| Desember 18, 2020 |
Menghitung Ketersediaan Aplikasi di Cloud
Menghitung Ketersediaan Aplikasi di CloudSaat menerapkan aplikasi bisnis penting di cloud, Anda ingin memastikan ketersediaannya sangat tinggi. Kabar baiknya adalah jika Anda merencanakan dengan benar, Anda dapat mencapai 99,99% (4-sembilan) ketersediaan atau lebih. Namun, menghitung ketersediaan Anda yang sebenarnya mungkin tidak sesederhana kelihatannya. Saat mempertimbangkan ketersediaan, Anda harus mempertimbangkan komponen utama yang memungkinkan akses ke aplikasi Anda, yang akan saya sebut rantai ketersediaan. Komponen rantai ketersediaan adalah:
Aplikasi Anda hanya tersedia sebagai tautan terlemah Anda, dan waktu henti Anda meningkat secara eksponensial dengan setiap tautan tambahan yang Anda tambahkan ke rantai.Mari kita periksa setiap tautan. Hitung KetersediaanMasing-masing dari tiga penyedia layanan cloud utama memiliki beberapa kesamaan. Satu kesamaan di ketiga platform adalah perjanjian tingkat layanan (SLA) yang akan mereka janjikan untuk komputasi. SLA untuk ketiga penyedia cloud publik untuk VM saat Anda memiliki dua atau lebih VM yang dikonfigurasi di berbagai zona ketersediaan adalah 99,99%.Perlu diingat, SLA ini hanya menjamin aksesibilitas jarak jauh dari salah satu VM pada waktu tertentu, SLA tidak menjanjikan ketersediaan layanan atau aplikasi yang berjalan di dalam VM.Jika Anda menerapkan satu VM dalam satu pusat data, SLA ini bervariasi dari "90% setiap jam" (AWS) hingga 99,5% (Azure dan GCP) atau 99,9% (VM tunggal Azure saat menggunakan SSD Premium). Ketersediaan tinggi sebenarnya dimulai dari 99,99%, jadi langkah pertama adalah memastikan aplikasi Anda tersedia adalah memastikan aplikasi didistribusikan ke dua atau lebih VM yang menjangkau zona ketersediaan. Dengan dua VM yang tersebar di dua zona ketersediaan, yang memberi Anda 99,99% ketersediaan dari setidaknya satu VM tersebut, Anda dapat berteori bahwa jika Anda memiliki tiga VM yang tersebar di tiga zona ketersediaan, ketersediaan Anda akan lebih besar dari 99,99%. Meskipun SLA penyedia cloud tidak akan pernah menjamin melebihi ketersediaan 99,99% terlepas dari jumlah zona ketersediaan yang digunakan, jika Anda menggunakan statistik murni, Anda mungkin sampai pada kesimpulan bahwa ketersediaan Anda dapat melonjak hingga 99,9999999% atau 8-sembilan dari ketersediaan, waktu henti 26,30 milidetik per bulan. 1 – (. 0001 * .0001) = .99999999 99,999999% ketersediaan dengan tiga zona ketersediaan? Jangan seenaknya mengutip angka itu. Namun perlu diingat bahwa masuk akal jika dua zona ketersediaan dapat memberi Anda ketersediaan 99,99%. Masuk akal bahwa tiga zona ketersediaan akan memberi Anda sesuatu yang secara signifikan lebih dari 99,99% ketersediaan. Hitung hanyalah salah satu tautan dalam rantai ketersediaan. Kami masih harus menangani jaringan, penyimpanan, dan layanan lain yang bergantung, yang semuanya mewakili kemungkinan titik kegagalan. Ketersediaan JaringanAgar aplikasi Anda tersedia, setiap hop jaringan antara klien dan aplikasi dan semua sumber daya yang bergantung pada aplikasi, harus tersedia dan bekerja dalam rentang latensi yang dapat ditoleransi. Anda perlu memahami tautan jaringan antara server basis data, server aplikasi, server web, dan klien untuk mengetahui dengan tepat di mana jaringan mungkin gagal. Ingat, semakin