| Agustus 24, 2022 |
Buku Putih: Solusi Ketersediaan Tinggi Memberikan Penghematan Biaya dan Fleksibilitas untuk Oracle |
| Agustus 20, 2022 |
Buku Putih: Memahami Kompleksitas Ketersediaan Tinggi untuk Aplikasi Bisnis-Kritis
|
| Agustus 18, 2022 |
Memperkenalkan Kit Penyeimbang Beban Umum untuk SIOS LifeKeeper dan Google Cloud |
| Agustus 12, 2022 |
Cara Mengurangi Waktu Henti di SAP
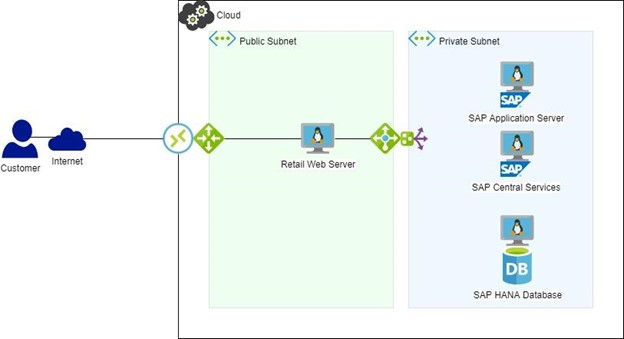
Cara Mengurangi Waktu Henti di SAPMemikirkan bagaimana caranya mengurangi waktu henti di SAP adalah topik penting yang harus dikunjungi selama desain solusi awal. Perubahan pada lanskap SAP yang ada dapat dibuat, ini bisa lebih rumit di lingkungan produksi yang ada di mana waktu henti akan menjadi masalah. Ada beberapa komponen khas dalam lanskap SAP yang dapat dianggap sebagai titik kegagalan tunggal; ASCS (Layanan Pusat), HANA DB, node NFS, dan server Aplikasi SAP. Idealnya ini harus dilindungi dengan menggunakan server redundan dalam konfigurasi Ketersediaan Tinggi. Sasaran HA/DR untuk SAPSasaran inti saat merancang komponen Ketersediaan Tinggi/Pemulihan Bencana untuk SAP harus:● Minimalkan Waktu Henti ● Hilangkan kehilangan data ● Pertahankan integritas data ● Aktifkan konfigurasi yang fleksibel Di lingkungan cloud modern saat ini, infrastruktur perangkat keras yang mendasari biasanya terlindungi dengan baik dari kegagalan dengan menggunakan beberapa NIC redundan, penyimpanan redundan, dan zona ketersediaan perangkat keras – namun, ini masih tidak 't menjamin bahwa aplikasi SAP Anda akan berjalan dan menanggapi permintaan. Menggunakan sebuah ketersediaan tinggi solusi seperti SIOS Protection Suite memperkenalkan Ketersediaan Tinggi yang cerdas yang digabungkan dengan replikasi disk lokal untuk memastikan bahwa aplikasi dan layanan SAP Anda terus dipantau, dilindungi, dan memiliki kemampuan untuk secara otomatis beralih ke perangkat keras yang berlebihan ketika kegagalan terdeteksi. Sekarang mari kita pertimbangkan contoh sederhana dari konfigurasi SAP yang tidak dilindungi HA, mungkin terlihat seperti ini (gambar 1): Sekarang mari