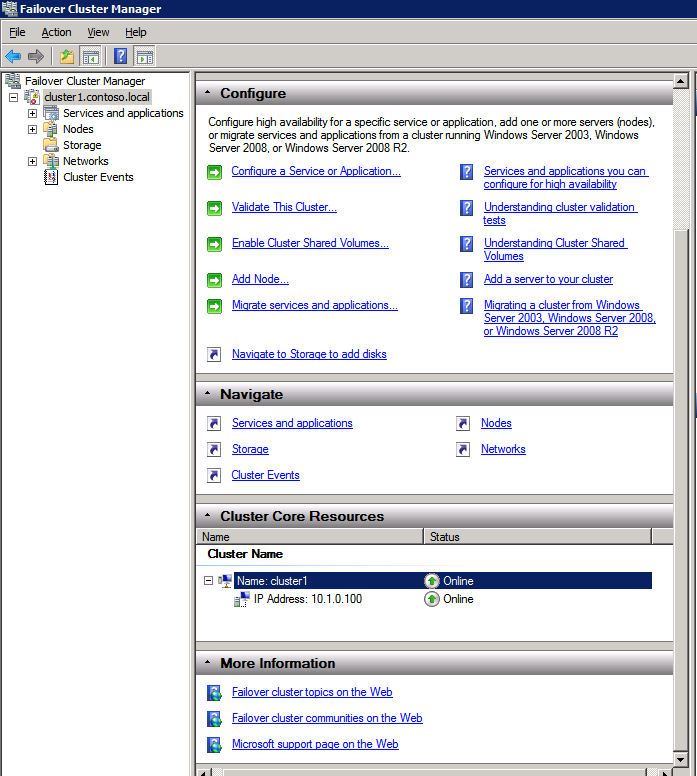 Tambahkan File Bagikan SaksiSelanjutnya kita perlu menambahkan File Share Witness. Di server ke-3 kami menyediakan sebagai FSW, buat folder dan bagikan seperti yang ditunjukkan di bawah ini. Anda harus memberikan izin baca / tulis Cluster Name Object (CNO) di tingkat Share dan Security seperti yang ditunjukkan di bawah ini. 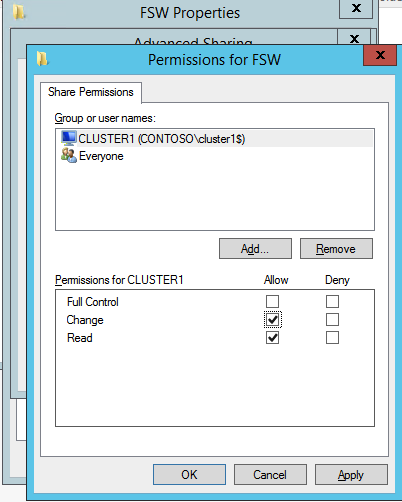 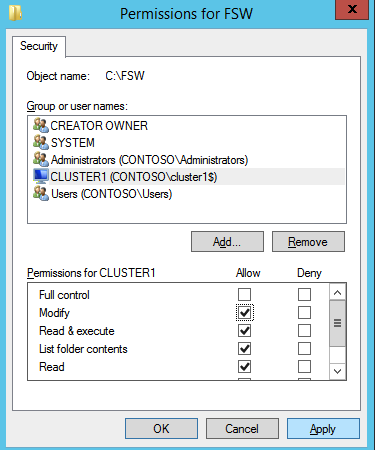 Setelah share dibuat, jalankan wizard Configure Cluster Quorum di salah satu node cluster dan ikuti langkah-langkah yang diilustrasikan di bawah ini. 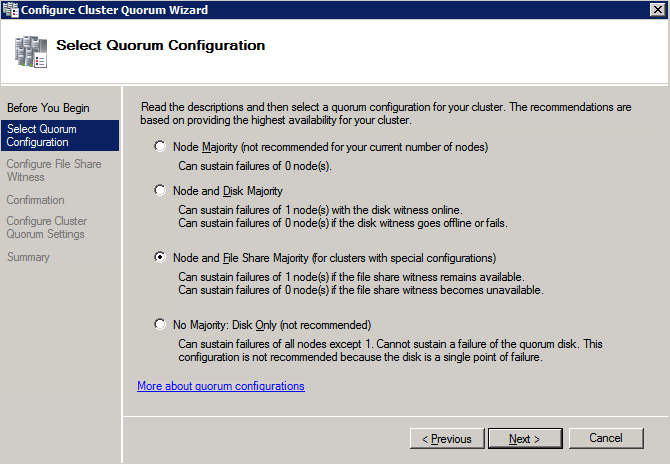 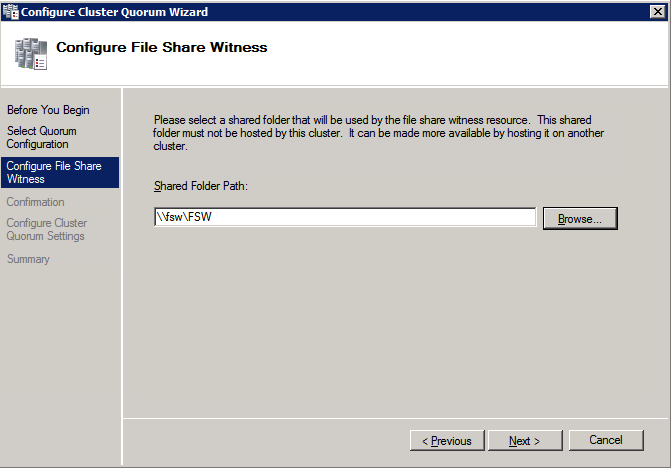 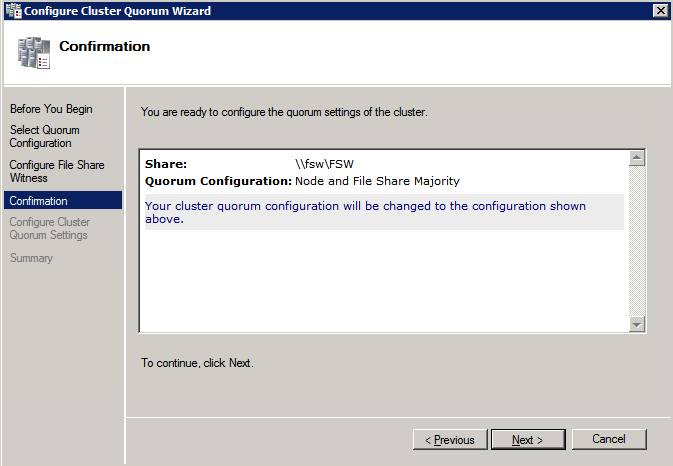 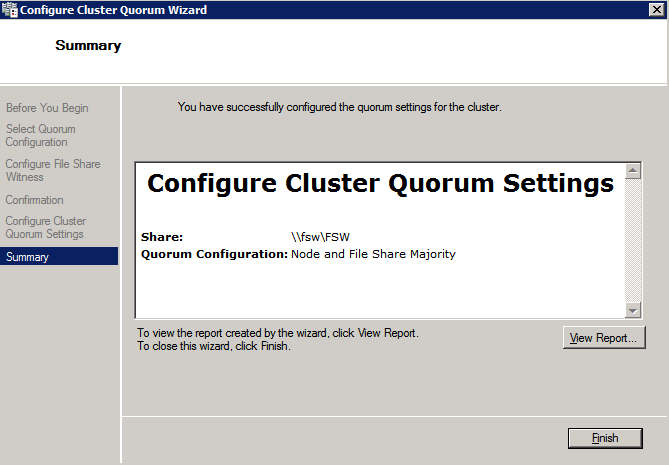 Buat Akun Layanan Untuk DataKeeperKami hampir siap untuk menginstal DataKeeper. Namun, sebelum kita melakukan itu, Anda perlu membuat akun Domain dan menambahkannya ke grup Administrator Lokal pada setiap contoh cluster SQL Server. Kami akan menentukan akun ini ketika kami menginstal DataKeeper. 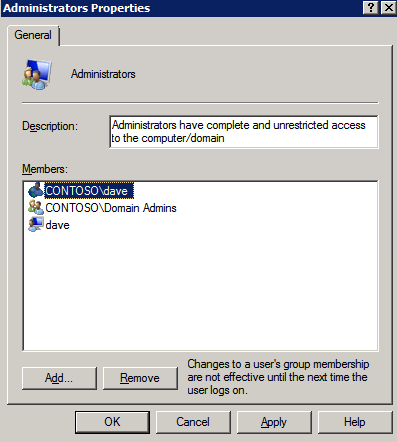 Instal DataKeeperInstal DataKeeper di masing-masing dari dua node cluster SQL Server seperti yang ditunjukkan di bawah ini.   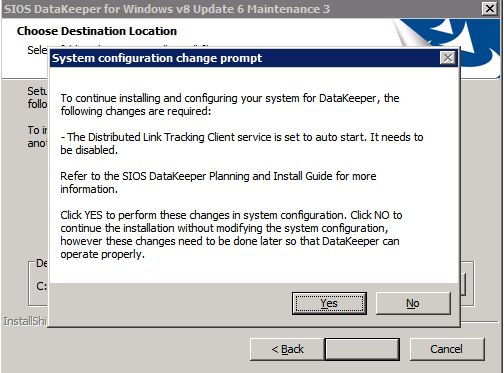 Di sinilah kami akan menentukan akun Domain yang kami tambahkan ke masing-masing grup Administrator Domain lokal. 