| Agustus 8, 2022 |
|
| Agustus 4, 2022 |
Buku Putih: Sistem Manajemen Gedung dan Kebutuhan akan Ketersediaan Tinggi |
|
|
|
| Juli 31, 2022 |
Buku Putih: Penjelasan Arsitektur Multi-Cloud – Kasus Penggunaan, Risiko, dan Praktik Terbaik
Buku Putih: Penjelasan Arsitektur Multi-Cloud – Kasus Penggunaan, Risiko, dan Praktik TerbaikDalam dekade terakhir, komputasi awan telah muncul sebagai platform utama untuk penyebaran komputasi. Baik AWS maupun Microsoft mengklaim bahwa sebagian besar Fortune 500 menggunakan layanan mereka, dan baik Google maupun Oracle juga memiliki penawaran cloud yang menarik. Ini telah menyebabkan banyak organisasi, baik secara desain atau tidak sengaja, memiliki beban kerja yang berjalan di banyak cloud. Pelajari tentang Multicloud, kasus penggunaannya, risiko, dan praktik terbaik untuk pemeliharaan ketersediaan tinggi . Direproduksi dengan izin dari SIOS |
| Juli 27, 2022 |
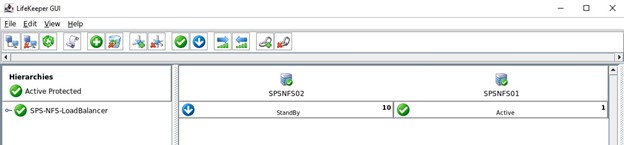
Memperkenalkan Kit Penyeimbang Beban Umum untuk SIOS LifeKeeper dan Microsoft Azure |




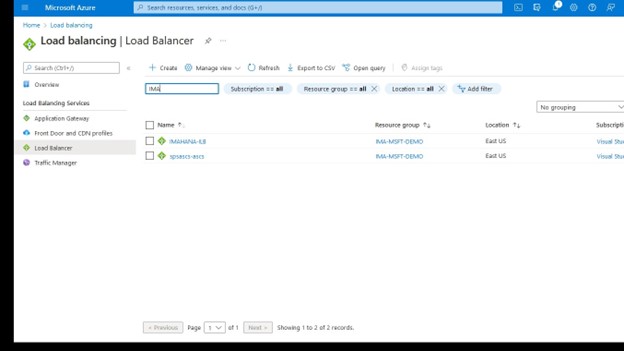
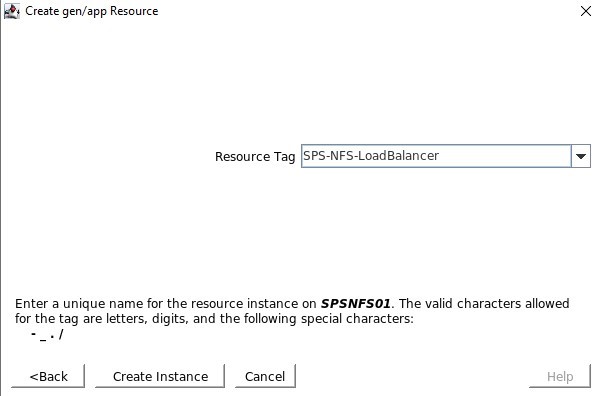
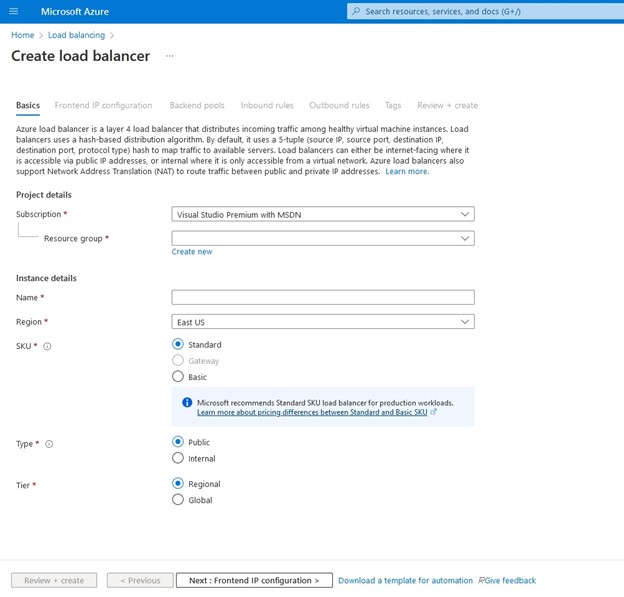 Buat penyeimbang beban, Anda akan memilih grup sumber daya tempat Anda ingin ini digunakan serta namanya, saya suka menggunakan nama yang sejalan dengan jenis klaster yang saya gunakan penyeimbang beban dengan misalnya IMA -NFS-LB akan berada di depan kedua node IMA-NFS.
