| Juli 24, 2022 |
Ringkasan Solusi: Ketersediaan Tinggi untuk SAP S4/HANA |
||||||
| Juli 17, 2022 |
Lembar Fakta: Ketersediaan Tinggi BMS |

 Perangkat lunak pengelompokan SIOS SAN dan SANless memberikan perlindungan bersertifikat SAP yang komprehensif untuk aplikasi dan data Anda, termasuk: ketersediaan tinggi , replikasi data , dan pemulihan bencana dalam solusi yang mudah dan hemat biaya.
Perangkat lunak pengelompokan SIOS SAN dan SANless memberikan perlindungan bersertifikat SAP yang komprehensif untuk aplikasi dan data Anda, termasuk: ketersediaan tinggi , replikasi data , dan pemulihan bencana dalam solusi yang mudah dan hemat biaya.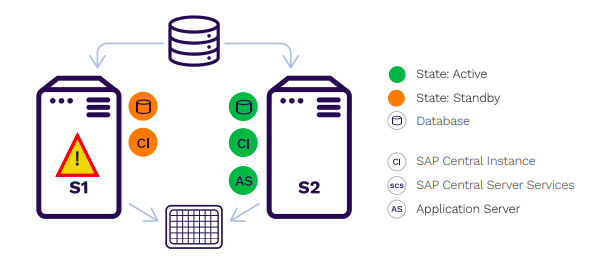

Penjaga Data SIOSTambahkan SIOS DataKeeper ke lingkungan Windows Server Failover Clustering untuk membuat cluster SANless di mana cluster penyimpanan bersama tradisional tidak mungkin atau tidak praktis, seperti lingkungan cloud dan hybrid cloud. Replikasi berbasis host yang cepat dan efisien menyinkronkan penyimpanan lokal di semua node cluster untuk fleksibilitas konfigurasi maksimum. Atau, tambahkan replikasi ke klaster Windows berbasis SAN yang ada untuk DR. Gunakan perangkat lunak SIOS DataKeeper Cluster Edition untuk melindungi aplikasi Windows dan sistem BMS yang sangat penting bagi bisnis Anda dan database yang dijalankannya, termasuk Microsoft SQL Server, Oracle, dalam lingkungan fisik, virtual, atau cloud.
|
Suite Perlindungan SIOSSuite Perlindungan SIOS untuk Linux memungkinkan Anda menjalankan aplikasi EHR penting bisnis Anda di tempat atau di lingkungan cloud yang fleksibel dan dapat diskalakan, seperti Amazon Web Services (AWS) dan Microsoft Azure tanpa mengorbankan kinerja atau perlindungan HA/DR. SIOS mengelompokkan failover unik di seluruh wilayah cloud atau zona ketersediaan untuk perlindungan HA yang sebenarnya.
|
HA/DR untuk Lembar Fakta Sistem Manajemen Gedung
Sistem BMS Dilindungi
|
Lingkungan & Platform Dilindungi
|
Database dan ERP DilindungiSQL Server, SAP, SAP S/4HANA, Oracle, SharePoint Belajarlah lagi
|
Studi Kasus KesehatanPusat Perawatan Kanker Rumah Sakit Chris O'Brien, Rumah Sakit Allyn, Rumah Sakit Carroll, Penyedia Layanan Kesehatan Terkemuka. Belajarlah lagi |
- Dapatkan uji coba gratis SIOS High Availability dan Disaster Recovery Clustering Software
- Pelajari lebih lanjut tentang SIOS DataKeeper
- Unduh Lembar Fakta PDF
Direproduksi dengan izin dari SIOS
SIOS LifeKeeper – Ketersediaan Tinggi untuk Linux

SIOS LifeKeeper – Ketersediaan Tinggi untuk Linux
Perusahaan yang menjalankan aplikasi penting bisnis seperti SAP, S/4 HANA, SQL Server, MaxDB dan Oracle menghadapi dilema. Bahkan periode waktu henti yang singkat untuk beban kerja yang kompleks ini dapat memiliki konsekuensi bencana. Tetapi pengelompokan HA tradisional bisa rumit dan mahal. Pindah ke cloud bukanlah jawaban karena SLA ketersediaan cloud hanya mencakup perangkat keras. Mereka tidak dapat menyediakan HA dan DR untuk aplikasi stateful tanpa menurunkan kinerja di cloud. Penyimpanan bersama yang digunakan dalam pengelompokan lokal tradisional bukanlah pilihan di beberapa cloud dan terlalu rumit dan mahal di cloud lain untuk menjadi praktis. Banyak solusi pengelompokan HA tidak dapat gagal di wilayah cloud dan zona ketersediaan – membatasi tingkat pemulihan bencana yang dapat mereka berikan. Pengelompokan Open Source bukanlah jawabannya. Ini membutuhkan skrip yang rumit dan rentan terhadap kesalahan dan kegagalan manusia. Langkah-langkah manual yang diperlukan untuk memastikan kegagalan ERP atau database yang kompleks dapat berjalan dengan benar. Tim TI ragu-ragu untuk melakukan pemeliharaan rutin dan pengujian failover.