banyak tautan dalam rantai ketersediaan Anda, semakin rendah ketersediaan Anda secara keseluruhan. Meskipun ketersediaan jaringan antara VM dalam vNet yang sama tercakup dalam SLA komputasi standar, ada layanan jaringan lain yang mungkin Anda gunakan. Berikut adalah beberapa contoh layanan jaringan yang dapat Anda manfaatkan yang akan memengaruhi ketersediaan aplikasi secara keseluruhan. Rute Ekspres – 99,95% Berdasarkan apa yang telah kita pelajari sejauh ini, mari kita lihat ketersediaan aplikasi yang diterapkan di dua zona ketersediaan. Ketersediaan komputasi 99,99% Ketersediaan penyeimbang beban 99,99% .9999 * .9999 = .9998 Ketersediaan 99,98% = ~ 9 menit waktu henti per bulan Sekarang setelah kita membahas ketersediaan komputasi dan jaringan, mari beralih ke penyimpanan. Ketersediaan PenyimpananSekarang di sinilah ceritanya menjadi sedikit berbulu. Lihat SLA penyimpanan berikut https://azure.microsoft.com/en-us/support/legal/sla/storage/v1_5/ https://cloud.google.com/storage/sla https://aws.amazon.com/compute/sla/ Tampaknya cukup jelas bahwa Azure dan Google memberi Anda SLA 99,9% pada solusi penyimpanan blok. AWS tidak menyebutkan EBS secara khusus di sini. Mereka hanya berbicara tentang VM dan mengukur ketersediaan VM instance tunggal mereka menurut jam, bukan menurut bulan seperti yang dilakukan penyedia cloud lainnya. Demi diskusi, mari gunakan jaminan ketersediaan 99,9% yang telah dipublikasikan oleh Azure dan GCP. Membangun dari contoh kita sebelumnya, mari tambahkan beberapa penyimpanan ke persamaan. Ketersediaan komputasi 99,99% Ketersediaan penyeimbang beban 99,99% 99,9% disk yang dikelola .9999 * .9999 * .999 = .9988 Ketersediaan 99,88% = ~ 53 menit waktu henti per bulan. Waktu henti 53 menit jauh lebih banyak daripada waktu henti 9 menit yang kami hitung di contoh sebelumnya. Apa yang dapat kita lakukan untuk meminimalkan dampak dari ketersediaan penyimpanan 99,9%? Kami harus membangun lebih banyak redundansi dalam penyimpanan! Untungnya, kami biasanya menyertakan redundansi penyimpanan saat merencanakan ketersediaan aplikasi. Misalnya, saat kami menyiapkan server web, setiap server web biasanya akan menyimpan data pada disk yang terpasang secara lokal. Saat menyebarkan pengontrol domain, Microsoft Active Directory menangani penggandaan informasi AD di semua pengontrol domain. Dalam kasus seperti SQL Server, kami memanfaatkan Grup Ketersediaan Selalu Aktif atau SIOS DataKeeper untuk menjaga data tetap sinkron di seluruh disk yang terpasang secara lokal. Semakin banyak salinan data yang telah kami distribusikan ke berbagai zona ketersediaan, semakin besar kemungkinan kami dapat bertahan dari kegagalan. Misalnya, aplikasi yang menyimpan datanya di dua disk yang berbeda di zona ketersediaan yang berbeda akan mendapatkan keuntungan dari redundansi dan daripada ketersediaan 99,9%, aplikasi tersebut lebih cenderung mencapai ketersediaan penyimpanan sebesar 99,9999%. 