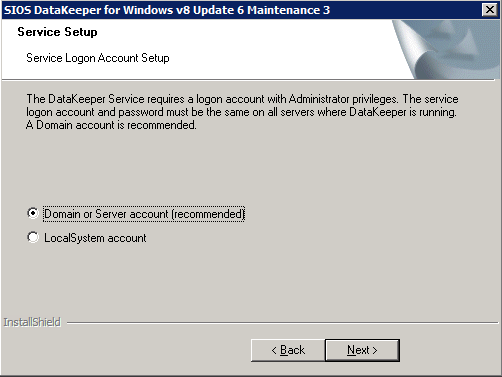   Konfigurasikan DataKeeperSetelah DataKeeper diinstal pada masing-masing dari dua node cluster, Anda siap untuk mengkonfigurasi DataKeeper. CATATAN – Kesalahan paling umum yang dihadapi dalam langkah-langkah berikut adalah terkait keamanan, paling sering oleh kelompok Azure Security yang sudah ada memblokir port yang diperlukan. Silakan lihat dokumentasi SIOS untuk memastikan server dapat berkomunikasi melalui port yang diperlukan. Pertama, Anda harus terhubung ke masing-masing dari dua node. 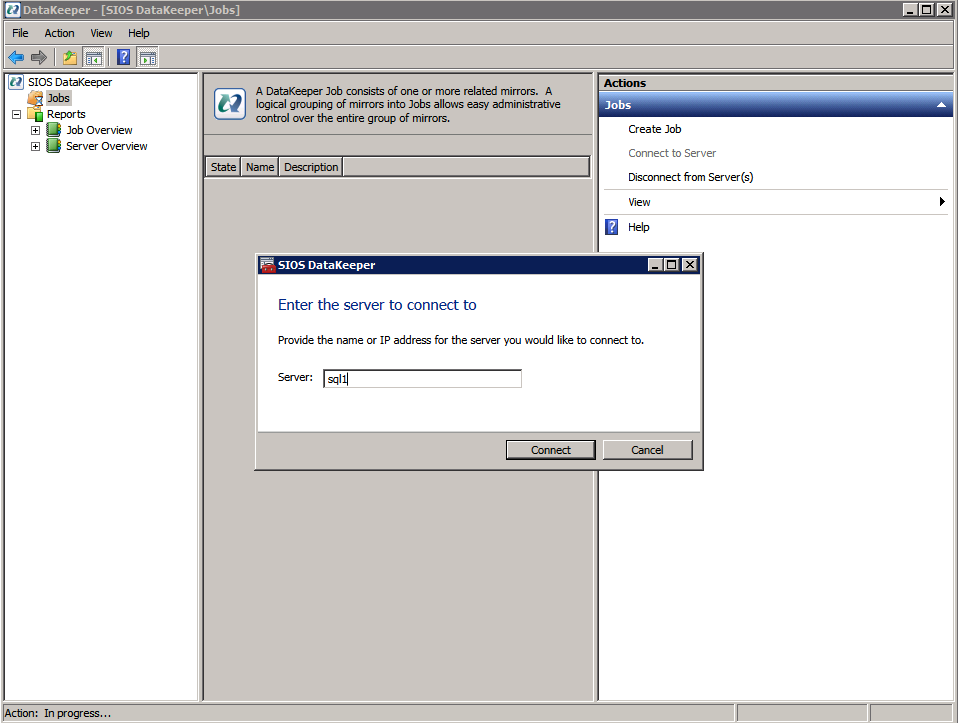 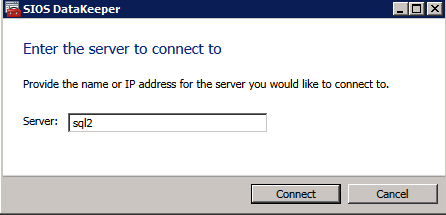 Jika semuanya sudah dikonfigurasikan dengan benar, Anda harus melihat yang berikut ini di laporan Tinjauan Server. 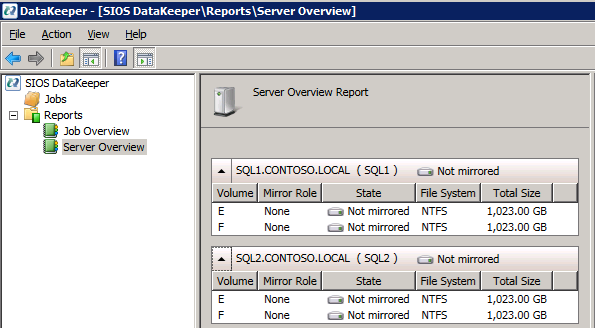 Selanjutnya, buat Pekerjaan Baru dan ikuti langkah-langkah yang diilustrasikan di bawah ini 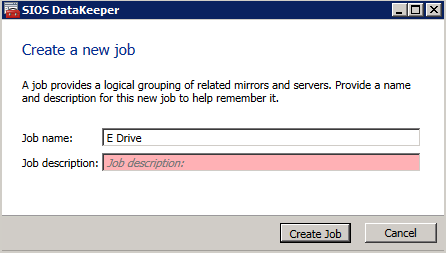 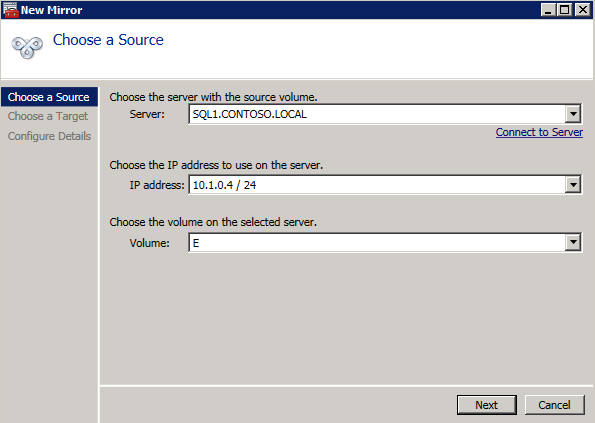 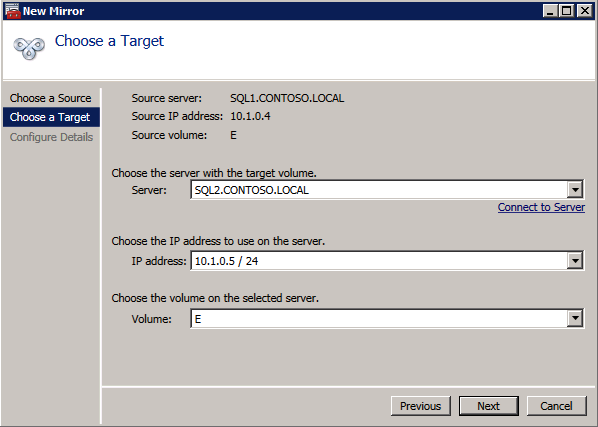 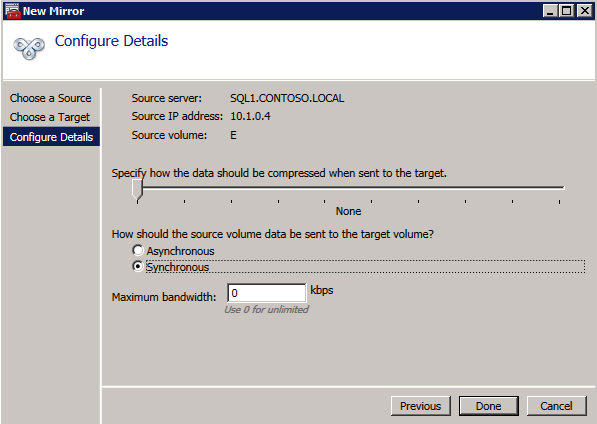 Pilih Ya di sini untuk mendaftarkan sumber daya Volume DataKeeper di Penyimpanan yang Tersedia 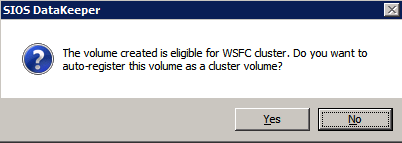 Selesaikan langkah-langkah di atas untuk masing-masing volume. Setelah selesai, Anda akan melihat yang berikut di UI Clustering Windows Server Failover. 