Buat penyeimbang beban, Anda akan memilih grup sumber daya tempat Anda ingin ini digunakan serta namanya, saya suka menggunakan nama yang sejalan dengan jenis klaster yang saya gunakan penyeimbang beban dengan misalnya IMA -NFS-LB akan berada di depan kedua node IMA-NFS.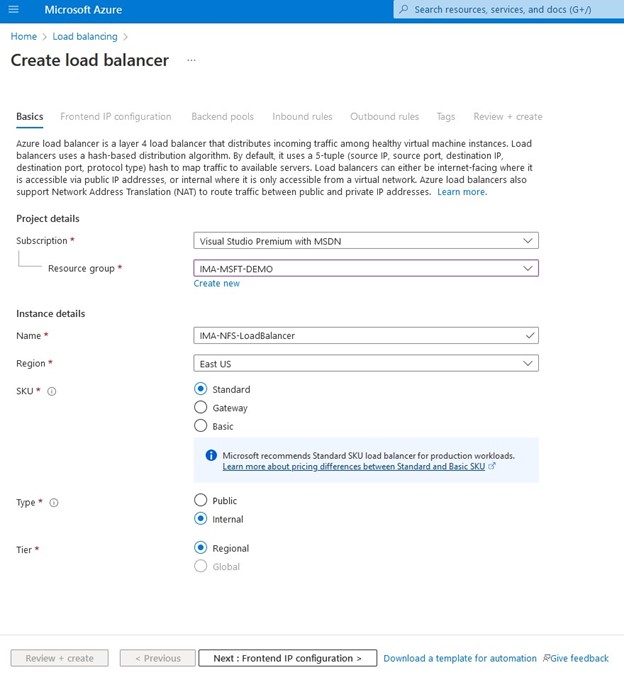
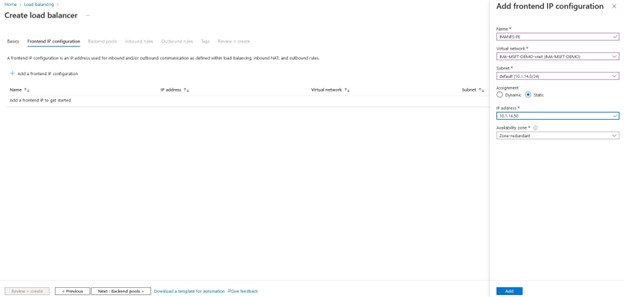
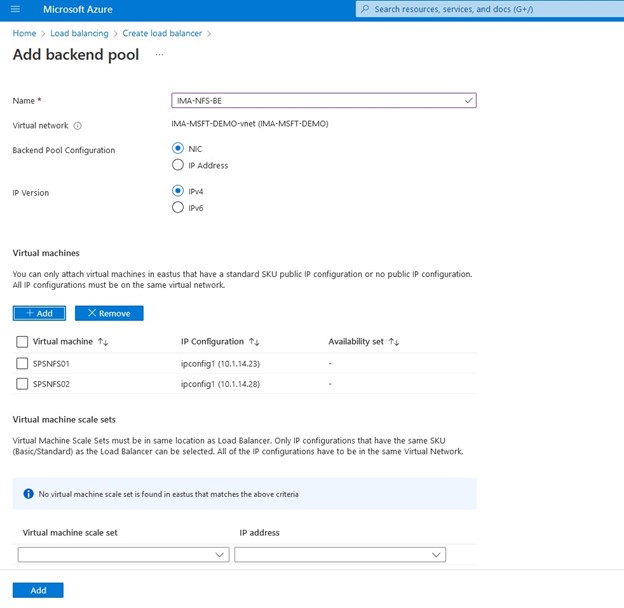