1 – (.001 * .001) = .999999 Jika kita memasukkannya ke persamaan sebelumnya, gambar mulai terlihat sedikit lebih cerah. .9999 * .9999 * .999999 = .9998 Ketersediaan 99,98% = ~ 9 menit waktu henti Dengan menduplikasi data di beberapa AZ, dan oleh karena itu, beberapa disk, kami telah secara efektif mengurangi waktu henti yang terkait dengan penyimpanan cloud. Ketersediaan Aplikasi Dan Layanan BergantungAnda telah melakukan semua yang dapat Anda lakukan untuk memastikan ketersediaan komputasi, jaringan, dan penyimpanan. Tapi bagaimana dengan aplikasinya sendiri? Beberapa aplikasi dapat menskalakan dan menyediakan redundansi dengan load balancing antara beberapa contoh aplikasi yang sama. Pikirkan pertanian server web tipikal Anda di mana Anda biasanya dapat memuat permintaan web keseimbangan antara lima server. Jika Anda kehilangan satu server, penyeimbang beban hanya menghapusnya dari rotasinya hingga kembali responsif. Aplikasi lain membutuhkan lebih banyak perawatan dan pemantauan. Ambil contoh SQL Server. Biasanya Grup Ketersediaan Selalu Aktif atau Mesin Virtual Failover Cluster digunakan untuk memantau ketersediaan database dan melakukan tindakan pemulihan jika database menjadi tidak responsif karena kegagalan tingkat aplikasi atau sistem. Meskipun tidak ada SLA yang diterbitkan untuk solusi ketersediaan SQL Server, secara umum diterima bahwa ketika dikonfigurasi dengan benar untuk ketersediaan tinggi, SQL Server dapat menyediakan ketersediaan 99,99%. Anda dapat mengandalkan layanan berbasis cloud lainnya, seperti Active Directory yang dihosting, DNS yang dihosting, layanan mikro, atau bahkan ketersediaan portal cloud itu sendiri, semuanya harus diperhitungkan dalam persamaan ketersediaan Anda secara keseluruhan. RingkasanKetersediaan aplikasi adalah jumlah dari semua bagian yang bergerak. Menghemat hanya di satu area dapat secara eksponensial memengaruhi ketersediaan aplikasi Anda secara keseluruhan. Luangkan waktu Anda dan selidiki semua tautan dalam rantai ketersediaan Anda untuk menemukan kelemahan termasuk komputasi, jaringan, penyimpanan, aplikasi, dan layanan yang bergantung. Secara umum, angka yang disajikan di sini mudah-mudahan merupakan skenario kasus terburuk dan ketersediaan Anda yang sebenarnya harus melebihi SLA yang dipublikasikan. Kerjakan pekerjaan rumah Anda dan waspadalah terhadap layanan apa pun yang tidak dapat menjamin ketersediaan 99,99%, ambang umum dari apa yang dianggap sangat tersedia. Kesalahan manusia dan keamanan tidak dibahas dalam artikel ini. Anda dapat membuat aplikasi Anda tersedia semaksimal mungkin. Namun, jika Anda belum mengambil langkah untuk mengamankan aplikasi Anda dari ancaman eksternal dan kesalahan manusia yang bodoh, maka semua taruhan dibatalkan dalam hal ketersediaan. |
||||
| Desember 11, 2020 |
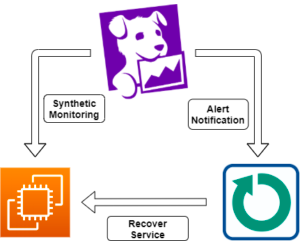
Menggunakan Datadog untuk Amazon EC2 Monitoring? Sandingkan dengan SIOS AppKeeper untuk Remediasi Otomatis |


 )
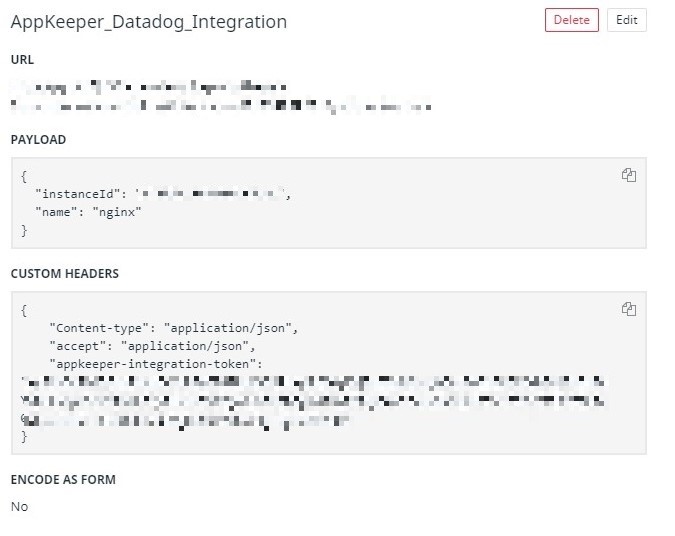
)| {
“InstanceId”: “{{EC2 Instance ID}}”, “Nama”: “nginx” } |
Header Khusus: Centang kotak dan masukkan yang berikut ini
| { “Jenis konten”: “application / json”, “Accept”: “application / json”, "Appkeeper-integration-token": "{{Dapatkan AppKeeper token integrasi eksternal Token yang diperoleh di}}" } |
Setelah selesai, tekan "Simpan".
Langkah Delapan: Menghubungkan AppKeeper ke tes Synthetics
Selanjutnya, saya harus mengonfigurasi AppKeeper (integrasi Webhooks terdaftar) untuk dipanggil ketika peringatan pemantauan Synthetics terjadi.
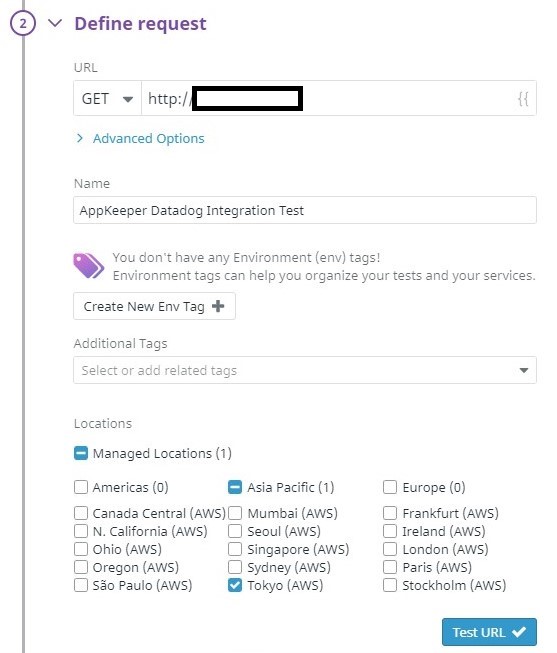
Buka kasus pengujian yang Anda siapkan di "Mengonfigurasi Pemantauan Sintetis dengan Datadog" dari Pemantauan UX> Pengujian Sintetis di menu.