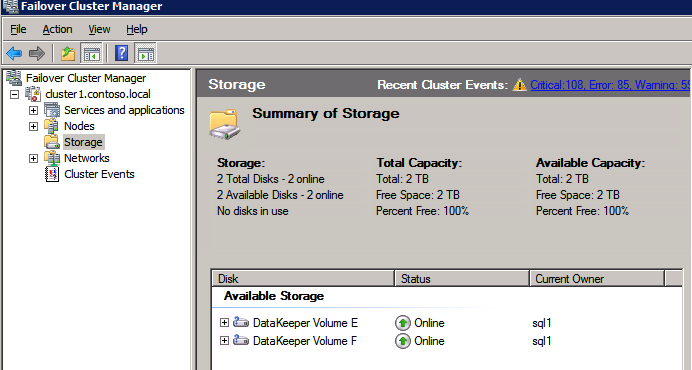 Anda sekarang siap untuk menginstal SQL Server ke dalam cluster. CATATAN – Pada titik ini volume yang direplikasi hanya dapat diakses pada node yang saat ini menampung Penyimpanan yang Tersedia. Itu yang diharapkan, jadi jangan khawatir! Instal SQL Server Di Node PertamaPada node pertama, jalankan pengaturan SQL Server.  Pilih Instalasi SQL Server Failover Cluster baru dan ikuti langkah-langkah seperti yang diilustrasikan. 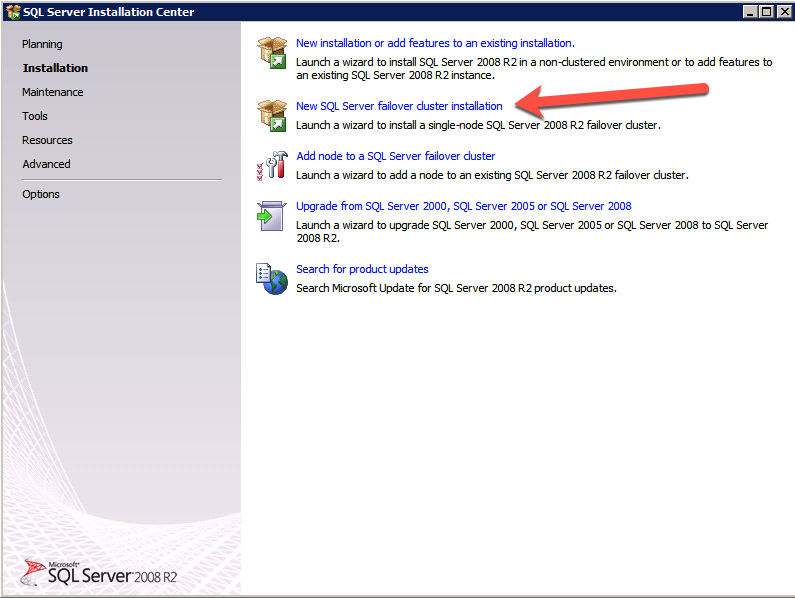 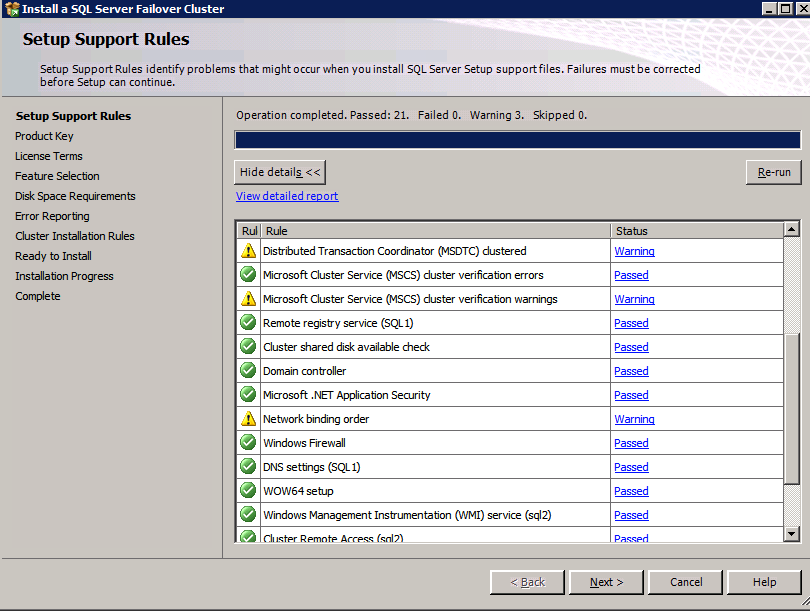 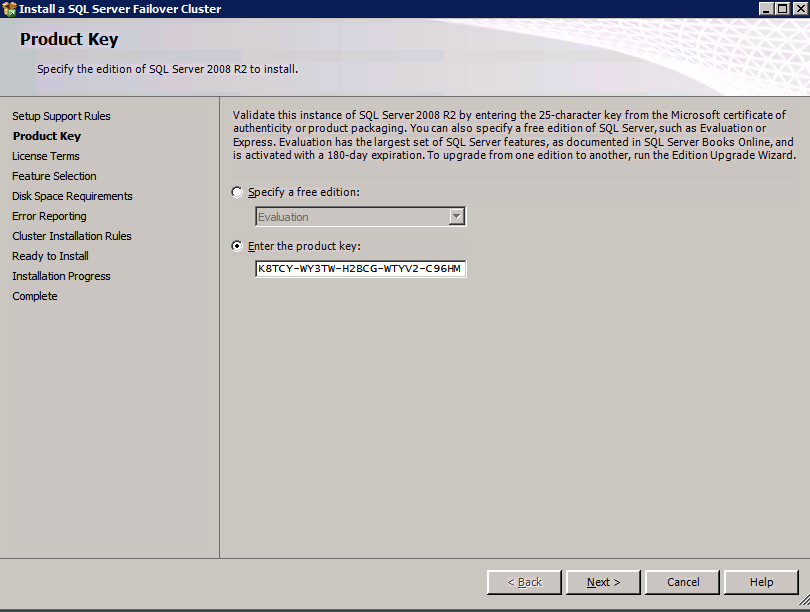  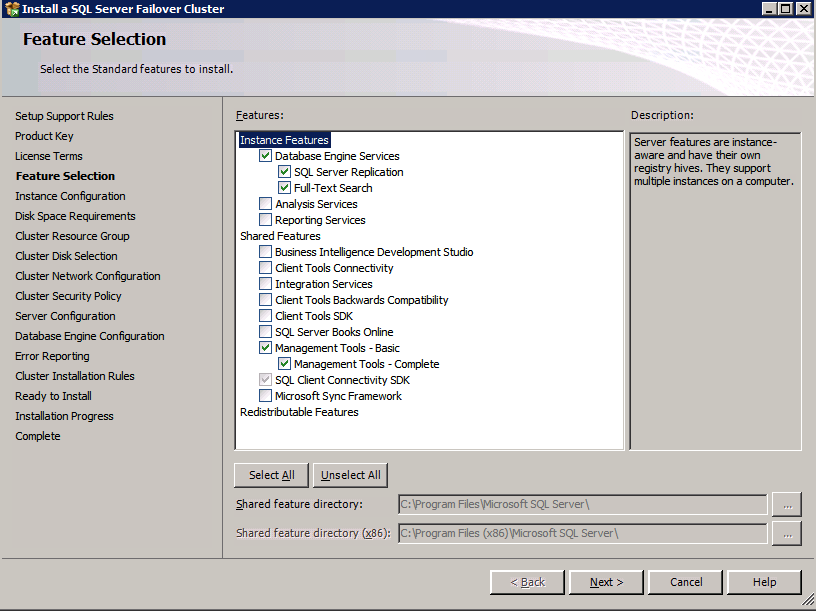 Pilih hanya opsi yang Anda butuhkan. Harap dicatat, dokumen ini mengasumsikan Anda menggunakan contoh default dari SQL Server. Jika Anda menggunakan Instance Bernama, Anda perlu memastikan Anda mengunci port yang didengarkannya, dan menggunakan port itu nanti ketika Anda mengkonfigurasi load balancer. Anda juga perlu membuat aturan penyeimbang beban untuk Layanan Peramban SQL Server (UDP 1434) agar dapat terhubung ke Mesin Virtual Bernama. Tidak satu pun dari kedua persyaratan tersebut tercakup dalam panduan ini. Tetapi jika Anda memerlukan Instance Bernama, itu akan berfungsi jika Anda melakukan dua langkah tambahan. 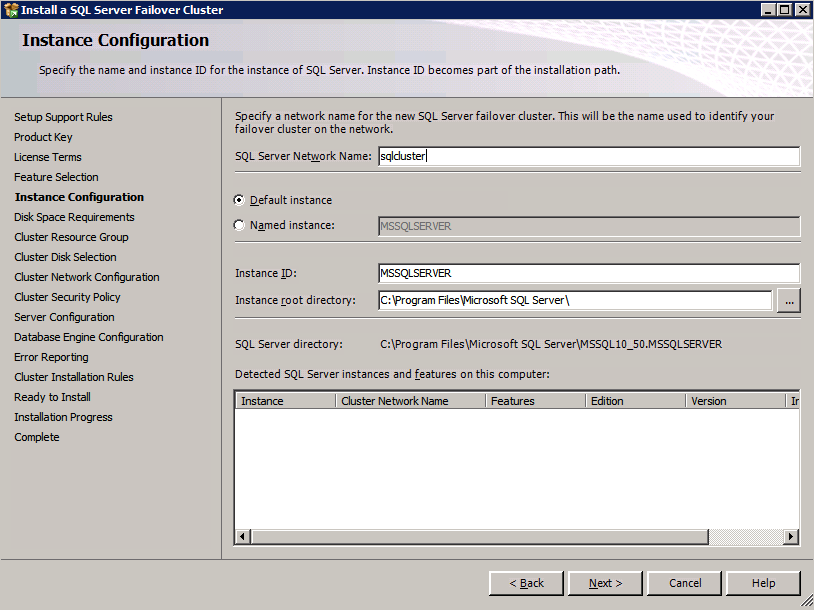 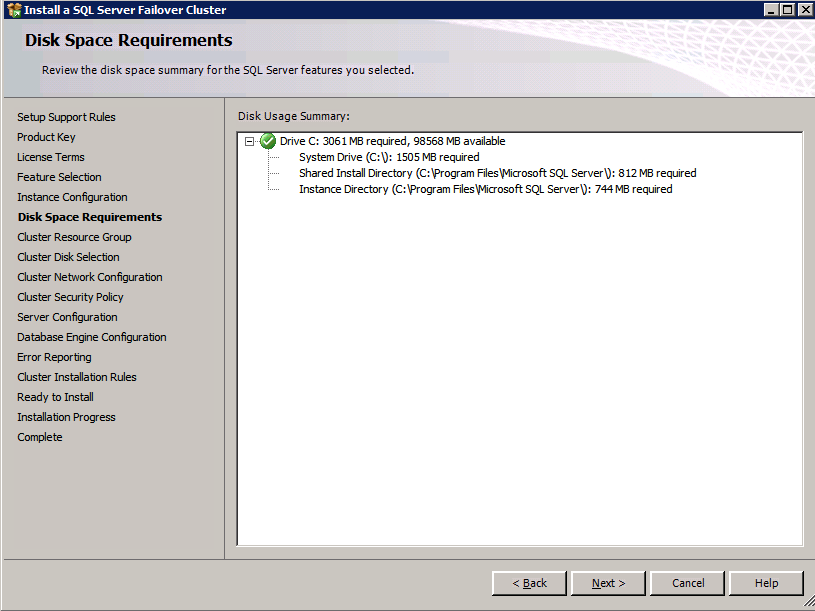 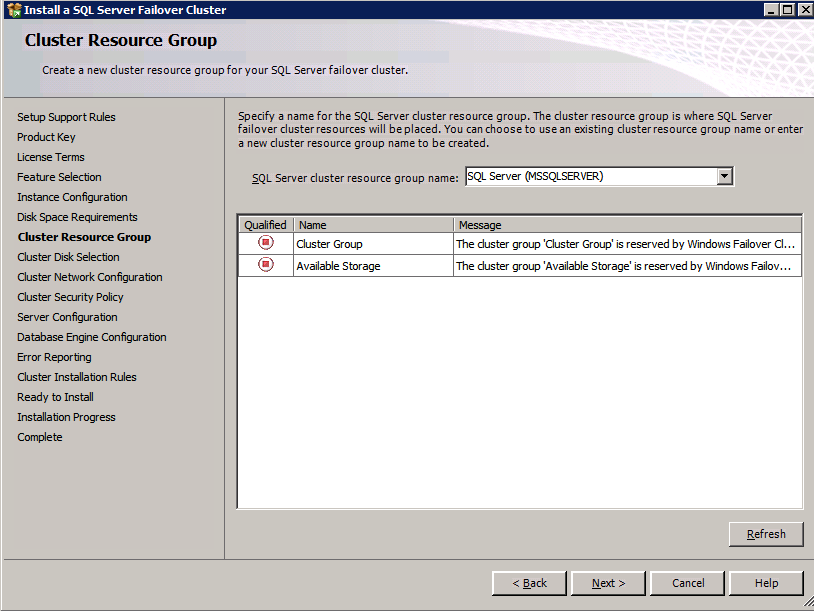 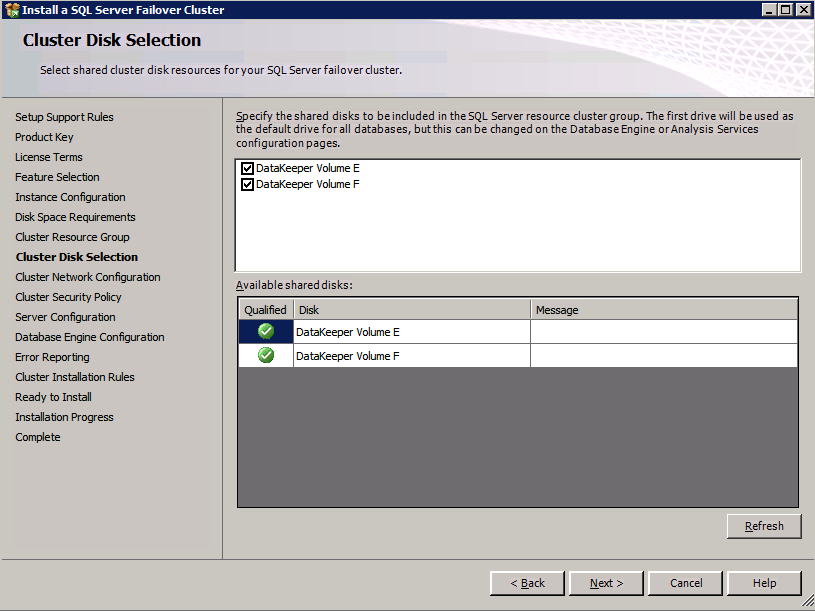 Di sini Anda perlu menentukan alamat IP yang tidak digunakan 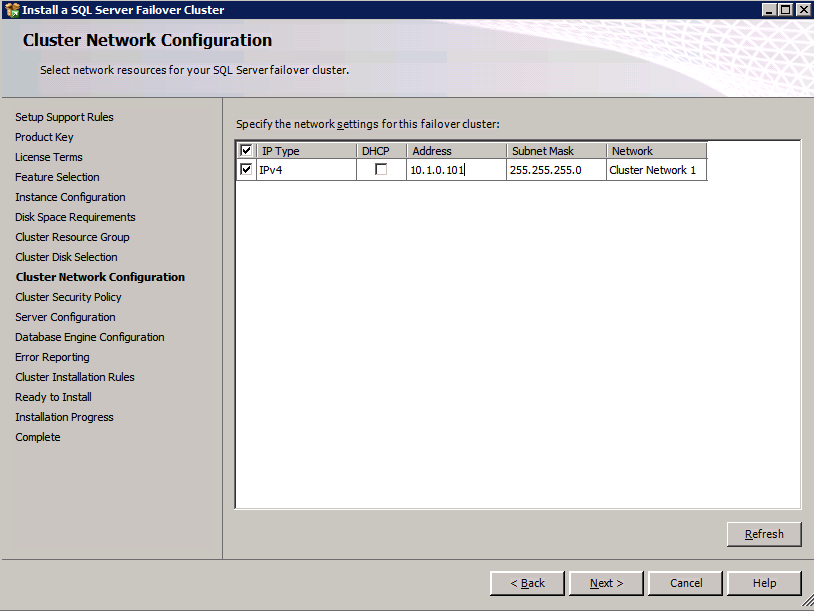 