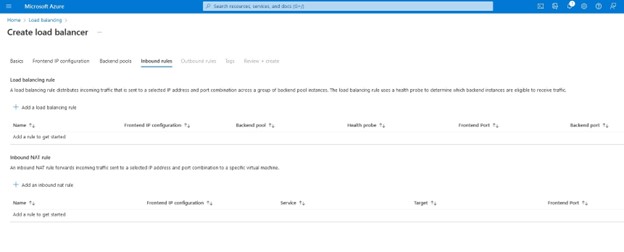
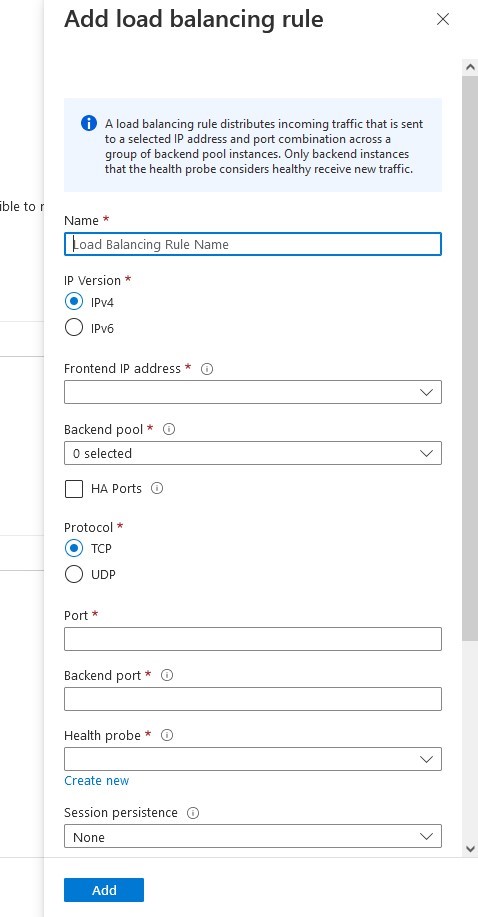
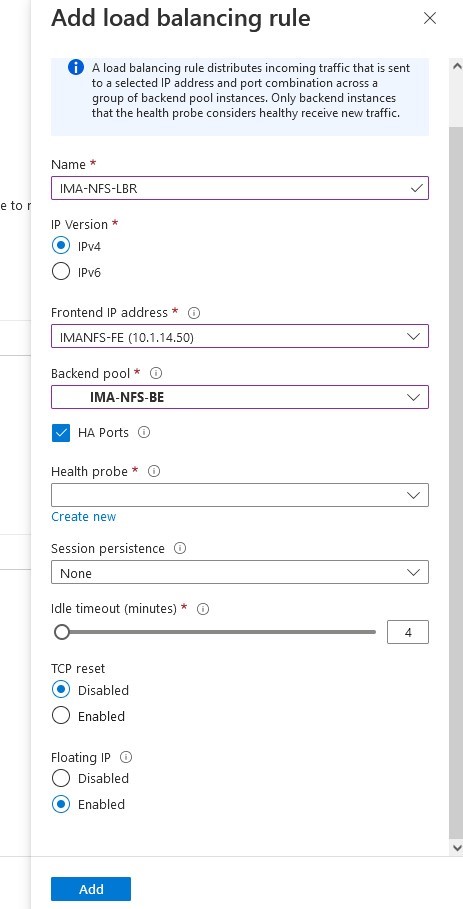
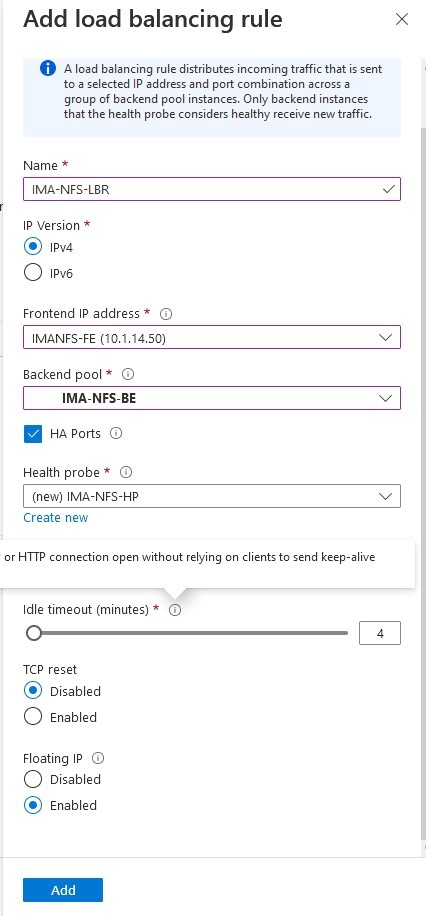
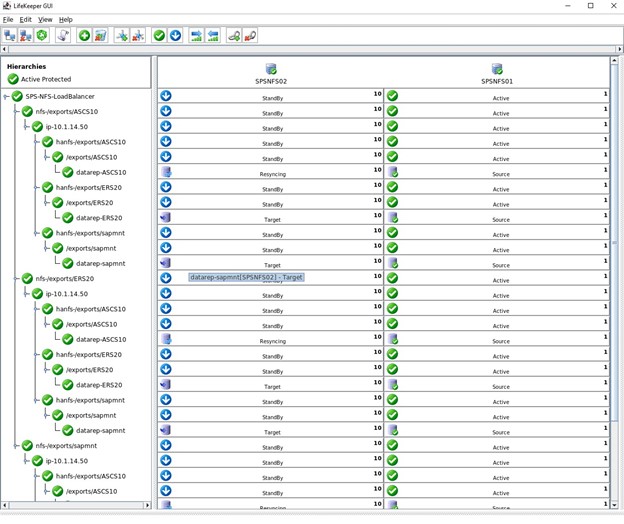
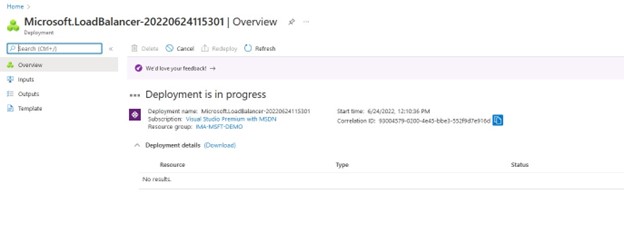 Setelah kami memilih "tambah" maka Azure akan memulai penyebaran Penyeimbang Beban, ini dapat memakan waktu beberapa menit dan setelah selesai maka konfigurasi beralih ke Suite Perlindungan SIOS.
Setelah kami memilih "tambah" maka Azure akan memulai penyebaran Penyeimbang Beban, ini dapat memakan waktu beberapa menit dan setelah selesai maka konfigurasi beralih ke Suite Perlindungan SIOS.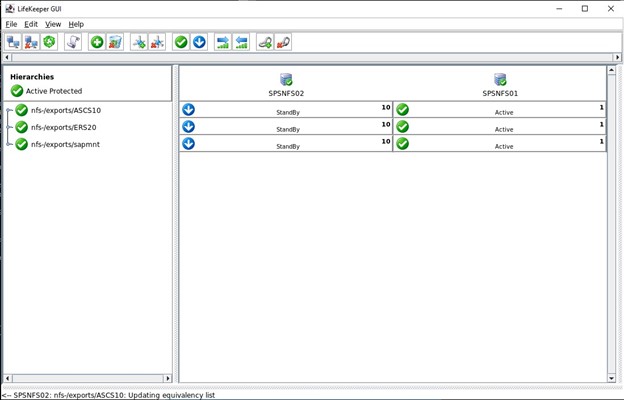 Apa yang perlu kita lakukan dalam SIOS Protection Suite adalah menentukan Load Balancer menggunakan skrip Hotfix yang disediakan oleh SIOS.