SIOS punya Solusinya.
SIOS LifeKeeper memberikan ketersediaan tinggi dan pemulihan bencana yang memastikan sistem, database, dan aplikasi beroperasi kapan dan sesuai kebutuhan.
- Kit pemulihan yang unik dan sadar aplikasi membuat dan mengelola cluster ketersediaan tinggi di lingkungan yang kompleks seperti SAP, S/4 HANA, SQL Server, MaxDB, dan Oracle menjadi mudah dan bebas kesalahan.
- pemantauan lengkap, tidak seperti solusi HA yang hanya memantau operasi server, SIOS LifeKeeper memantau jaringan tumpukan aplikasi, penyimpanan, OS, dan aplikasi.
- Teknologi canggih yang sadar aplikasi mengotomatiskan konfigurasi dan memvalidasi input – memungkinkan konfigurasi yang akurat lima kali lebih cepat daripada perangkat lunak pengelompokan sumber terbuka dan memastikan failover dapat diandalkan dan mempertahankan praktik terbaik aplikasi.
Di cloud, kluster SIOS gagal di seluruh wilayah dan Availability Zone untuk perlindungan DR maksimum. Untuk pelanggan yang ingin menerapkan beberapa cluster, fitur kloning SIOS LIfeKeeper memungkinkan Anda membuat beberapa cluster identik menggunakan pengaturan standar yang konsisten dan praktik terbaik terintegrasi. SIOS LIfeKeeper hadir dalam bundel yang disebut SIOS Protection Suite yang mencakup kit pemulihan khusus aplikasi dan replikasi yang efisien untuk pengelompokan SANless dan DR. Dapatkan ketersediaan 99,99% dan perlindungan bencana untuk beban kerja Windows atau Linux kritis yang berjalan di lingkungan lokal, di cloud, atau hybrid cloud.Jadwalkan demo atau daftarkan dirimu percobaan gratis hari ini.

Direproduksi dengan izin dari SIOS
Pelajaran Ketersediaan Tinggi dari Disney dan Pixar’s Soul

Pelajaran Ketersediaan Tinggi dari Disney dan Pixar’s Soul
Dalam Disney dan Pixar’s Soul, karakter utama Joe Gardner (disuarakan oleh Jamie Foxx) bermimpi menjadi pianis jazz profesional.Namun, terlepas dari banyak upayanya, yang membuat ibunya cemas, dia mendapati dirinya bermil-mil jauhnya dari mimpinya, hidup sebagai “guru band sekolah menengah setengah baya.” Tapi kemudian, “berkat kesempatan menit terakhir untuk bermain dalam kuartet legenda jazz Dorothea Williams, mimpinya sepertinya akan menjadi kenyataan.Itu sampai “salah langkah yang menentukan mengirimnya ke The Great Before—tempat di mana jiwa mendapatkan minat, kepribadian, dan kebiasaan mereka—dan Joe dipaksa untuk bekerja dengan “22”, jiwa kuno yang tidak tertarik untuk hidup di bumi, untuk “entah bagaimana kembali ke Bumi sebelum terlambat ( D23.com ).” Disney and Pixar’s Soul adalah film hebat dengan banyak karakter yang menarik dan dapat dihubungkan, lucu, deskriptif, dan kadang-kadang mengganggu yang berhubungan dengan kehidupan, tujuan, dan kehidupan.Tapi, itu juga film dengan kekayaan pelajaran kepemimpinan , pelajaran hidup, dan pelajaran tentang ketersediaan yang lebih tinggi.