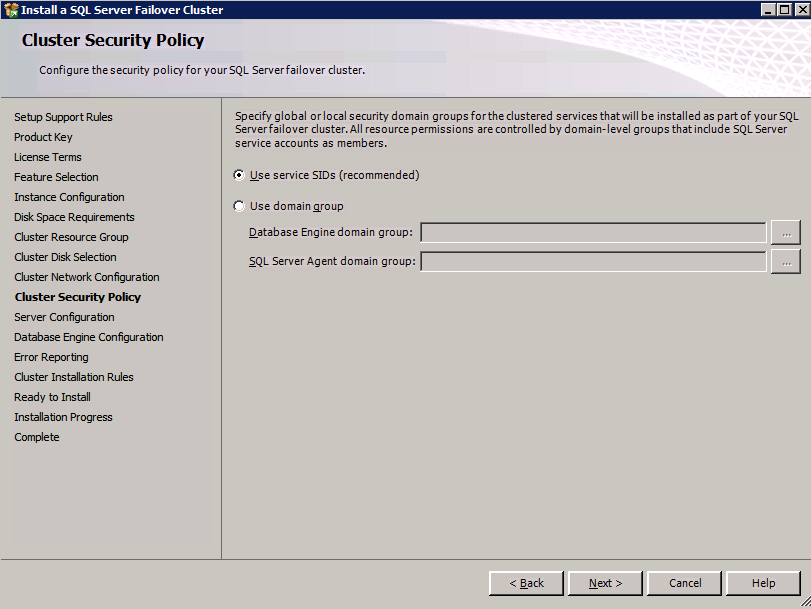 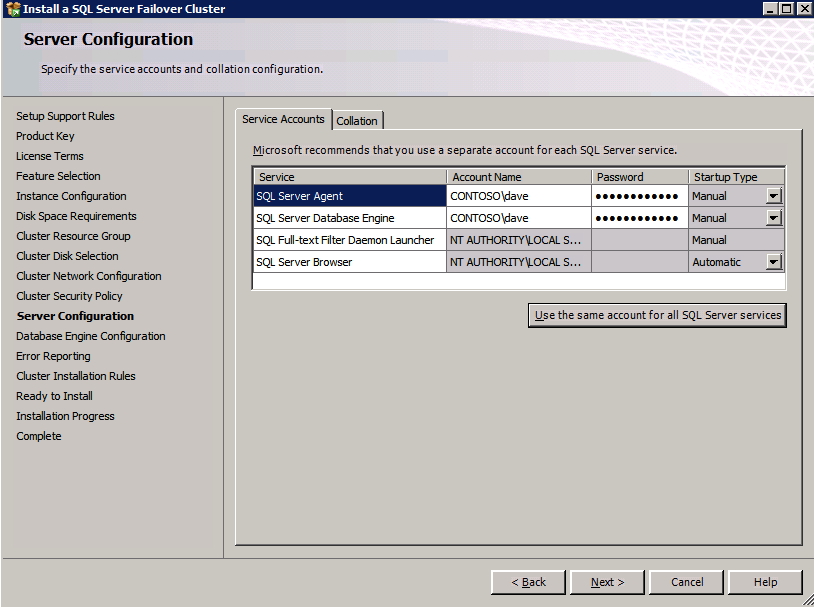 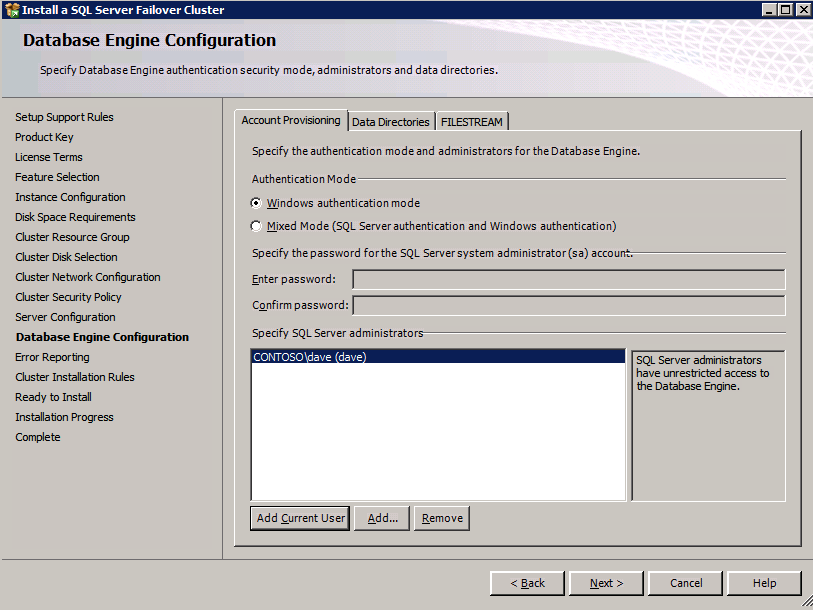 Buka tab Direktori Data dan pindahkan data dan file log. Pada akhir panduan ini, kita berbicara tentang memindahkan tempdb ke Volume DataKeeper yang tidak dicerminkan untuk kinerja yang optimal. Untuk saat ini, simpan saja di salah satu disk yang dikelompokkan. 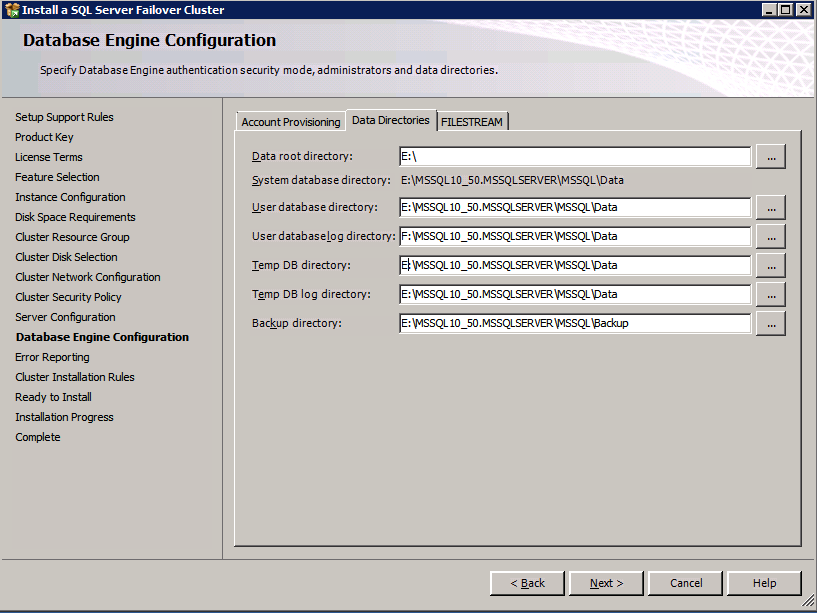 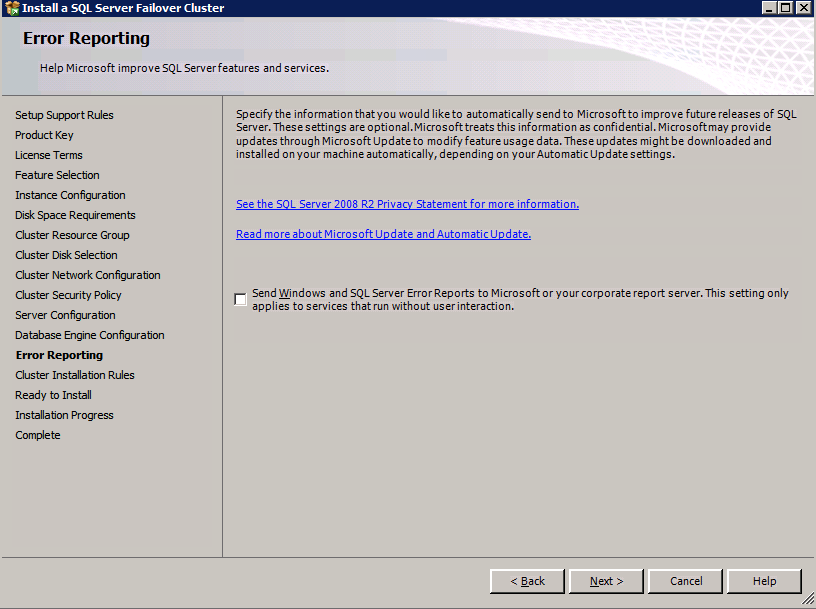 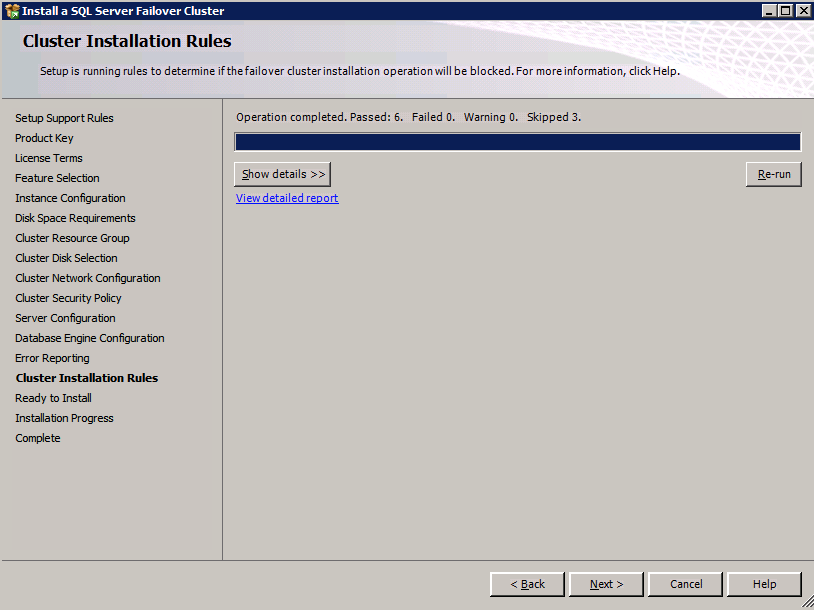 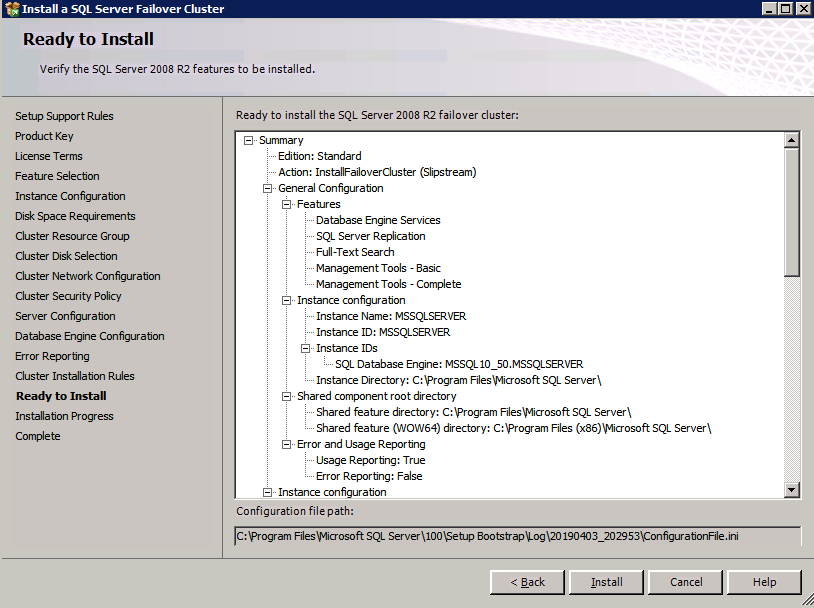 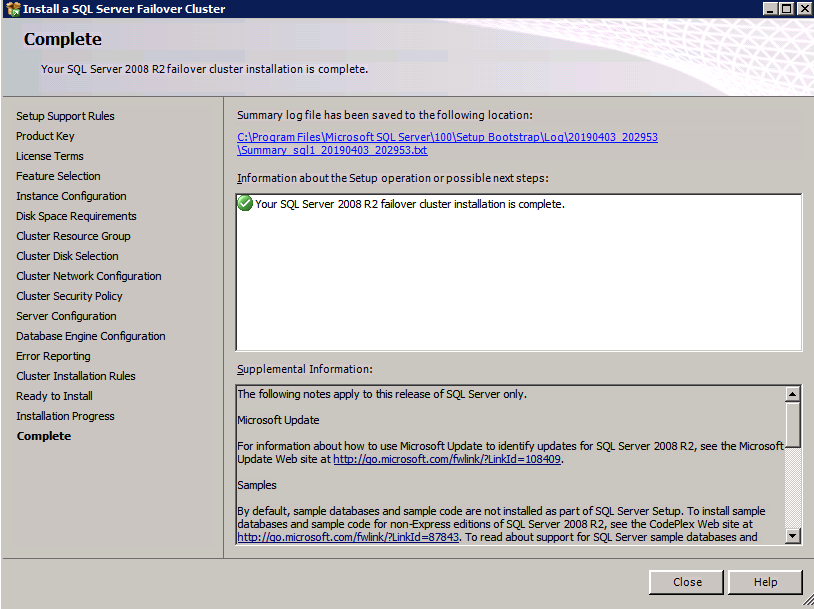 Instal SQL Pada Node KeduaJalankan pengaturan SQL Server lagi pada node kedua. Kemudian, pilih Tambahkan simpul ke Cluster Failover SQL Server.      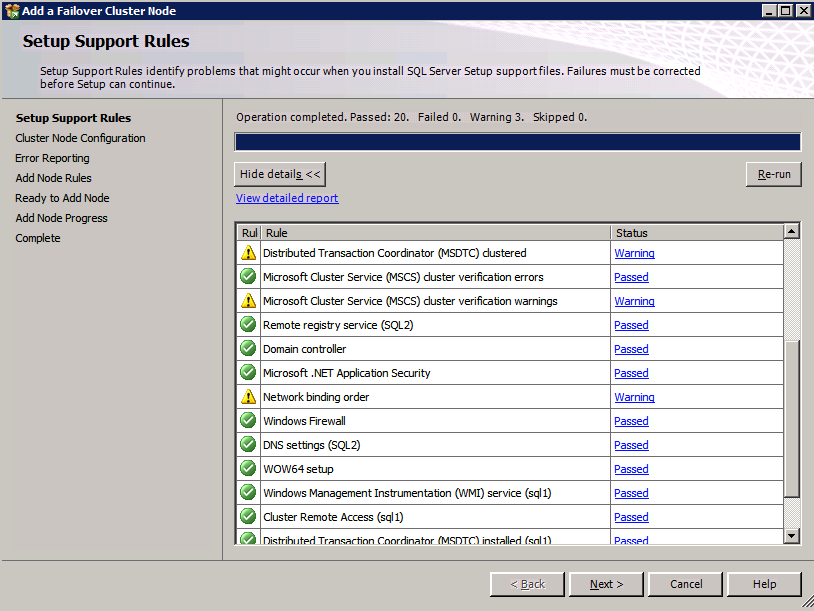 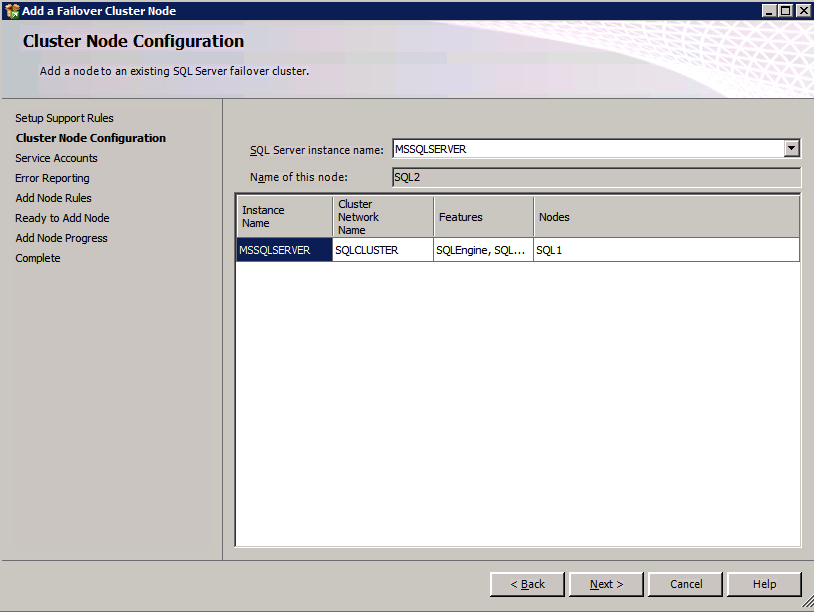 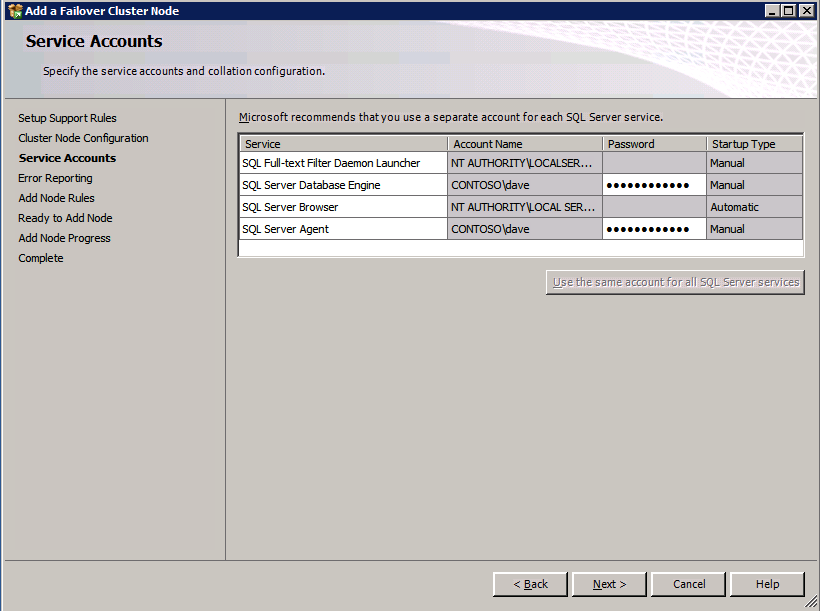     Selamat, Anda hampir selesai! Namun, karena kurangnya dukungan Azure untuk ARP serampangan, kami akan perlu mengonfigurasi Internal Load Balancer (ILB) untuk membantu pengalihan klien seperti yang ditunjukkan pada langkah-langkah berikut. Perbarui Alamat IP SQL ClusterAgar ILB berfungsi dengan benar, Anda harus menjalankan menjalankan perintah berikut dari salah satu node cluster. Itu SQL Cluster IP memungkinkan alamat IP SQL Cluster untuk menanggapi probe kesehatan ILB sementara juga mengatur subnet mask ke 255.255.255.255 untuk menghindari konflik alamat IP dengan probe kesehatan. 