| November 12, 2020 |
Otomatisasi APM – Bahan yang Hilang Untuk Solusi Pemantauan Kinerja Aplikasi
Otomatisasi APM – Bahan yang Hilang Untuk Solusi Pemantauan Kinerja AplikasiPerusahaan yang pindah ke cloud untuk menghosting aplikasi mereka memahami bahwa meskipun mereka telah mengalihkan hosting aplikasi mereka ke vendor cloud pihak ketiga seperti Amazon Web Services, mereka masih perlu memantau dan mengelola aplikasi tersebut sendiri, biasanya dengan Application Performance Monitoring solusi atau APM. Dengan aplikasi komputasi server-klien kemarin, I.T. departemen memiliki kendali penuh atas server, jaringan, dan lingkungan komputasi pengguna akhir.Namun lingkungan cloud saat ini lebih kompleks, dengan lebih banyak bagian bergerak yang sering kali berada di luar kendali Anda. Beberapa perusahaan telah memulai transformasi digital, mendorong interaksi pelanggan menjadi aplikasi kritis berbasis web.Sekarang lebih penting dari sebelumnya untuk segera menanggapi masalah kinerja aplikasi dan waktu henti apa pun melalui solusi otomatisasi APM. Cara Memilih Solusi APMBanyak perusahaan beralih ke solusi Manajemen Kinerja Aplikasi seperti dari AppDynamics, Datadog, Dynatrace, atau New Relic.Solusi APM harus mengidentifikasi semua hambatan kinerja dalam kode Anda, dan membantu Anda memperbaiki masalah tersebut sebelum pengguna Anda terpengaruh. Solusi APM yang baik akan memberi tahu Anda apa yang terjadi, mengapa, dan bagaimana mencegahnya terjadi di masa mendatang.Solusi APM akan mengingatkan Anda ketika aplikasi atau sistem yang dipantau memenuhi kondisi tertentu (beban, waktu respons, dll.).Setelah Anda menerima peringatan, Anda harus dapat mengidentifikasi mengapa aplikasi tidak bekerja dengan baik.Berbekal informasi ini, Anda dapat memberi tim pengembangan Anda diagnosis yang sangat mendetail yang akan memungkinkan mereka untuk mengatasi masalah dan mencegahnya terjadi di masa mendatang. Tetapi bagaimana Anda memilih solusi solusi Pemantauan Kinerja Aplikasi yang tepat?Pencarian cepat di Google untuk "solusi cloud APM" menghasilkan 5.830.000 hasil!Itu bisa sangat membebani siapa pun yang tidak terbiasa dengan ruang tersebut.Untungnya, pencarian Google lainnya juga akan memberi Anda banyak saran dan sumber daya tentang cara memilih solusi APM yang tepat untuk Anda.Anda harus mencari saran pihak ketiga non-vendor untuk membantu Anda menyusun persyaratan Anda dan mengembangkan daftar pendek pilihan yang memenuhi persyaratan tersebut.Gartner telah mengamati kategori ini selama beberapa waktu dan menerbitkan APM Magic Quadrant setiap tahun.Ini adalah sumber daya yang baik dalam hal memahami cara mengevaluasi solusi solusi Pemantauan Kinerja Aplikasi dan memberikan gambaran umum yang baik tentang vendor teratas. Tambahkan APM otomatis ke daftar persyaratan remediasi AndaDi sini, di SIOS Technology Corporation, kami selalu bekerja dengan pelanggan yang memigrasi aplikasi mereka ke cloud.Mereka sering kali ingin mengetahui cara melindungi aplikasi mereka dari waktu henti yang tidak perlu dan meminta saran dari kami.Pilihan bagaimana melindungi aplikasi mereka adalah fungsi dari kekritisan aplikasi tersebut (aplikasi yang lebih kritis sering kali membutuhkan solusi failover, dll.). Namun kami juga membantu mereka memahami mengapa aplikasi mereka mungkin rentan. Dulu pencadangan dan perlindungan data adalah fungsi terpisah (yang hanya diperlukan jika solusi APM mengidentifikasi waktu henti).Namun dalam lingkungan cloud yang kompleks saat ini, kami percaya bahwa organisasi harus mencari pendekatan holistik dalam hal memantau dan mengelola aplikasi penting mereka.Jika solusi APM tradisional mengidentifikasi kapan sesuatu terjadi dan memungkinkan Anda mendiagnosis mengapa hal itu terjadi, mengapa solusi itu tidak mencegah downtime yang tidak perlu jika memungkinkan? Kami percaya bahwa otomatisasi adalah unsur yang hilang dari sebagian besar solusi cloud APM.Banyak pelanggan kami memberi tahu kami bagaimana mereka kewalahan dengan menerima terlalu banyak peringatan dari solusi APM mereka, masing-masing meminta mereka untuk berhenti dan memahami apa yang terjadi dan mengapa.Mereka dengan cepat memahami apa yang harus diabaikan dan apa yang harus diperhatikan (dan solusi APM yang baik membantu mereka melakukan ini melalui pembelajaran mesin).Dan jika dan ketika aplikasi mereka turun, solusi APM memperingatkan mereka tentang waktu henti dan mendiagnosis mengapa membantu mencegah hal itu terjadi lagi.Namun solusi APM tidak akan mengurangi waktu henti langsung mereka. Di situlah SIOS AppKeeper berperan. AppKeeper memantau aplikasi pelanggan yang berjalan di Amazon EC2 dan secara otomatis memulai ulang layanan di EC2 atau bahkan me-reboot instans EC2 jika dan saat waktu henti terdeteksi.Pelanggan rata-rata kami, dengan hanya 3 instans Amazon EC2, mengalami waktu henti setidaknya sebulan sekali.Itu adalah waktu henti ketika aplikasi kritis, seringkali berhadapan dengan pelanggan, tidak tersedia, dan ketika I.T. tim harus melepaskan semuanya dan merespons. Solusi otomatisasi APM AppKeeper memungkinkan pelanggan pulih secara otomatis dari lebih dari 85% situasi waktu henti Amazon EC2 mereka.Berikut tautan ke video singkat jika Anda ingin melihat AppKeeper beraksi. Melalui AppKeeper's API, pelanggan secara terprogram memperluas nilai solusi APM mereka dengan meminta peringatan dari solusi APM mereka memicu AppKeeper untuk secara otomatis memulai ulang layanan Amazon EC2 yang diterapkan atau memulai ulang instans jika perlu.