kita bayangkan bahwa lingkungan pemrosesan penjualan ini (gambar di atas) dikonfigurasi di cloud tanpa HA karena arsitek berpikir bahwa perangkat keras yang sangat redundan di lingkungan cloud cukup baik untuk melindungi dari kegagalan.Jika HANA DB mengalami masalah dan mati, mari kita lihat langkah-langkah yang biasanya diperlukan untuk membuat database kembali aktif dan berjalan: ● Bahkan jika HANA dikonfigurasi dengan Replikasi Sistem HANA, failover ke sistem DB HANA sekunder tidak otomatis. Ini akan membutuhkan seseorang yang mengetahui HANA untuk memperbaikinya, setelah kegagalan terdeteksi dan mereka diberitahu tentang pemadaman. Laporan ini dari IBM menunjukkan bahwa biaya waktu henti rata-rata per jam adalah $10k Tingkatkan ukuran pelanggan dan sangat mungkin bahwa situasi penurunan sistem apa pun akan mulai menelan biaya ratusan ribu dolar dan menghabiskan sumber daya orang yang signifikan untuk diselesaikan. Lain laporan IBM menunjukkan bahwa 44% responden mengalami pemadaman tak terencana dua bulanan dan 35% lainnya mengalami pemadaman tak terencana bulanan. Pemadaman terencana itu sendiri merupakan masalah potensial lainnya dengan 46% responden melaporkan pemadaman terencana bulanan dan 29% lainnya melaporkan pemadaman terencana tahunan. Memiliki aplikasi dan layanan yang dilindungi oleh perangkat lunak HA juga dapat mengurangi pemadaman terencana ini dengan mengizinkan layanan dipindahkan ke sistem yang berjalan selama aktivitas pemeliharaan. Belajar lebih tentang ketersediaan tinggi untuk SAP dan S/4HANA . |
| Agustus 8, 2022 |
Buku Putih: Menjelajahi Kasus Penggunaan Ketersediaan Tinggi di Industri yang Diatur |



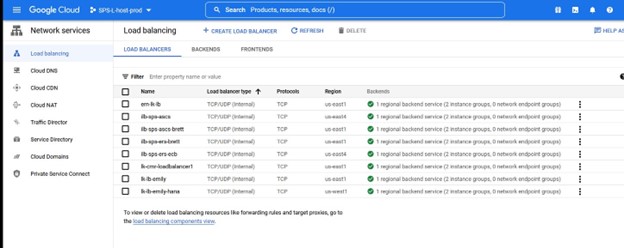
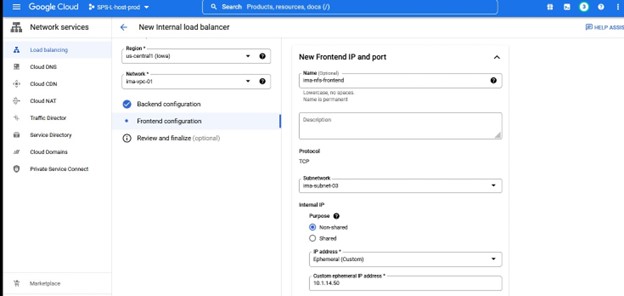
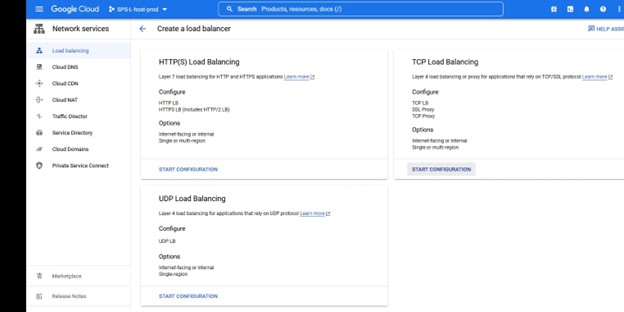 Dalam contoh ini kami ingin TCP Load Balancing Buat penyeimbang beban, Anda akan memilih grup sumber daya di mana Anda ingin ini digunakan serta namanya, saya suka menggunakan nama yang sejalan dengan tipe cluster yang saya menggunakan load balancer misalnya IMA-NFS-LB akan duduk di depan kedua node IMA-NFS.