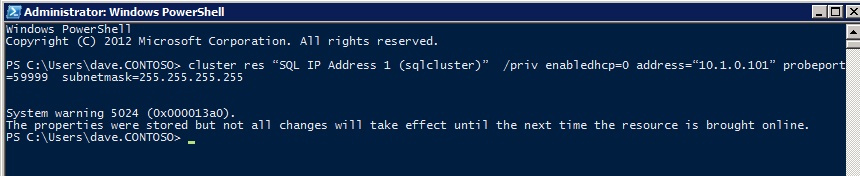 CATATAN – Saya tidak tahu apakah itu kebetulan. Kadang-kadang saya telah menjalankan perintah ini dan sepertinya berfungsi, tetapi tidak menyelesaikan pekerjaan dan saya harus memulai lagi. Cara saya tahu apakah itu bekerja adalah dengan melihat Subnet Mask dari SQL Server IP Resource. Jika bukan 255.255.255.255 maka Anda tahu itu tidak berhasil. Ini mungkin hanya masalah penyegaran GUI. Cobalah memulai kembali GUI kluster untuk memverifikasi subnet mask telah diperbarui. Setelah berhasil, ambil sumber daya secara offline dan bawa kembali online agar perubahan diterapkan. 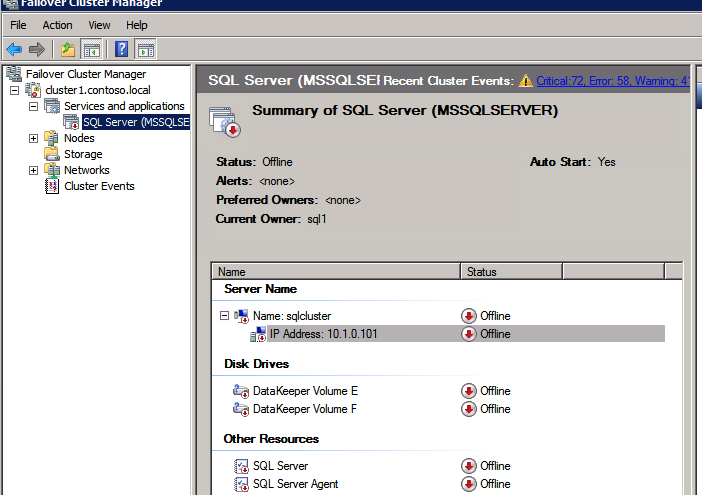 Buat Load BalancerLangkah terakhir adalah membuat penyeimbang beban. Dalam hal ini kami mengasumsikan Anda menjalankan Instance Default dari SQL Server, mendengarkan pada port 1433. Alamat IP Privat yang Anda tetapkan saat Anda Membuat load balancer akan menjadi alamat yang sama persis dengan yang Anda gunakan SQL Server FCI. 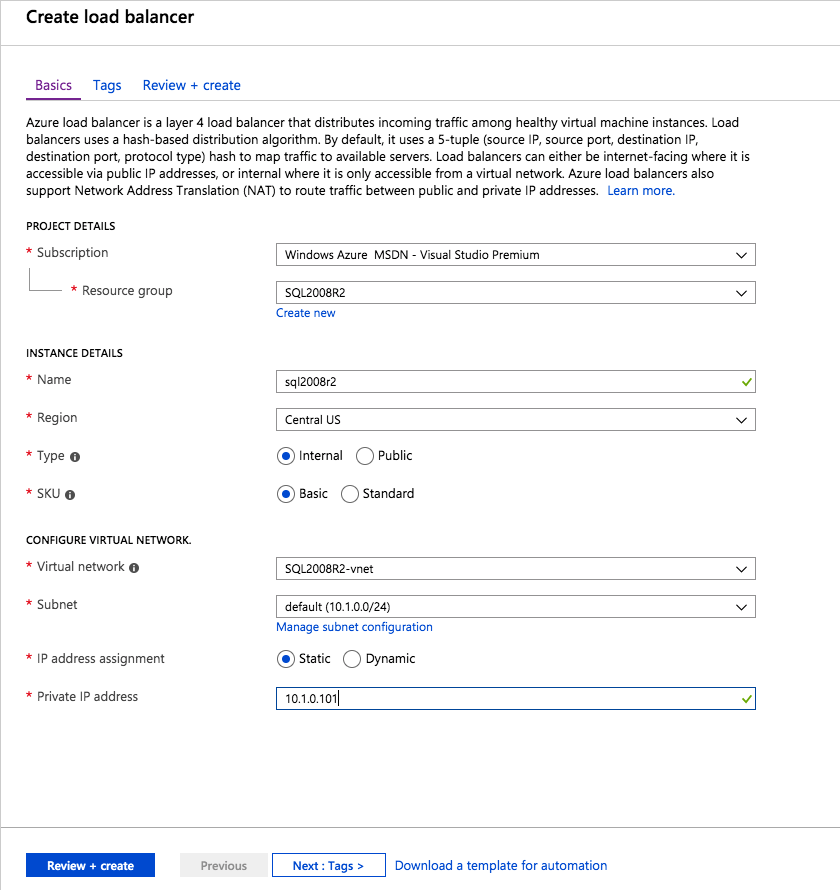 Tambahkan hanya dua contoh SQL Server ke kolam backend. JANGAN menambahkan FSW ke kolam backend. 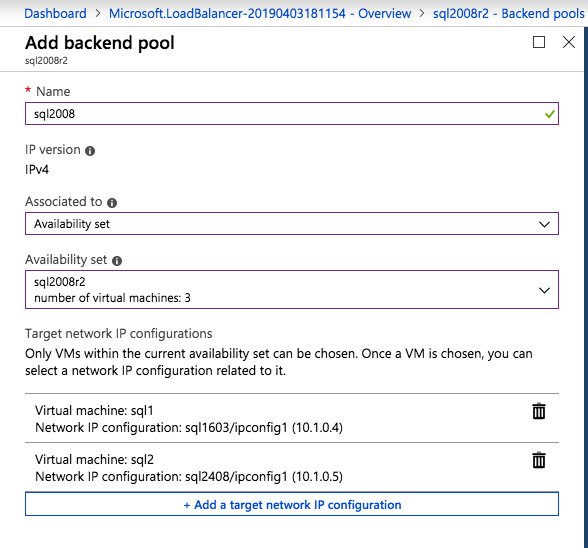 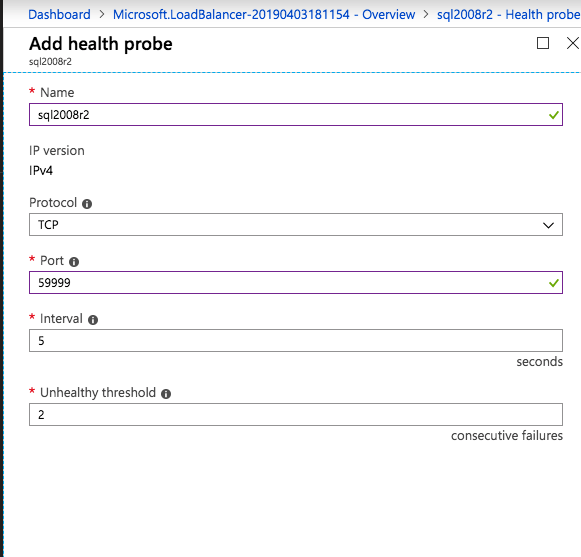 Dalam aturan penyeimbangan beban ini, Anda harus mengaktifkan IP Terapung. 