Tujuh pemikiran tentang ketersediaan yang lebih tinggi dari Disney dan Pixar’s Soul.
1. Perhatikan apa yang terjadi
Di Disney dan Pixar’s Soul, Joe mendapatkan pertunjukan impiannya.Tetapi ketika Joe mulai berjalan dan berbagi berita bagus, dia begitu sibuk dengan teleponnya sehingga dia berjalan ke jalan, hampir tertimpa satu ton batu bata, dan kemudian dia mengembara dengan berbahaya menuju lubang got yang terbuka, tetapi ditandai dengan jelas.Jadi apa pelajaran untuk ketersediaan yang lebih tinggi– perhatikan.Perhatikan peringatan dan pesan kesalahan dari solusi pemantauan dan pemulihan Anda.Perhatikan perubahan yang dibuat oleh penyedia hosting Anda, dan terutama pemberitahuan penting dari vendor dan mitra serta tim keamanan.Peringatan dan peringatan ada karena suatu alasan, gagal mengatasinya atau mengambil tindakan yang tepat ketika Anda melihat peringatan itu dapat membawa Anda ke lubang yang dalam.
2. Jangan jatuh ke dalam lubang
Tidak menyadari peringatan, atau mengabaikannya, Joe akhirnya menemui ajalnya ketika dia jatuh ke dalam lubang terbuka dan menjadi jiwa.Ini segera mengubah mimpi dan rencananya.Jadi, lubang apa yang bisa dimasuki perusahaan Anda?Apakah ada lubang terbuka yang mengintai di jalur perusahaan Anda seperti: lubang cakupan, kesenjangan versi, lubang dalam rencana dan kenyataan pemeliharaan, atau bahkan lubang hitam dengan respons vendor?Lihatlah ke sekeliling lingkungan Anda, lubang apa yang bisa membuat Anda jatuh di luar titik kegagalan yang jelas?Apakah ada peringatan bahwa Anda memiliki lubang terbuka terkait dengan aplikasi penting yang tidak dilindungi, kesenjangan komunikasi antara tim Anda, atau bahkan lubang dalam proses dan manajemen krisis Anda.Jangan jatuh ke dalam lubang yang dapat merusak atau bahkan mengakhiri ketersediaan tinggi .
3. Jangan terburu-buru ketersediaan tinggi
Setelah menjadi jiwa, Joe mulai aktif mencoba kembali ke tubuhnya sendiri.Ketika dia dipasangkan dengan 22, dia membawanya ke Moonwind yang setuju untuk mencoba membantunya menemukan tubuhnya, yang mereka lakukan.Tapi Joe menjadi terlalu bersemangat untuk melompat kembali ke tubuhnya, meskipun Moonwind berhati-hati.Dalam ketergesaannya dia dan 22 jatuh kembali ke bumi, tetapi Joe berakhir di tubuh kucing dan 22 berakhir di tubuhnya.Seperti Joe jika kita tidak sabar, lompatan terjadi terlalu cepat dan kita berakhir dalam situasi genting atau bahkan lebih buruk.Kita mungkin tidak berada dalam tubuh kucing, tetapi kita mungkin juga jauh dari posisi terbaik yang diperlukan untuk mempertahankan HA.Melompat terlalu cepat terlihat seperti:
- Menyebarkan perangkat lunak tanpa arsitektur atau solusi holistik
- Menyebarkan dalam produksi tanpa pengujian di QA
- Menyebarkan ke cloud tanpa memahami cloud atau apa yang dimaksud cloud dengan HA
- Menyebarkan ke produksi berdasarkan garis waktu dan tidak menyelesaikan tes penerimaan
- Menerapkan tanpa tujuan, solusi kelas komersial untuk pemantauan dan orkestrasi aplikasi
4. Jangan berhenti terlalu cepat – ketersediaan tinggi tidak pernah mudah