Dalam contoh ini kami ingin TCP Load Balancing Buat penyeimbang beban, Anda akan memilih grup sumber daya di mana Anda ingin ini digunakan serta namanya, saya suka menggunakan nama yang sejalan dengan tipe cluster yang saya menggunakan load balancer misalnya IMA-NFS-LB akan duduk di depan kedua node IMA-NFS.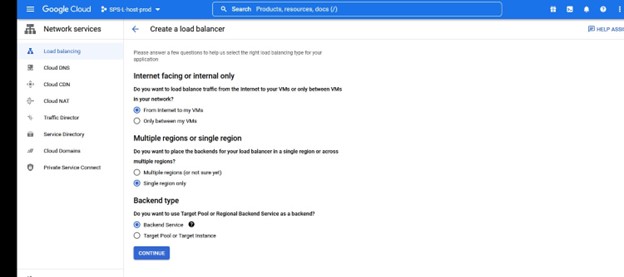
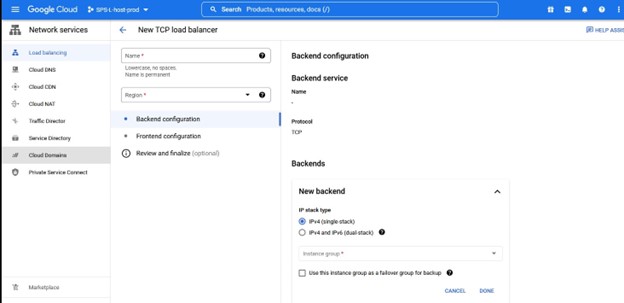
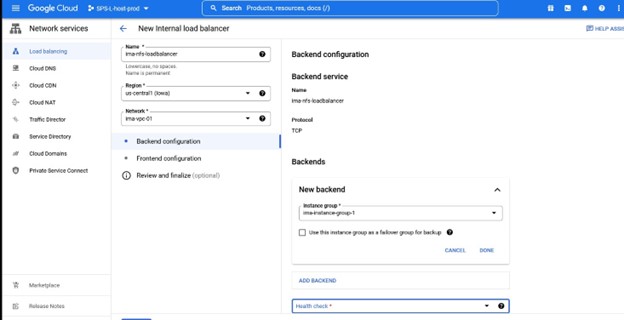
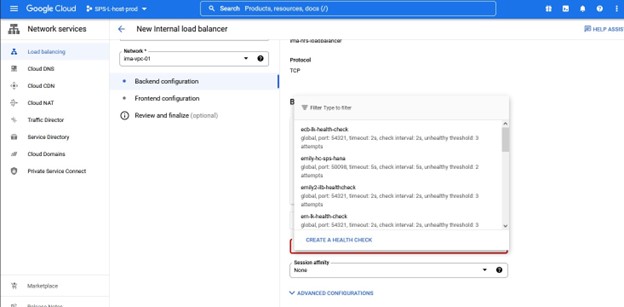
 Sekali lagi, perhatikan nomor port karena ini akan digunakan dengan Lifekeeper.
Sekali lagi, perhatikan nomor port karena ini akan digunakan dengan Lifekeeper.