Pemantauan Kinerja Aplikasi dan Remediasi Otomatis.Lebih baik dari selai kacang dan agar-agar?Dalam banyak kasus, pelanggan AppKeeper memiliki kemudahan untuk mengelola lingkungan Amazon EC2, dengan mungkin kurang dari 8 instans Amazon EC2.Bagi mereka, fungsi pemantauan asli dan remediasi otomatis dari AppKeeper cukup untuk membuat mereka tidur nyenyak di malam hari, mengetahui bahwa mereka secara proaktif mengurangi waktu henti jika dan ketika hal itu terjadi. Namun kami menyadari bahwa banyak pelanggan memiliki lingkungan cloud yang lebih canggih, dan telah berinvestasi dalam solusi APM, seperti dari New Relic, Datadog, Dynatrace, LogicMonitor, atau Zabbix.Mereka mengharapkan lansiran langsung dan kumpulan data yang kaya untuk membantu mereka mendiagnosis apa yang terjadi dan mengapa.Untuk kumpulan pelanggan ini, menurut kami, penambahan fungsi remediasi otomatis AppKeeper ke toolkit APM mereka memberi mereka yang terbaik dari kedua dunia: kontrol atas kinerja aplikasi mereka, dan pengurangan waktu henti. Selama beberapa bulan ke depan, SIOS Technology akan bekerja dengan beberapa vendor APM terkemuka untuk menyediakan integrasi paket dan bersertifikat antara solusi APM dan AppKeeper mereka.Dengan menggunakan integrasi ini dengan AppKeeper, pengguna ini sekarang akan menikmati sistem loop tertutup, di mana mereka akan diberi tahu untuk mendeteksi waktu henti Amazon EC2 dan tindakan perbaikan yang dilakukan AppKeeper. Jadi nantikan beberapa berita menarik.Sementara itu, jika Anda ingin mencoba SIOS AppKeeper sendiri, silakan mendaftar uji coba AppKeeper gratis selama 14 hari. AppKeeper mulai hanya dengan US $ 40 per instance per bulan. Direproduksi dengan izin dari SIOS |
| Oktober 25, 2020 |
Enam Alasan Tidak Membeli Perangkat Lunak Ketersediaan Tinggi SIOS. . . Jika kamu berani |
| Oktober 19, 2020 |
Mengurangi waktu henti untuk situs WordPress yang dihosting di Amazon EC2 |
| September 27, 2020 |
Bermigrasi ke cloud? Berikut ini bagaimana prioritas DevOps Anda harus berubah saat Anda pindah ke Amazon EC2 |
| September 20, 2020 |
Perluas Metrik Ketersediaan Tinggi Anda |

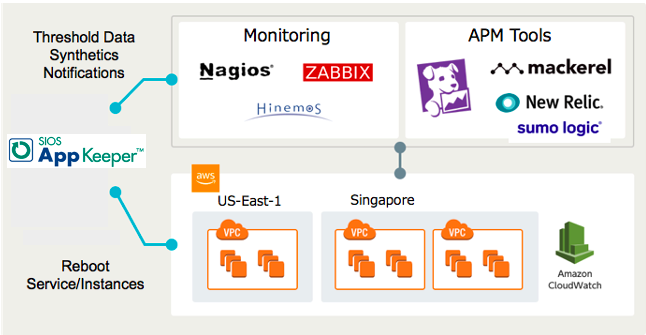


 Banyak solusi pemantauan WordPress (dari plugin gratis hingga layanan freemium berbiaya rendah) akan memberi tahu Anda saat situs WordPress Anda tidak aktif.Dan tergantung pada kecanggihan (dan biaya) solusi pemantauan Anda, ini mungkin memberi tahu Anda mengapa situs WordPress Anda turun.Tetapi apakah ini akan membantu Anda mengurangi waktu henti dan secara otomatis memulai ulang layanan Anda atau mem-boot ulang instans Anda saat waktu henti dialami?
Banyak solusi pemantauan WordPress (dari plugin gratis hingga layanan freemium berbiaya rendah) akan memberi tahu Anda saat situs WordPress Anda tidak aktif.Dan tergantung pada kecanggihan (dan biaya) solusi pemantauan Anda, ini mungkin memberi tahu Anda mengapa situs WordPress Anda turun.Tetapi apakah ini akan membantu Anda mengurangi waktu henti dan secara otomatis memulai ulang layanan Anda atau mem-boot ulang instans Anda saat waktu henti dialami?