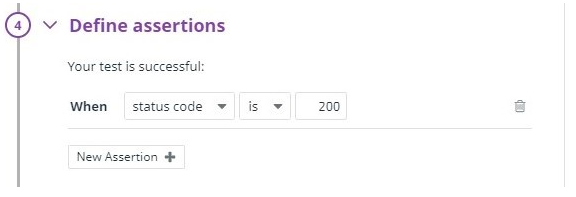
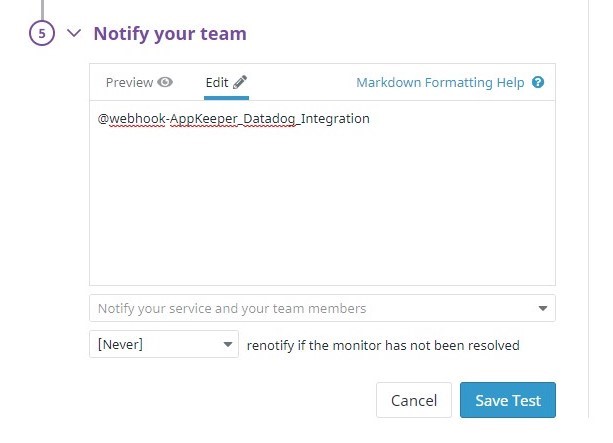
Pilih "Edit detail pengujian" dari kotak roda gigi kanan atas dan masukkan nilai berikut di "5. Beri tahu Tim Anda ”untuk menyimpan perubahan.
| @webhook – {{Nama integrasi Webhook di Datadog}} |
※ Anda dapat mengatur "renotify jika monitor belum diselesaikan".Anda dapat mencoba lagi jika AppKeeper gagal memulihkan untuk pertama kalinya.Ini tidak diperlukan untuk tujuan pengujian, tetapi kami menyarankan Anda untuk mengaturny[10 minutes]a ke (interval minimum).
Penyiapan sekarang selesai.
Langkah Sembilan: Konfirmasikan integrasi dengan menjalankan tes lagi
Saya kemudian mengonfirmasi bahwa AppKeeper akan memulihkan server web jika Datadog mendeteksinya tidak aktif.
Buka kasus uji pemantauan Synthetics yang baru saja Anda siapkan dari UX Monitoring> Synthetic Tests di Datadog.
Klik "Lanjutkan Tes" di pojok kanan atas dan aktifkan pemantauan Synthetics.

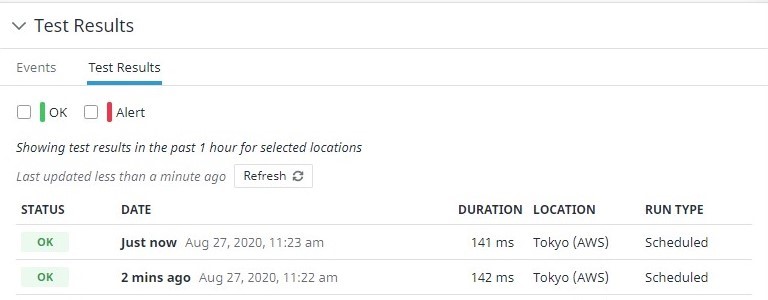
Sekarang Datadog akan melakukan pemantauan Synthetics secara berkala.
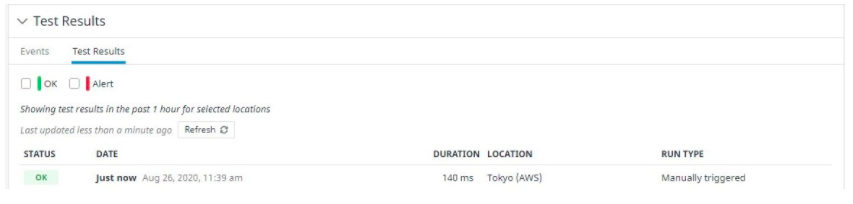
Hasil Tes menunjukkan bahwa server berhasil diakses.
Selanjutnya, saya membuat server web pseudo-failure untuk menguji remediasi otomatis AppKeeper.