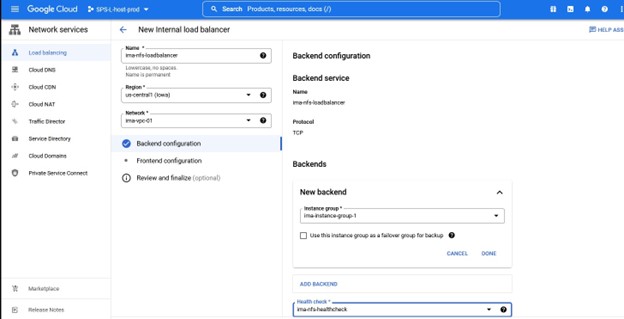
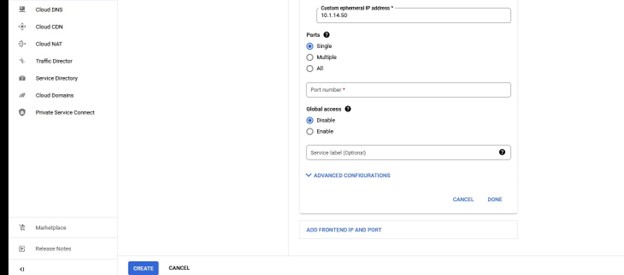
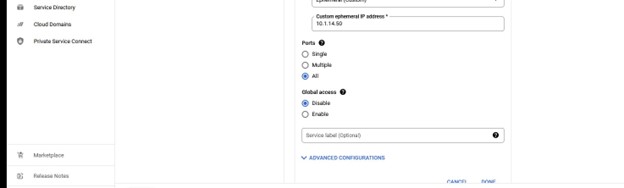
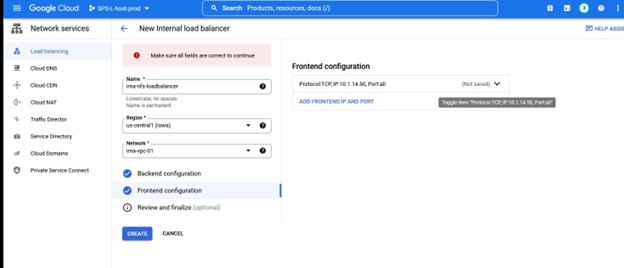
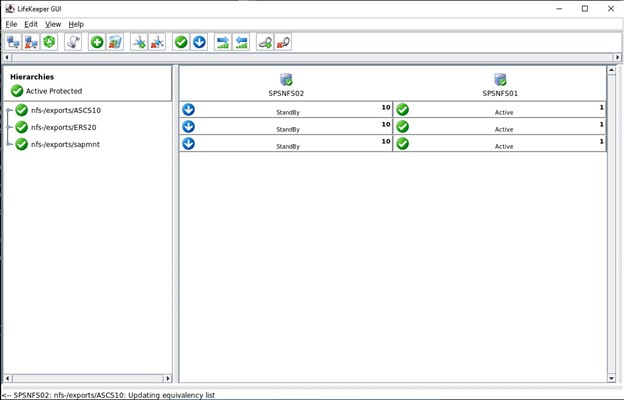 Apa yang perlu kita lakukan dalam
Apa yang perlu kita lakukan dalam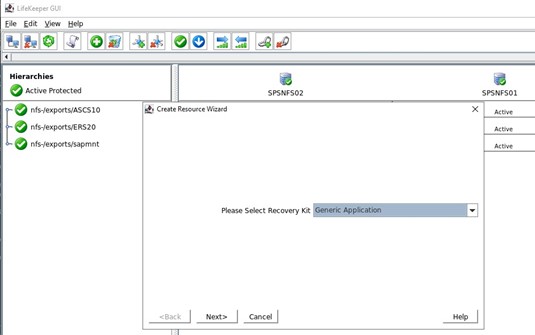
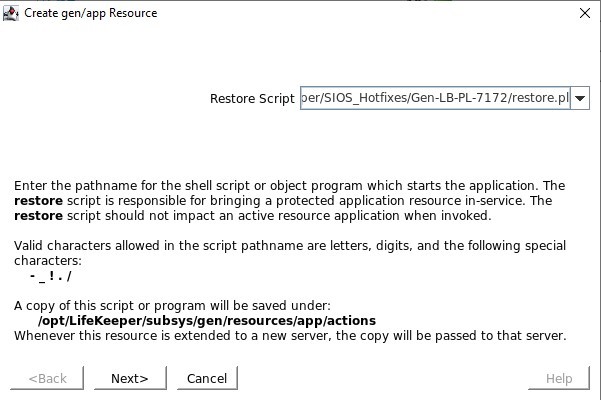 Tentukan skrip restore.pl yang terletak di /opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/
Tentukan skrip restore.pl yang terletak di /opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/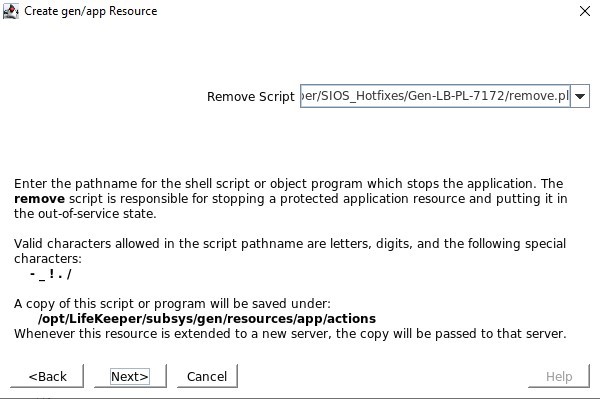 Tentukan skrip remove.pl yang terletak di /opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/