Ketika Connie, seorang pemain trombon muda, datang ke apartemen gurunya, dia frustrasi dan ingin berhenti.Dia mulai dengan memberi tahu Joe (yang sebenarnya berusia 22 tahun dalam tubuh Joe) bahwa dia frustrasi dan dia hanya ingin menyerah dan berhenti.Tetapi setelah beberapa saat, dia memainkan satu bagian terakhir pada trombon dan menyadari bahwa terlalu dini untuk berhenti.Dalam ketersediaan yang lebih tinggi, kita semua sangat mirip dengan Connie. Terkadang, sebuah kesulitan membuat kita merasa seperti berada di ujung tali kita dan ingin berhenti.Terkadang pemadaman akan membuat kita merasa yakin bahwa inilah saatnya untuk menyerah. Jangan terlalu cepat untuk berhenti.HA tidak pernah mudah, tidak pernah!Tapi, selalu terlalu dini untuk berhenti berjuang untuk mengakhiri waktu henti, jadi seperti Connie, mungkin kita hanya perlu terus melakukannya.Yang membawa saya ke pelajaran berikutnya.
5. Anda belum mencoba semuanya
Dalam film 22 adalah jiwa yang belum hidup.Dia percaya bahwa dia telah mencoba semua hal yang mungkin untuk memberinya percikan, tetapi ketika dia jatuh ke tubuh Joe, dia menyadari ada banyak hal yang belum dia coba.Dalam menciptakan solusi ketersediaan yang lebih tinggi, mungkin mudah untuk merasa seperti Anda telah mencoba segalanya dan setiap produk, tetapi kemungkinan besar Anda belum mencoba.Perspektif baru, atau melihat tantangan dan masalah dengan pandangan baru dapat membantu Anda meningkatkan ketersediaan sistem dan perusahaan Anda.
Beberapa hal yang perlu dicoba untuk ketersediaan yang lebih tinggi bisa sederhana, seperti:
- Siapkan lansiran tambahan untuk metrik pemantauan utama
- Tambahkan analitik.
- Lakukan perawatan rutin (tambalan, pembaruan, perbaikan keamanan)
- Dokumentasikan proses Anda
- Dokumentasikan buku pedoman operasional Anda
- Tingkatkan jalur komunikasi Anda
- Lakukan perawatan rutin
Ide-ide lain mungkin memerlukan lebih banyak pekerjaan, penelitian, waktu, dan uang, tetapi dapat bermanfaat jika Anda belum menjelajahinya di masa lalu.
Cara untuk meningkatkan ketersediaan Anda yang lebih tinggi dengan lebih banyak waktu dan upaya meliputi:
- Hapus peretasan dan solusi.
- Buat arsitektur solusi berulang yang solid
- Go komersial dan tujuan dibangun
- Sewa konsultan
- Audit dan dokumentasikan arsitektur Anda
- Tingkatkan ukuran VM Anda; CPU, memori, dan IOP
- Tambahkan redundansi tambahan di tingkat zona atau wilayah
6. Ajukan lebih banyak (dan lebih baik) pertanyaan
Setelah Joe, sebagai Tuan Mittens, secara tidak sengaja memotong jalan di tengah rambutnya, Tuan Mittens dan Joe harus melakukan perjalanan untuk melihat Dez, tukang cukur Joe.Sementara Joe berada di kursi tukang cukur dengan Dez, mereka mulai mengobrol tentang tujuan, kehidupan, keberadaan eksistensial, dan banyak lagi.Setelah potong rambut, 22 bertanya kepada Dez mengapa mereka tidak pernah melakukan percakapan seperti ini sebelumnya, tentang kehidupan Dez.Dez menjawab bahwa dia tidak pernah bertanya sebelumnya.Terkadang kita bisa begitu fokus pada solusi, dalam metode untuk cloud atau di lokasi, dalam bahasa dan arsitektur, dan dalam memberi tahu orang lain apa yang kita lakukan sehingga kita lupa untuk mengajukan pertanyaan yang dapat membuka dunia yang sama sekali baru.Saat Joe mengajukan pertanyaan, dia belajar lebih banyak tentang Dez, dan tentang dirinya sendiri.Mungkin pelajaran untuk HA yang lebih baik adalah mulai mengajukan lebih banyak pertanyaan tentang solusi kami, tentang arsitektur, tentang tujuan dan tantangan bisnis, tentang tujuan pelanggan akhir, tentang tim kami, dan bahkan tentang peran dan tanggung jawab kami dalam gambaran yang lebih besar.