Karena sulit untuk menyebabkan kegagalan yang nyata, saya menghentikan layanan dan membuat situasi di mana Anda tidak dapat melihat halaman web.Untuk melakukan ini, saya terhubung ke instance EC2 di mana server Nginx diinstal menggunakan SSH dan menghentikan Nginx.
| sudo systemctl menghentikan nginx |
Setelah menunggu sebentar, Datadog mendeteksi bahwa server web tidak dapat diakses lagi.
Halaman Tes Sintetis di Datadog juga menunjukkan bahwa kasus pengujian telah gagal.
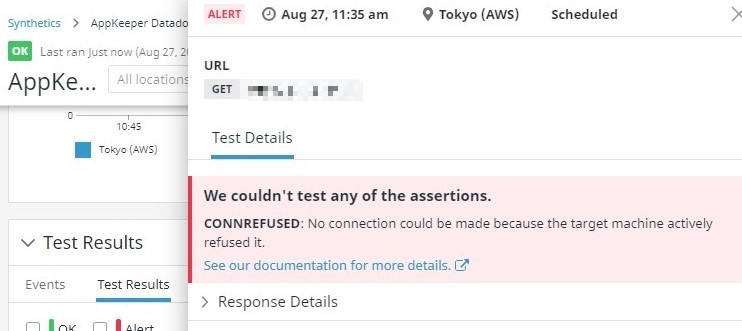
Jika kasus uji gagal, Datadog akan memberi tahu AppKeeper bahwa pemantauan Synthetics telah gagal.
Ketika AppKeeper menerima notifikasi, secara otomatis akan mencoba untuk memulai ulang Nginx.
Jadi, jika Anda menunggu sebentar, Anda akan melihat bahwa pemeriksaan pemantauan Sintetik Datadog akan lulus lagi.
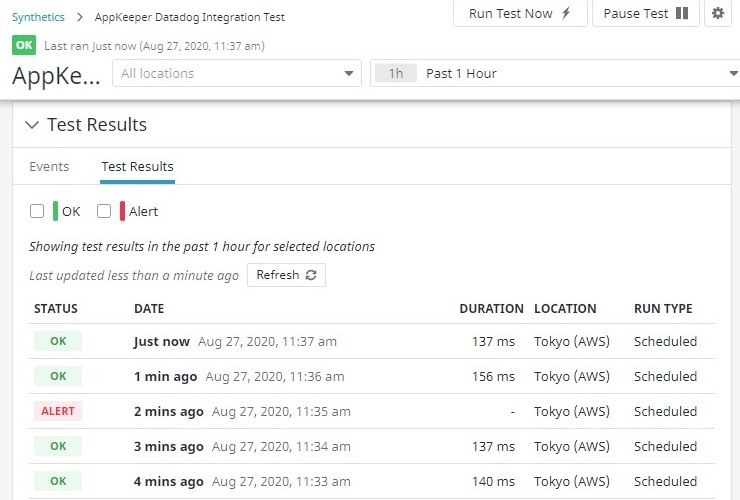
Selain itu, jika Anda masuk ke dasbor AppKeeper, Anda akan melihat bahwa pemulihan telah dilakukan.

–
Dalam latihan ini saya menggunakan server web (Nginx) sebagai contoh untuk mengotomatiskan proses mendeteksi kegagalan dengan Datadog dan memulihkan layanan dengan AppKeeper.
Otomatisasi serupa dapat dicapai dengan mengintegrasikan Datadog dengan EventBridge dan Lambda atau dengan membuat skrip khusus.
Namun, jika Anda sering menambahkan instans target atau memulai ulang berbagai layanan, biaya dan kerumitan pemeliharaan EventBridge dan Lambda atau skrip akan meningkat.
Integrasi AppKeeper yang telah terbukti dengan Datadog dan kemudahan untuk menambahkan instance target ke aplikasi Anda membuatnya mudah untuk menambahkan otomatisasi ke lingkungan DevOps Anda untuk mengurangi waktu henti.
Jika saat ini Anda menggunakan Datadog dan ingin mencoba AppKeeper's Restart API, harap daftar dulu untuk uji coba gratis 14 hari kami di sini (Anda dapat membeli langganan setelah menginstal uji coba gratis).Kemudian klik di sini untuk meminta uji coba gratis. Kami akan memandu Anda melalui proses dan memberi Anda token evaluasi gratis untuk membantu Anda memulai.
Ajukan permohonan token evaluasi
Terima kasih.Saya harap Anda akan mengambil kesempatan ini untuk mempelajari lebih lanjut tentang SIOS AppKeeper, yang menyediakan pemantauan otomatis dan pemulihan aplikasi yang berjalan di EC2.
– Tatsuya Hirao di tim teknis Teknologi SIOS.