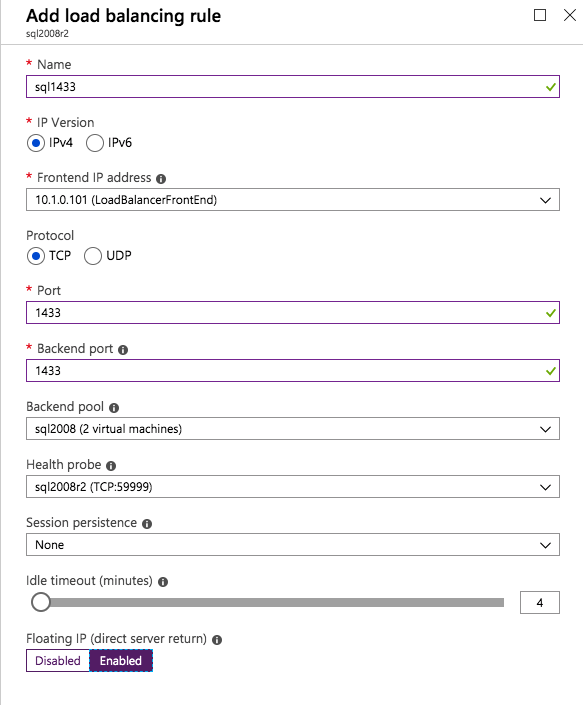 Uji ClusterTes paling sederhana adalah membuka SQL Server Management Studio pada node pasif dan terhubung ke cluster. Selamat! Anda melakukan semuanya dengan benar saat terhubung! Jika Anda tidak dapat terhubung, jangan takut. Saya menulis artikel blog untuk membantu memecahkan masalah ini. Mengelola cluster sama persis dengan mengelola cluster penyimpanan bersama tradisional. Semuanya dikendalikan melalui Failover Cluster Manager. Opsional – Pindahkan TempDBUntuk kinerja optimal, disarankan untuk memindahkan tempdb ke SSD lokal yang tidak direplikasi. Tapi, SQL Server 2008 R2 membutuhkan tempdb berada di disk berkerumun. SIOS memiliki solusi yang disebut Sumber Daya Volume Tidak Tercermin yang mengatasi masalah ini. Dianjurkan untuk membuat sumber daya volume yang tidak dicerminkan dari drive SSD lokal dan memindahkan tempdb ke sana. Perhatikan, drive SSD lokal tidak persisten. Anda harus berhati-hati untuk memastikan folder yang menahan tempdb dan izin pada folder itu diciptakan kembali setiap kali server reboot. Setelah Anda membuat Sumber Daya Volume Tanpa Cermin dari SSD lokal, ikuti langkah-langkah dalam artikel ini untuk memindahkan tempdb. Skrip startup yang dijelaskan dalam artikel itu harus ditambahkan ke setiap node cluster. Diproduksi ulang dengan izin dari Clusteringformeremortals.com |
| April 20, 2019 |
Video: Membangun Cluster SANless untuk SQL Server |
Video: Clusters Your Way |
|
