| Mei 14, 2022 |
SLA Ketersediaan: FT, Ketersediaan Tinggi, dan Pemulihan Bencana – Mulai dari mana |
| Mei 9, 2022 |
Cara Menghindari Kemacetan IO: Panduan Penempatan Log Intent DataKeeper untuk Penerapan Cloud Windows |
| Mei 5, 2022 |
Platform Media Terkemuka Melindungi SAP S/4 HANA Penting di AWS EC2 Cloud |
| Mei 1, 2022 |
Lindungi Sistem dari Waktu Henti |
| April 29, 2022 |
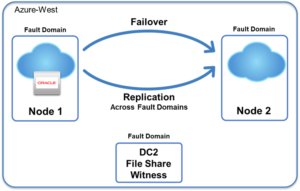
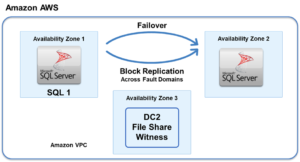
Cara Mencapai Ketersediaan Tinggi di Cloud Menggunakan WSFC |

 Wajar untuk mengatakan bahwa di era modern ini di mana banyak aspek kehidupan kita didorong oleh teknologi, kita hidup di dunia yang sangat instan.Misalnya, dengan mengklik tombol, pesanan bahan makanan mingguan kami tiba di depan pintu kami.Kami dapat langsung membeli tiket untuk acara atau perjalanan.Atau bahkan akhir-akhir ini, pesan mobil baru tanpa harus pergi ke mana pun di dekat ruang pamer dan berurusan dengan wiraniaga yang memaksa. Kita dimanjakan dalam dunia kenyamanan ini.
Wajar untuk mengatakan bahwa di era modern ini di mana banyak aspek kehidupan kita didorong oleh teknologi, kita hidup di dunia yang sangat instan.Misalnya, dengan mengklik tombol, pesanan bahan makanan mingguan kami tiba di depan pintu kami.Kami dapat langsung membeli tiket untuk acara atau perjalanan.Atau bahkan akhir-akhir ini, pesan mobil baru tanpa harus pergi ke mana pun di dekat ruang pamer dan berurusan dengan wiraniaga yang memaksa. Kita dimanjakan dalam dunia kenyamanan ini.