Direproduksi dengan izin dari SIOS
5 Tanda Bahwa Diperlukan Lebih Dari Satu Posting Blog Untuk Memperbaiki Ketersediaan Tinggi Anda

5 Tanda Bahwa Diperlukan Lebih Dari Satu Posting Blog Untuk Memperbaiki Ketersediaan Tinggi Anda
Tanda-tandanya ada di sana. Lampu peringatan berkedip.Di dalam perut Anda, Anda bisa merasakannya. Mungkin Anda tidak bisa tidur.Masalah Anda dengan ketersediaan tinggi sangat dalam. Tapi, mungkin Anda kurang yakin.
1. Jika menurut Anda cloud SLA adalah semua yang Anda butuhkan untuk ketersediaan tinggi
Solusi cloud telah memberikan kemajuan besar dalam peningkatan ketersediaan dan ketahanan perangkat keras. Namun, ketersediaan tinggi aplikasi membutuhkan lebih dari sekadar memilih hypervisor atau penyedia cloud yang tepat. Strategi Anda untuk ketersediaan tinggi tidak dapat berhenti dengan SLA yang disediakan oleh cloud atau penyedia virtualisasi. Seperti dikutip oleh Wired, "Penghentian Amazon selama hampir empat hari pada April 2011 tidak melanggar SLA EC2 Amazon, yang dijelaskan oleh FAQ," menjamin 99,95% ketersediaan layanan dalam suatu Wilayah selama periode 365 yang tertinggal. " Dalam artikel DZone ini, David Bermingham kami menjelaskan secara mendetail perbedaan antara cloud SLA dan ketersediaan aplikasi. Jika Anda menginginkan infrastruktur yang sangat tersedia, itu harus mencakup pemantauan, pemulihan, dan ketahanan pada lapisan data dan aplikasi juga.
2. Jika Anda hanya menggunakan pengelompokan ketersediaan tinggi yang disertakan dengan sistem operasi sumber terbuka Anda
Jika demikian, maka kemungkinan Anda tidak memilih database Anda berdasarkan apa yang dibundel dengan OS, jadi mengapa Anda memilih solusi HA berdasarkan kriteria itu saja. Alat yang dibundel sangat membantu dalam memberikan jaminan, kemungkinan, dan kemampuan ekstra. Namun, terlepas dari kemudahan akses, alat yang dibundel dan perangkat lunak pengelompokan OS tidak selalu mampu memenuhi persyaratan SLA, RPO, RTO, dan ketersediaan Anda. Jika perusahaan Anda memiliki kombinasi Sistem Operasi, tim Anda kemungkinan akan membutuhkan bantuan untuk menjelajahi berbagai alat dan memahami bagaimana mereka berintegrasi. Ini seperti memilih gunting tanaman dan mendorong mesin pemotong rumput ke kiri di tepi jalan untuk membentuk "Azalea" di lubang ke-13 par 5 (di Augusta). Kedua mesin pemotong rumput dirancang untuk memotong rumput, tetapi berapa banyak waktu yang Anda miliki? Bagaimana Anda akan menangani kompleksitas? Mana yang akan Anda percayai? Strategi Anda untuk ketersediaan tinggi membutuhkan lebih dari sekadar mempertimbangkan kemudahan dari apa yang dibundel dengan OS, jika tidak, Anda akan menjalankan MySQL alih-alih SAP HANA.
3. Jika menurut Anda lisensi aplikasi perusahaan, seperti SQL Enterprise atau Oracle Enterprise, sama dengan ketersediaan tinggi perusahaan
Selain peningkatan biaya, banyak lisensi aplikasi perusahaan juga meningkatkan kemampuan aplikasi untuk pulih dalam beberapa skenario ketersediaan tinggi. Namun, sangat tidak mungkin seluruh perusahaan Anda didasarkan pada satu aplikasi. Ketersediaan tinggi Anda akan membutuhkan lebih dari sekedar solusi database yang sangat tersedia. Anda akan memerlukan solusi pemulihan dan pemantauan aplikasi tingkat perusahaan dengan dukungan luas untuk semua aplikasi dan database Anda. Selain itu, Anda memerlukan kemampuan untuk mengelola dan mereplikasi tidak hanya data database, tetapi juga aplikasi penting dan data konfigurasi. Ketersediaan untuk satu database atau aplikasi sederhana adalah satu hal – tetapi HA untuk aplikasi multipart yang kompleks dan database pendukung sangat berbeda. Lebih banyak layanan, lebih banyak bagian yang perlu dikoordinasikan, arsitektur yang lebih kompleks untuk diatur, praktik terbaik yang lebih spesifik untuk dipatuhi sebelum, selama dan setelah failover / peralihan. Lebih dari apa yang dibayar lisensi perusahaan Anda.