Beberapa pertanyaan sederhana untuk meningkatkan ketersediaan kami meliputi:
- Jika bencana terjadi besok, sistem, proses, produk, atau solusi apa yang menjadi penyebabnya?
- Apa satu-satunya hal yang paling penting untuk dilindungi?Aplikasi, data, metadata, semua di atas?
- RPO apa yang dapat ditoleransi oleh aplikasi dan database kita?
- Apa yang tidak akan ditoleransi oleh pelanggan kami?
- Apa yang saya lewatkan?
- Di mana kita mendokumentasikan arsitektur ini?
- Apa yang tidak saya mengerti?
7. Ketekunan membuahkan hasil
“Penghitungan mundur,” kata Terry.Ditugaskan untuk melacak pendatang ke The Great Beyond, Terry dengan cermat menghitung jumlah jiwa yang harus tiba atau telah tiba.Setelah Joe mengambil jalan memutar ke The Great Before, Terry semakin bertekad untuk menemukan jiwa yang hilang dan memperbaiki penghitungannya. Ketika dia memulai pekerjaannya, dia berada di koridor panjang lemari arsip yang membentang sejauh dan setinggi mata memandang.Tetapi setelah beberapa saat, dia menemukan file Joe dan menemukan bahwa Joe telah menemukan celah dan itulah sebabnya penghitungannya dibatalkan.Ketekunan yang sama yang ditunjukkan oleh Terry juga akan terbayar di ranah ketersediaan yang lebih tinggi.Dalam menghadapi ketidakpastian yang menakutkan, sejumlah besar file log, dan lautan skenario kegagalan yang mungkin, momen ketekunan untuk mengungkap dan kemudian memperbaiki masalah sebelum terjadi, atau menganalisis dan memulihkannya secara efektif setelah terjadi akan membawa kita ke arah yang lebih baik. hasil yang kita inginkan.Demikian pula, kurangnya ketekunan dan ketekunan akan berarti bahwa masalah yang sama kemungkinan akan muncul kembali nanti, bahkan di lingkungan baru dengan perangkat lunak baru.
Saat film Soul berakhir, Joe kembali ke Great Before, menemukan dan kemudian meyakinkan 22 untuk mengambil Earth pass-nya dan mengambil risiko.Mengingatkan ketika dia jatuh ke bumi dengan Joe, dia mengambil risiko lain.Yang membuat anak-anak saya kecewa, film itu berakhir tanpa menggambarkan apa yang dibuatnya dalam hidupnya atau peluang-peluang baru yang mengikutinya.Dia hanya melompat dari Great Before dengan antisipasi apa yang akan terjadi selanjutnya.Mungkin kita juga berdiri di saat di mana kita bisa mengambil risiko… momen di “Sebelumnya Hebat” dan kesempatan untuk menjadikan ini tahun ketersediaan tambahan yang lebih tinggi.
– Cassius Rhee, VP Pengalaman Pelanggan
Opsi Baru untuk Cluster Ketersediaan Tinggi, SIOS Memperkuat Dukungannya untuk Disk Bersama Microsoft Azure

Opsi Baru untuk Cluster Ketersediaan Tinggi, SIOS Memperkuat Dukungannya untuk Disk Bersama Microsoft Azure
Microsoft memperkenalkan Disk Bersama Azure pada Q1 tahun 2022. Disk Bersama memungkinkan Anda untuk melampirkan disk yang dikelola ke lebih dari satu host. Secara efektif ini berarti bahwa Azure sekarang memiliki penyimpanan SAN yang setara, memungkinkan Sangat Tersedia cluster untuk menggunakan disk bersama di cloud!