Tentukan skrip remove.pl yang terletak di /opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/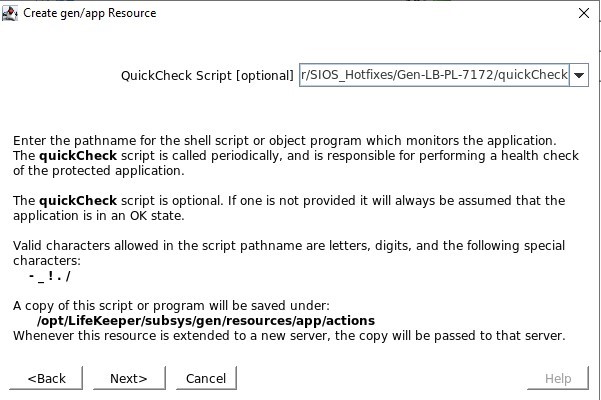 Tentukan skrip quickCheck yang terletak di /opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/
Tentukan skrip quickCheck yang terletak di /opt/Lifekeeper/SIOS_Hotfixes/Gen-LB-PL-7172/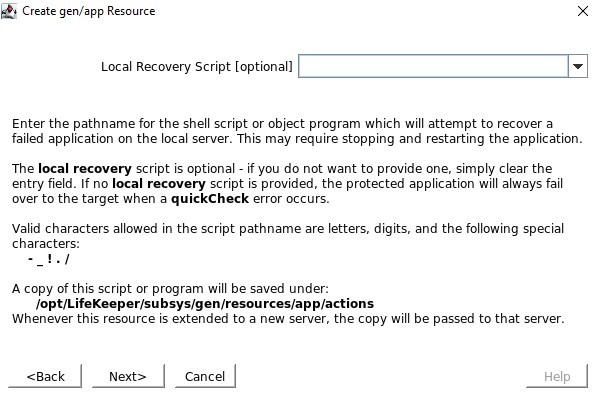 Tidak ada skrip pemulihan lokal, jadi pastikan Anda menghapus input ini
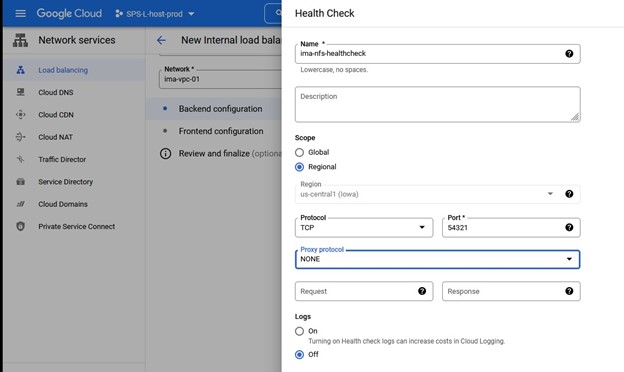
Tidak ada skrip pemulihan lokal, jadi pastikan Anda menghapus input ini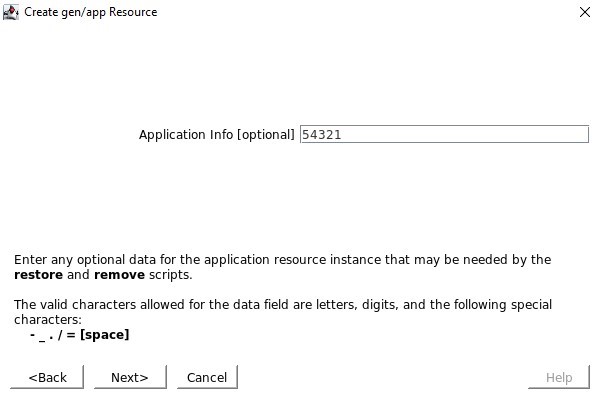 Saat diminta untuk Info Aplikasi, kami ingin memasukkan nomor port yang sama seperti yang kami konfigurasikan di port Pemeriksaan Kesehatan misalnya 54321