4. Jika waktu henti Anda bertambah dan waktu kerja Anda menyusut
Laju kehidupan semakin meningkat di berbagai bidang. Kapan terakhir kali tim Anda memulihkan dari cadangan, secara manual memulai ulang aplikasi yang dianggap penting, atau memulai ulang serangkaian mesin virtual atau node yang gagal? Laju peristiwa pemadaman Anda tidak dapat terus melebihi keberlanjutan, atau kemampuan tim Anda untuk bergerak dari pemadaman kebakaran ke pencegahan kebakaran dan pemeriksaan kebakaran. "Anda hanya bisa berlari begitu keras selama ini (Carey Nieuwhof)." Untuk beberapa dari Anda, Anda telah melakukan pemadam kebakaran terlalu lama, dan pemadaman Anda menjadi lebih umum daripada waktu aktif Anda.
5. Jika pengujian failover pertama Anda dilakukan di server produksi
Seorang klien baru-baru ini mengatakan bahwa tidak mungkin menguji setiap kemungkinan skenario bencana. Saat perangkat lunak baru dibuat, diterapkan, diperbarui, dan ditambal, tantangan dalam ketersediaan yang lebih tinggi semakin meningkat. Tapi, data produksi dan live Anda bukanlah tempat untuk mencari tahu apa yang tidak berjalan baik bersama. Dan sementara Go-Live dan Post-Go-Live akan selalu memiliki kejutan, ketidakmampuan untuk benar-benar melakukan failover dan berjalan di node cadangan seharusnya tidak menjadi salah satunya.
Menjelajahi blog dapat memberi Anda tip dan wawasan yang berguna untuk mendefinisikan, mendefinisikan ulang, dan meningkatkan ketersediaan Anda yang lebih tinggi. Tetapi, jika tanda peringatan berbunyi bahwa Anda telah memperdagangkan ketersediaan yang sebenarnya untuk beberapa kemiripan 'cukup', maka itu akan membutuhkan lebih dari satu posting blog, atau menjelajahi setiap posting blog di dunia ketersediaan dalam hal ini, untuk memperbaikinya HA Anda.
– Cassius Rhue, Wakil Presiden, Pengalaman Pelanggan
Direproduksi dengan izin dari SIOS
9 Tanda Anda Memiliki Masalah Ketersediaan Aplikasi

SIOS AppKeeper sekarang tersedia di AWS Marketplace

SIOS AppKeeper sekarang tersedia di AWS Marketplace
Mempermudah penambahan remediasi otomatis ke lingkungan DevOps Anda.
Hari ini kami dengan bangga mengumumkan bahwa solusi SIOS AppKeeper kami sekarang tersedia di AWS Marketplace, katalog digital dengan ribuan daftar perangkat lunak dari vendor perangkat lunak independen yang memudahkan untuk menemukan, menguji, membeli, dan menerapkan perangkat lunak yang berjalan di Amazon Web Services (AWS). Sekarang lebih mudah dari sebelumnya bagi pengguna akhir dan anggota AWS Partner Network (APN) untuk mencoba, memperoleh, dan menerapkan SIOS AppKeeper untuk menambahkan remediasi otomatis ke lingkungan DevOps mereka.Klik di sini untuk melihat AppKeeper di AWS Marketplace.
SIOS AppKeeper terus memantau dan melindungi aplikasi Anda yang berjalan di Amazon EC2. Kami telah menjual AppKeeper di Jepang sejak 2017 dan membawa layanan SaaS ke pasar AS awal tahun ini.Kami membuat AppKeeper sebagai tanggapan atas permintaan yang kami dengar dari pelanggan kami yang pindah ke cloud dan khawatir tentang mengurangi potensi waktu henti sementara berjuang dengan sumber daya yang terbatas. Klik di sini jika Anda ingin melihat video tentang betapa mudahnya menginstal dan menggunakan AppKeeper.

Pemantauan Aplikasi AWS EC2 – SIOS AppKeeper | SIOS
Seberapa sering pengguna Amazon EC2 mengalami waktu henti? Menurut data pelanggan kami, rata-rata pelanggan dengan hanya tiga instans Amazon EC2 mengalami waktu henti setidaknya sebulan sekali.Itu bisa jadi karena kesalahan konfigurasi perangkat lunak, dll.
Melampaui pemantauan aplikasi untuk menawarkan remediasi otomatis
Banyak pengguna AWS menerapkan solusi pemantauan kinerja aplikasi (APM), seperti dari AppDynamics, Datadog, Dynatrace atau New Relic, untuk memantau lingkungan AWS mereka.Tapi ini hanya mengingatkan Anda pada fakta bahwa sesuatu terjadi, dan mengapa itu terjadi. Mereka tidak melakukan apa pun untuk mengurangi waktu henti Anda.