Apa yang perlu kita lakukan dalam SIOS Protection Suite adalah menentukan Load Balancer menggunakan skrip Hotfix yang disediakan oleh SIOS.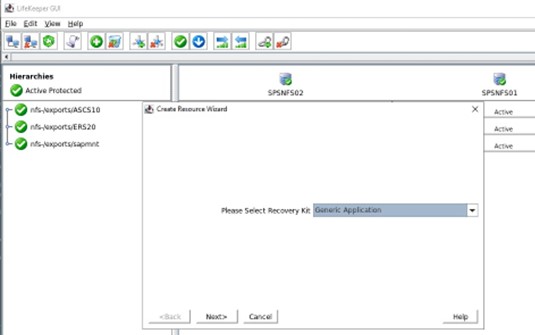
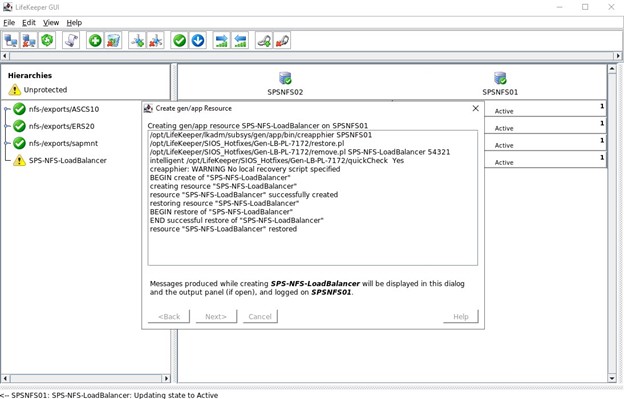
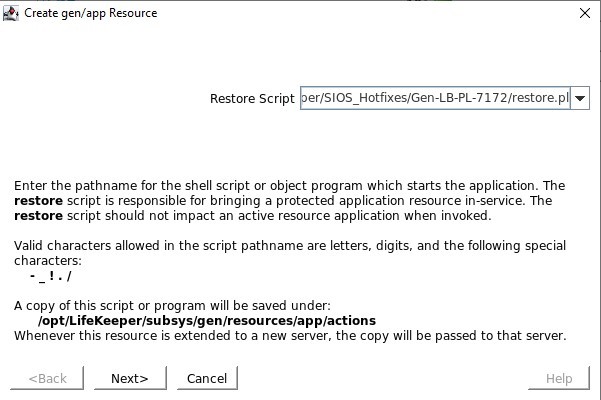 Tentukan skrip restore.pl yang terletak di /opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/
Tentukan skrip restore.pl yang terletak di /opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/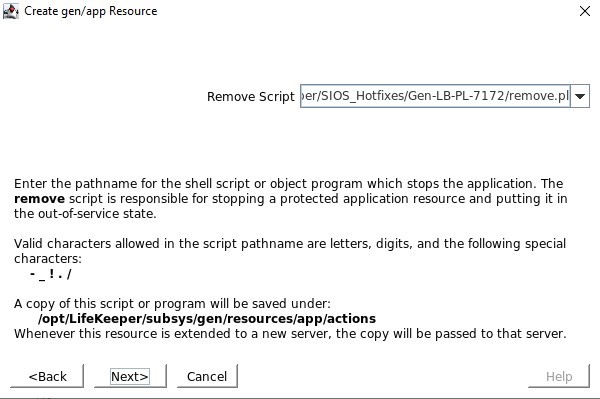 Tentukan skrip remove.pl yang terletak di /opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/
Tentukan skrip remove.pl yang terletak di /opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/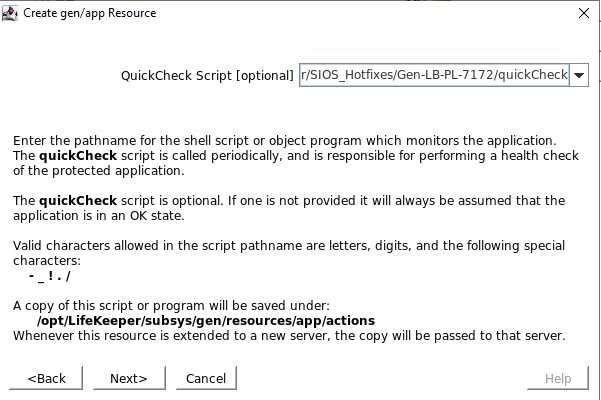 Tentukan skrip quickCheck yang terletak di /opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/
