| Juni 23, 2022 |
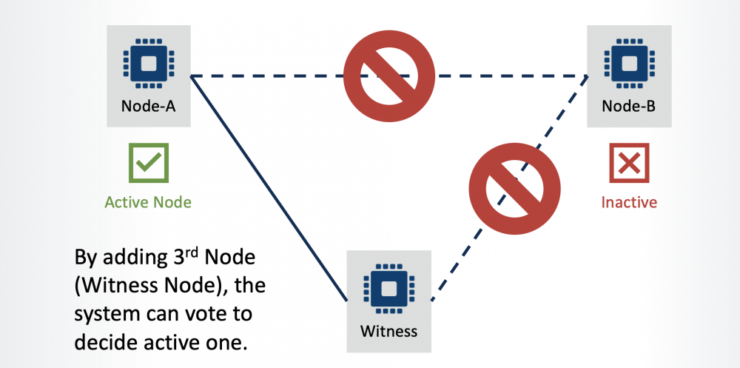
Apa itu "Otak Terbelah" dan Bagaimana Menghindarinya |
| Juni 19, 2022 |
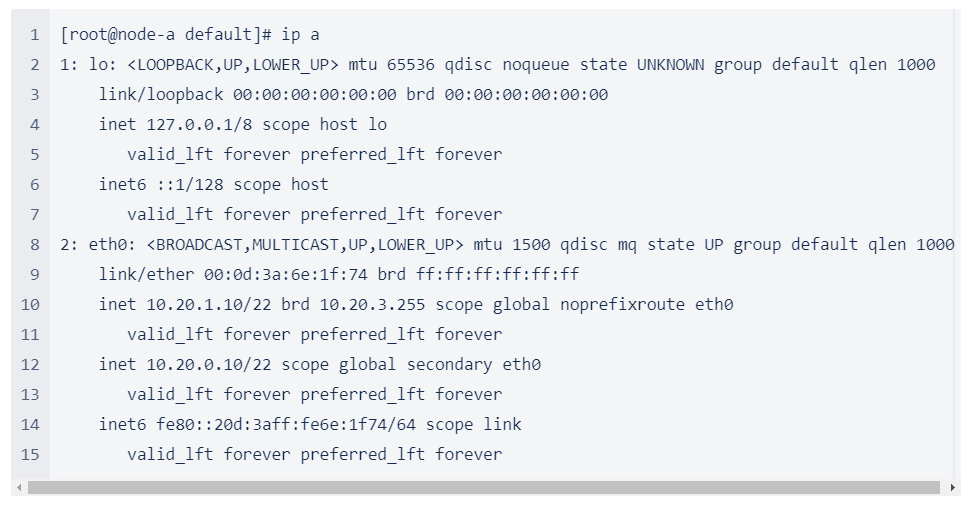
Bagaimana Replikasi Data antar Node Bekerja? |
| Juni 15, 2022 |
Bagaimana Klien Terhubung ke Node Aktif |
| Juni 11, 2022 |
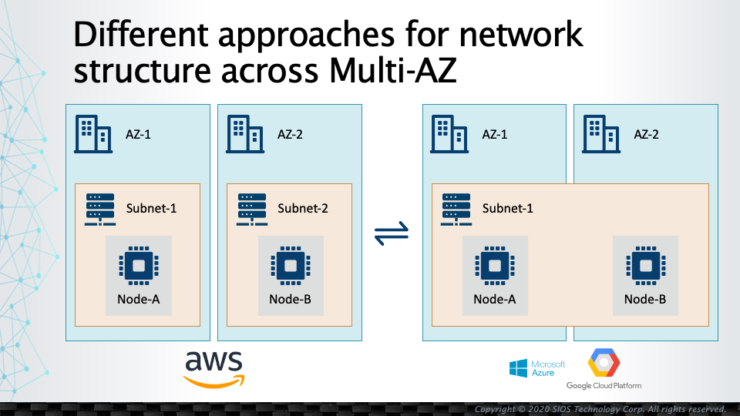
Platform Cloud Publik dan Perbedaan Struktur Jaringannya |
| Juni 7, 2022 |
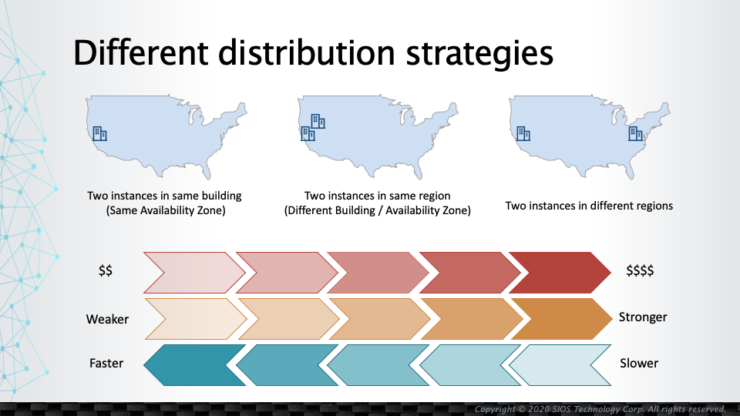
Bagaimana Beban Kerja Harus Didistribusikan saat Bermigrasi ke Lingkungan Cloud |