Keuntungan utama menggunakan Azure Shared Disk dengan hierarki klaster SIOS Lifekeeper adalah Anda tidak lagi diharuskan memiliki kuorum penyimpanan atau simpul saksi. Dengan cara ini Anda dapat menghindari apa yang disebut otak terbelah – yang terjadi ketika komunikasi antar node terputus dan beberapa node berpotensi mengubah data secara bersamaan. Lebih sedikit node berarti lebih sedikit biaya dan kompleksitas.
Kit Pemulihan LifeKeeper SCSI-3 Persistent Reservations (SCSI3)
SIOS telah memperkenalkan Kit Pemulihan Aplikasi (ARK) untuk produk LifeKeeper untuk Linux kami. Ini disebut Kit Pemulihan LifeKeeper SCSI-3 Persistent Reservations (SCSI3). Ini memungkinkan Azure Shared Disks untuk digunakan bersama dengan reservasi SCSI-3. ARK menjamin bahwa disk bersama hanya dapat ditulis dari node yang saat ini menyimpan reservasi SCSI-3 pada disk tersebut.
Saat menginstal SIOS Lifekeeper, penginstal akan mendeteksi bahwa itu berjalan di Microsoft Azure EC2. Ini akan secara otomatis menginstal Kit Pemulihan LifeKeeper SCSI-3 Persistent Reservations (SCSI3) untuk mengaktifkan dukungan untuk Azure Shared Disk.
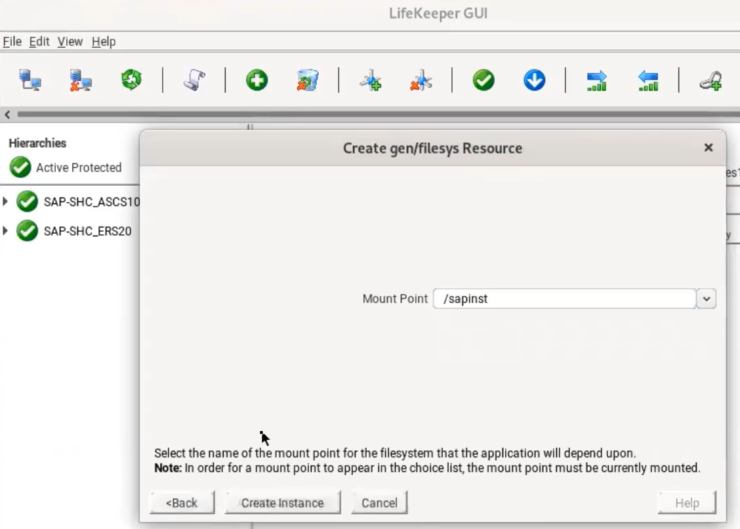
Pembuatan sumber daya dalam Lifekeeper sangat mudah dan sederhana (Gambar 1). Azure Shared Disk hanya ditambahkan ke Lifekeeper sebagai sumber daya jenis sistem file setelah dipasang secara lokal. Lifekeeper akan memberinya ID (Gambar 2) dan mengelola penguncian SCSI-3 secara otomatis.