Di situlah AppKeeper berperan. Jika AppKeeper mendeteksi waktu henti dengan layanan aplikasi apa pun yang berjalan di Amazon EC2, AppKeeper akan merespons secara otomatis dengan memulai ulang layanan yang terpengaruh dan me-reboot instans jika perlu. AppKeeper mengatasi 85% kegagalan layanan aplikasi. Mengurangi kebutuhan akan pemantauan atau gangguan outsourcing yang mahal untuk tim TI Anda dengan pemulihan otomatis.Pelajari lebih lanjut tentang otomatisasi APM dari AppKeeper.
Pelanggan AWS yang sudah menggunakan solusi APM dan ingin memperluas fungsionalitas untuk menyertakan remediasi otomatis, jika dan ketika waktu henti Amazon EC2 terdeteksi, dapat memanfaatkan API webhooks AppKeeper untuk berintegrasi dengan solusi APM pilihan mereka.
Mengapa kami memutuskan untuk mendaftarkan SIOS AppKeeper ke AWS Marketplace
Di sini, di SIOS Technology Corporation kami telah memiliki kemitraan strategis dengan Amazon AWS sejak 2014, terutama seputar solusi ketersediaan tinggi SIOS DataKeeper dan SIOS LifeKeeper.Teknologi SIOS adalah APN Advanced Partner hari ini, dan kami berbagi 100 pelanggan bersama.
Sekarang kami memiliki bukti pelanggan untuk keefektifan SIOS AppKeeper (berikut adalah beberapa studi kasus terbaru yang mungkin Anda nikmati), kami ingin mempermudah pelanggan Amazon dan mitra APN untuk mencoba, membeli, dan menggunakan AppKeeper.Menurut banyak perkiraan, ada lebih dari 200.000 pelanggan AWS aktif yang menggunakan perangkat lunak dari AWS Marketplace, yang semuanya memanfaatkan betapa mudahnya AWS Marketplace untuk menemukan, memperoleh, dan menggunakan solusi pelengkap saat mereka melanjutkan perjalanan cloud mereka.
Dan teman-teman kami di Amazon tidak dapat mengatakannya dengan lebih baik: "Karena pelanggan kami memigrasi semakin banyak aplikasi ke cloud, mereka mencari fleksibilitas dalam menyeimbangkan tingkat ketersediaan dengan biaya di semua aplikasi mereka," kata Chris Grusz, Director, AWS Marketplace, Amazon Web Services, Inc. "Kami dengan senang hati menyambut SIOS AppKeeper di AWS Marketplace dan memberikan lebih banyak pilihan kepada pelanggan kami saat perubahan kinerja terjadi."
Pelanggan AWS yang tertarik untuk melindungi aplikasi EC2 mereka dari waktu henti yang tidak perlu sekarang dapat dengan cepat mencoba AppKeeper untuk diri mereka sendiri, dan dapat memperoleh AppKeeper di bawah Paket Diskon Amazon Enterprise mereka, jika mereka sudah memilikinya.Harga untuk SIOS AppKeeper mulai dari hanya US $ 40 per instans, per bulan.
Mitra sekarang mengintegrasikan AppKeeper ke dalam solusi pelanggan mereka
Berbagai mitra sekarang mengintegrasikan AppKeeper ke dalam solusi pelanggan mereka, dan memiliki AppKeeper yang tersedia di AWS Marketplace berarti akan lebih mudah bagi anggota APN untuk mengevaluasi apakah solusi tersebut sesuai untuk bisnis dan pelanggan mereka. Penyedia Layanan Terkelola (MSP) mulai menyertakan AppKeeper ke dalam cara mereka memantau dan mengelola lingkungan AWS pelanggan mereka, sebagai cara untuk mengurangi waktu henti dan biaya operasional mereka sendiri.ISV lainnya mengintegrasikan fungsionalitas remediasi otomatis AppKeeper ke dalam solusi manajemen cloud mereka sendiri, dan AWS Consulting Partner mengemas AppKeeper saat mereka mengembangkan dan menerapkan aplikasi di AWS untuk pelanggan mereka.
Anggota APN yang tertarik untuk mengevaluasi apakah AppKeeper cocok untuk bisnis mereka harus menghubungi kami melalui email di d-yoshioka@us.sios.com.
Kami berharap Anda akan mencoba SIOS AppKeeper untuk diri Anda sendiri (kami memiliki uji coba gratis selama 14 hari dan proses instalasi yang mudah), dan bergabunglah dengan banyak pelanggan yang sekarang santai mengetahui bahwa mereka memiliki remediasi otomatis untuk mengurangi waktu henti Amazon EC2 yang mereka mungkin mengalami.