Tentukan skrip quickCheck yang terletak di /opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/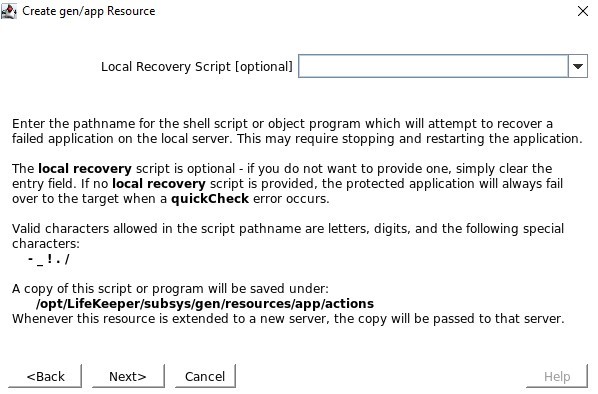 Tidak ada skrip pemulihan lokal, jadi pastikan Anda menghapus input ini
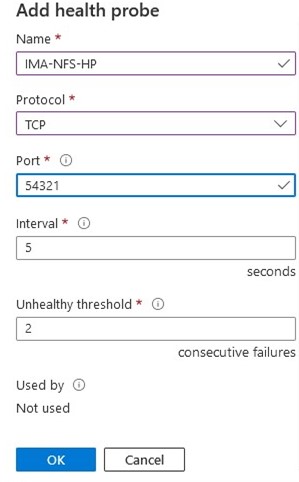
Tidak ada skrip pemulihan lokal, jadi pastikan Anda menghapus input ini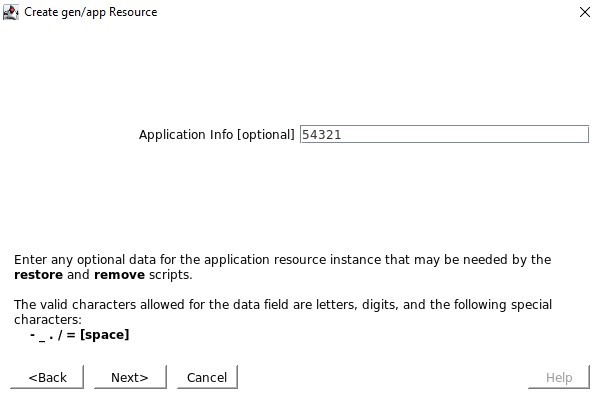 Ketika diminta untuk Info Aplikasi, kami ingin memasukkan nomor port yang sama seperti yang kami konfigurasikan dalam konfigurasi Health Probe misalnya 54321
Ketika diminta untuk Info Aplikasi, kami ingin memasukkan nomor port yang sama seperti yang kami konfigurasikan dalam konfigurasi Health Probe misalnya 54321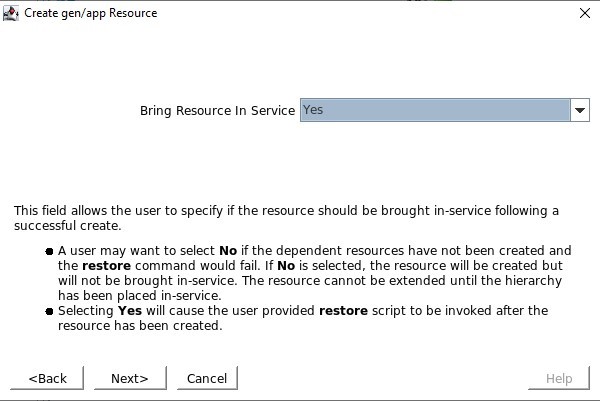 Kami akan memilih untuk membawa layanan ke layanan setelah dibuat.
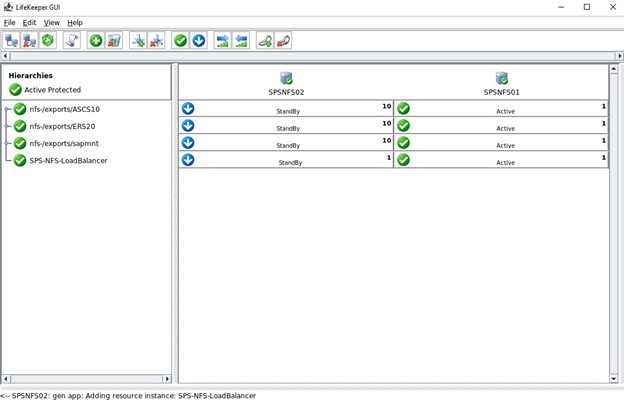
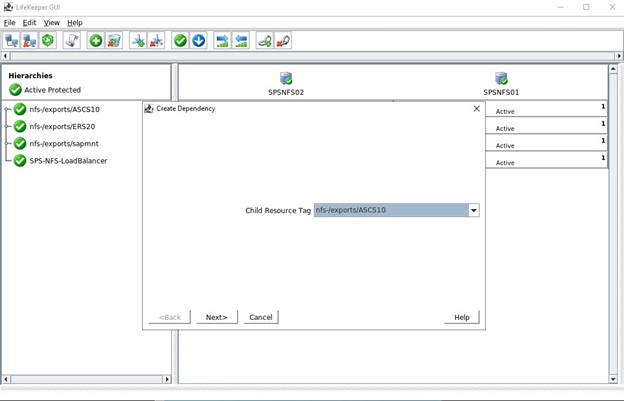
Kami akan memilih untuk membawa layanan ke layanan setelah dibuat.