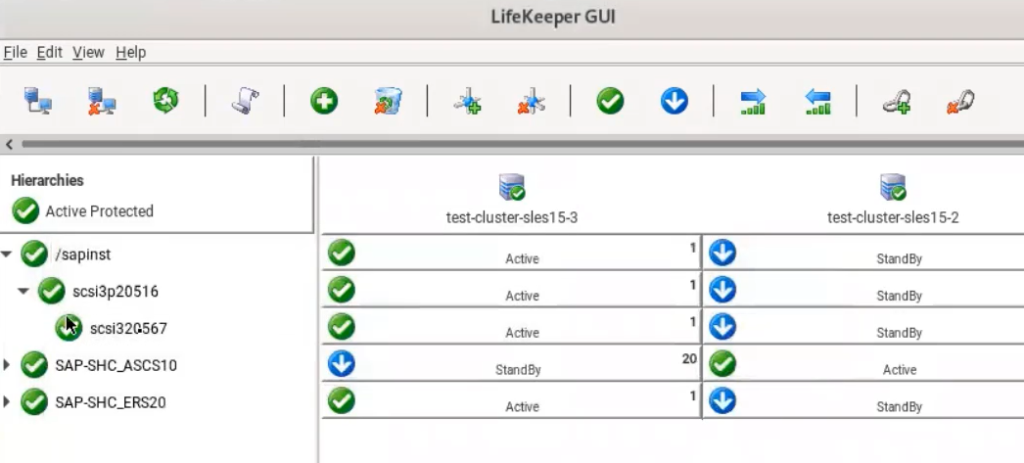
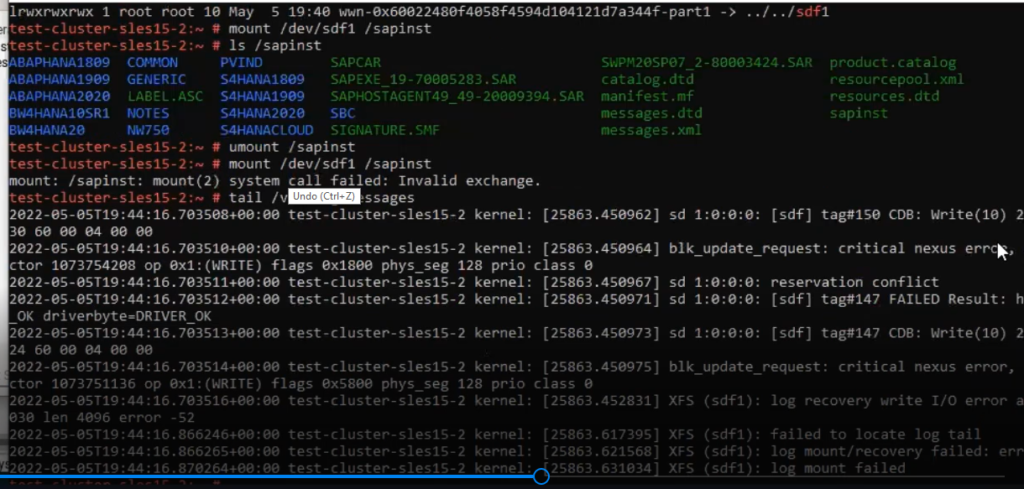
Reservasi SCSI-3 menjamin bahwa Azure Shared Disk hanya dapat ditulis pada node yang menyimpan reservasi (Gambar 3). Dalam skenario di mana node cluster kehilangan komunikasi satu sama lain, server siaga akan online, menyebabkan potensi situasi otak terbelah. Namun, karena reservasi SCSI-3, hanya satu node yang dapat mengakses disk pada satu waktu. Ini sebenarnya mencegah skenario otak terbelah yang sebenarnya. Hanya satu sistem yang akan menahan reservasi. Ini akan menjadi node aktif baru (dalam hal ini yang lain akan reboot) atau tetap menjadi node aktif. Node yang tidak memegang reservasi Azure Shared Disk hanya akan berakhir dengan sumber daya dalam status "Siaga". Hanya karena mereka tidak dapat memperoleh reservasi.
Tautan ke definisi Microsoft tentang Azure Shared Disks https://docs.microsoft.com/en-us/azure/virtual-machines/disks-shared
Apa yang Dapat Anda Harapkan
Saat ini, SIOS mendukung Locally-redundant Storage (LRS).Kami bekerja sama dengan Microsoft untuk menguji dan mendukung Zone-Redundant Storage (ZRS). Idealnya kami ingin tahu kapan ada kegagalan ZRS sehingga kami dapat mengalihkan hierarki sumber daya ke node paling lokal ke penyimpanan aktif. SIOS mengharapkan dukungan Azure Shared Disk akan tiba di rilis Lifekeeper 9.6.2 untuk Linux berikutnya.
Direproduksi dengan izin dari SIOS