Video: Keuntungan SIOS ClusteringKeuntungan SIOS ClusteringPelajari bagaimana perangkat lunak pengelompokan SIOS memudahkan melindungi aplikasi. Setiap tahun, tugas Anda cenderung memberikan tingkat layanan yang lebih tinggi menggunakan infrastruktur yang ada dan anggaran TI yang lebih kecil. Toleransi untuk downtime atau kehilangan data hilang. Aplikasi harus menyala 24/7 dan Anda harus dilindungi apakah itu pemadaman server, pemadaman jaringan, pemadaman aplikasi, atau bahkan hilangnya seluruh pusat data. Harapannya adalah bahwa jumlah downtime dan jumlah kehilangan data menyatu pada "0". Para profesional TI memiliki lebih banyak pilihan tentang bagaimana Anda akan mendukung pengguna akhir Anda apakah itu penyebaran server fisik, server virtual, atau bahkan teknologi cloud. Memilih solusi dilakukan untuk memahami tujuan bisnis, persyaratan teknis, dan batasan anggaran serta perlu memahami bagaimana Anda akan melindungi lingkungan untuk memastikannya selalu tersedia dan Anda tidak akan mengalami downtime atau kehilangan data. Ini biasanya dilakukan dengan menerapkan kluster berbasis SAN tradisional yang melibatkan dua atau lebih server yang terhubung ke beberapa jenis penyimpanan bersama. Jika ada masalah, aplikasi akan gagal dan membawa semuanya kembali online. Perangkat lunak SIOS mendukung hal ini dan membuatnya mudah diatur dan dikelola. Meskipun kluster berbasis SAN cocok untuk ketersediaan lokal