Saat diminta untuk Info Aplikasi, kami ingin memasukkan nomor port yang sama seperti yang kami konfigurasikan di port Pemeriksaan Kesehatan misalnya 54321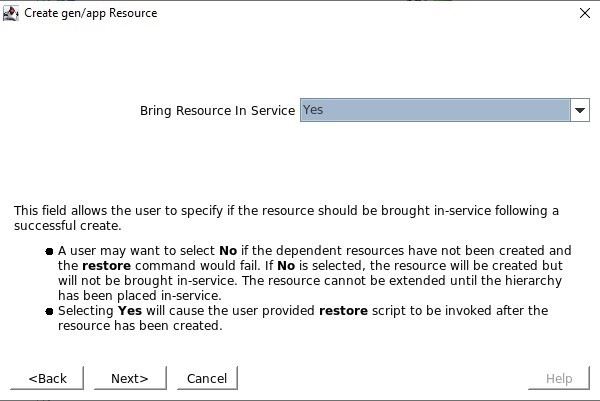 Kami akan memilih untuk membawa layanan ke layanan setelah dibuat
Kami akan memilih untuk membawa layanan ke layanan setelah dibuat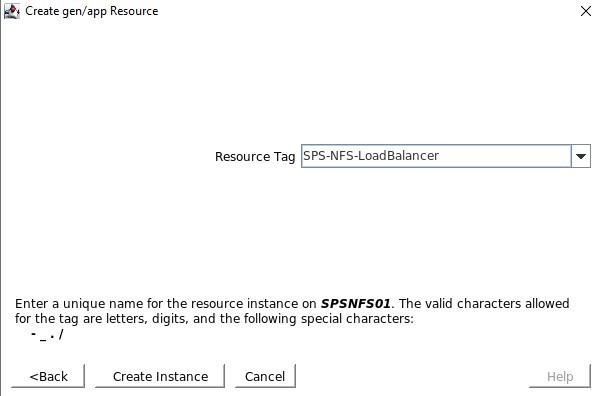 Resource Tag adalah nama yang akan kita lihat ditampilkan di GUI SPS-L, saya suka menggunakan sesuatu yang memudahkan untuk mengidentifikasi
Resource Tag adalah nama yang akan kita lihat ditampilkan di GUI SPS-L, saya suka menggunakan sesuatu yang memudahkan untuk mengidentifikasi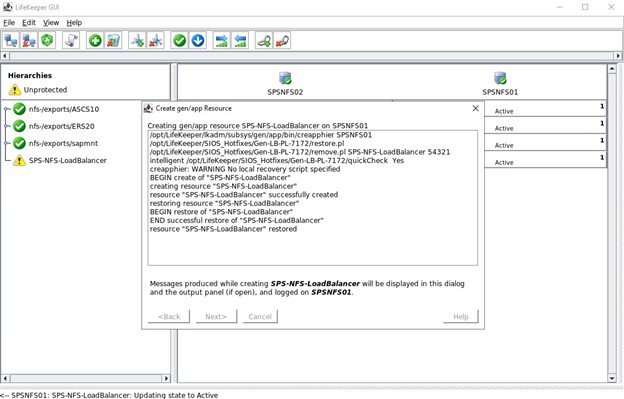 Jika semuanya dikonfigurasi dengan benar, Anda akan melihat "AKHIR pemulihan yang berhasil", kami kemudian dapat memperluas ini ke node lain sehingga sumber daya dapat di-host di salah satu node.
Jika semuanya dikonfigurasi dengan benar, Anda akan melihat "AKHIR pemulihan yang berhasil", kami kemudian dapat memperluas ini ke node lain sehingga sumber daya dapat di-host di salah satu node.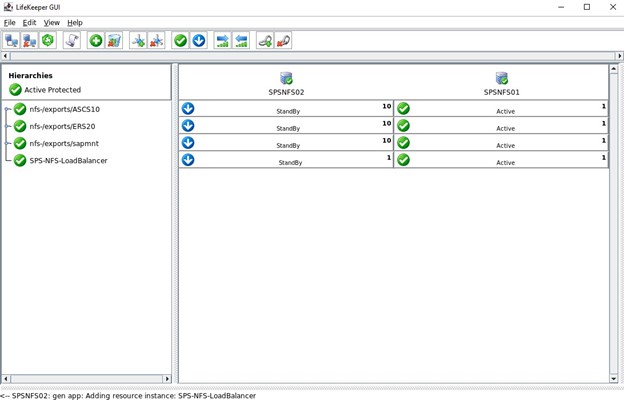
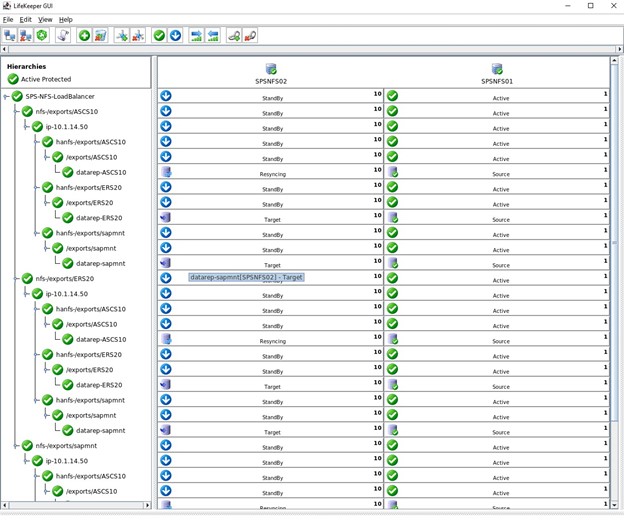
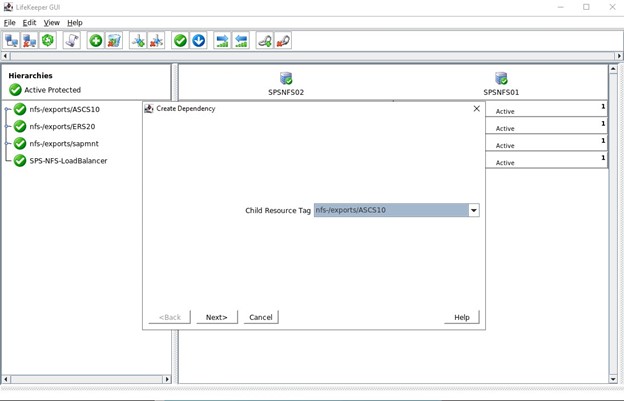 Langkah terakhir untuk cluster ini adalah membuat dependensi turunan untuk ketiga ekspor NFS, artinya semua ekspor NFS lengkap dengan mirror dan IP Datakeeper akan mengandalkan Load Balancer. Jika masalah serius terjadi pada node aktif maka semua sumber daya ini akan dialihkan ke node lain yang berfungsi.