yang tinggi, SAN umumnya mewakili biaya tinggi, kompleksitas, potensi kegagalan dalam arsitektur klaster Anda, dan juga tidak membantu Anda memecahkan masalah pemulihan bencana. Perangkat lunak SIOS memungkinkan Anda untuk membangun cluster Anda menggunakan perangkat keras pilihan Anda tetapi sekarang memanfaatkan penyimpanan lokal. SIOS menyediakan replikasi data tingkat blok waktu-nyata yang sepenuhnya sadar dan terintegrasi cluster memungkinkan Anda memanfaatkan penyimpanan lokal yang sangat cepat dengan konfigurasi cluster Anda. Juga, mengadopsi kluster SANLess dapat mengurangi biaya keseluruhan solusi dengan menghilangkan SAN. Akibatnya, Anda tidak hanya menghilangkan biaya perangkat keras SAN tetapi juga infrastruktur SAN dan biaya administrasi yang datang bersama dengan penghematan lisensi SAN Anda. Selain itu, Anda akan memotong satu titik kegagalan dalam arsitektur pengelompokan Anda sehingga tidak akan menghapus seluruh lingkungan. Anda juga dapat menghilangkan kehilangan data karena teknologi replikasi data tingkat blok waktu nyata kami membuat penyimpanan lokal tetap sinkron. Disediakan dengan perangkat lunak, ada juga antarmuka pengguna berbasis penyihir ramah pengguna. Singkatnya, SIOS memberi Anda fleksibilitas untuk melindungi aplikasi dan data penting misi Anda dalam lingkungan fisik, virtual, atau cloud. Pelajari lebih lanjut tentang solusi ketersediaan tinggi kami. |