Langkah terakhir untuk cluster ini adalah membuat dependensi turunan untuk ketiga ekspor NFS, artinya semua ekspor NFS lengkap dengan mirror dan IP Datakeeper akan mengandalkan Load Balancer. Jika masalah serius terjadi pada node aktif maka semua sumber daya ini akan dialihkan ke node lain yang berfungsi.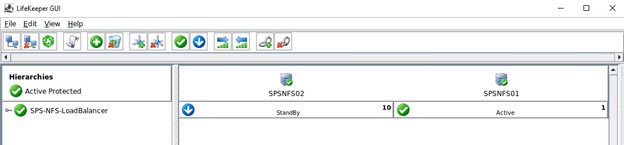

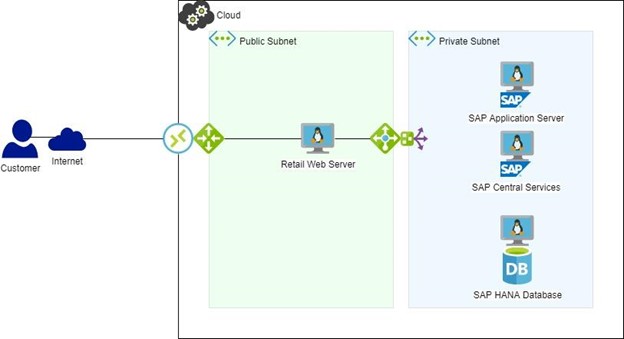 Jika lingkungan ini digunakan untuk memproses transaksi dari server web yang digunakan untuk menjual pakaian kepada pelanggan, SAP digunakan untuk memproses penjualan, melacak pesanan, melacak inventaris, dan menyediakan beberapa pemesanan otomatis, dll berdasarkan transaksi ini.
Jika lingkungan ini digunakan untuk memproses transaksi dari server web yang digunakan untuk menjual pakaian kepada pelanggan, SAP digunakan untuk memproses penjualan, melacak pesanan, melacak inventaris, dan menyediakan beberapa pemesanan otomatis, dll berdasarkan transaksi ini.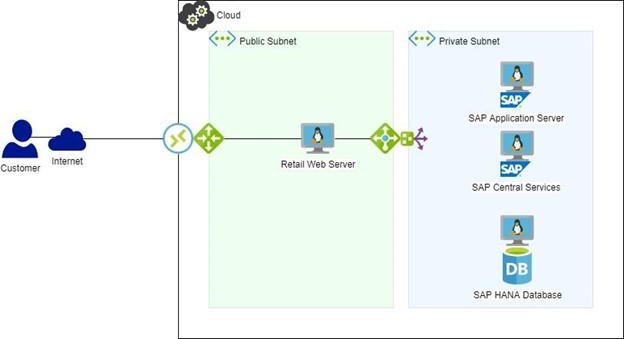
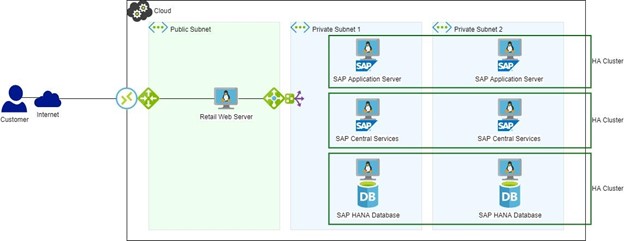 Gambar 2: Lanskap SAP dengan HA/DR Jika perangkat lunak HA telah digunakan (gambar 2), failover HANA DB akan otomatis dan interupsi ke server web akan berada dalam batas waktu yang dikonfigurasi dan sama sekali tidak ada penjualan yang hilang. Peringatan akan dibuat dan penyebabnya dapat dilihat dan didiagnosis dengan cara yang lebih santai daripada situasi sistem mati.
Gambar 2: Lanskap SAP dengan HA/DR Jika perangkat lunak HA telah digunakan (gambar 2), failover HANA DB akan otomatis dan interupsi ke server web akan berada dalam batas waktu yang dikonfigurasi dan sama sekali tidak ada penjualan yang hilang. Peringatan akan dibuat dan penyebabnya dapat dilihat dan didiagnosis dengan cara yang lebih santai daripada situasi sistem mati.