| Oktober 6, 2022 |
Kit Pemulihan Aplikasi Umum
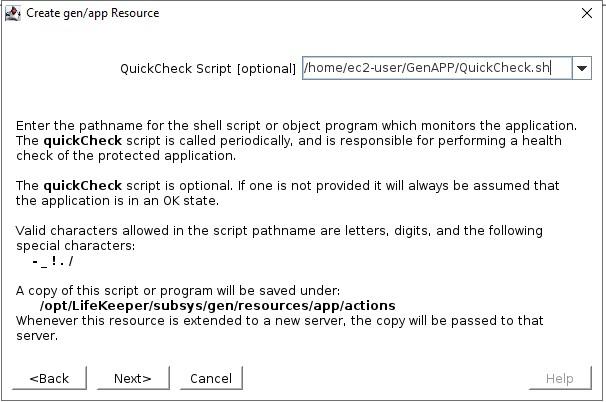
Kit Pemulihan Aplikasi UmumItu Suite Perlindungan SIOS untuk Linux hadir dengan serangkaian Kit Pemulihan Aplikasi praktis yang mencakup basis data utama seperti SAP HANA dan Peramal , IP, Sistem File dan NAS atau NFS berbagi dan mengekspor. Setiap ARK yang disediakan SIOS memiliki skrip pemulihan (mulai), hapus (hentikan), periksa cepat, dan pulihkan – ini tidak dapat dikonfigurasi dengan mudah di luar opsi apa pun yang diminta selama konfigurasi dan penambahan ke dalam hierarki yang dilindungi. ARK ini dikembangkan, dipelihara, diperiksa kualitas, dan dalam beberapa kasus “disertifikasi dukungan” oleh vendor aplikasi itu sendiri. Apa yang Anda lakukan jika Anda memiliki aplikasi atau layanan yang tidak tercakup oleh SIOS ARK yang sudah ada? Masukkan ARK generik. ARK generik dapat ditambahkan ke dalam hierarki dan dikonfigurasi dengan cara yang mirip dengan ARK SIOS lainnya; hal khusus tentang ARK generik adalah Anda harus menyediakan skrip pemulihan, penghapusan, dan quickCheck dan secara opsional skrip pemulihan. Anda dapat menggunakan bahasa skrip yang dikonfigurasi untuk membuat skrip Anda (BASH atau Perl adalah umum), mari selidiki skrip ini lebih jauh:memulihkan: Ini adalah skrip yang digunakan untuk memulai layanan atau aplikasi Anda menghapus: Ini adalah skrip yang digunakan untuk menghentikan layanan atau aplikasi Anda pemeriksaan cepat: Skrip ini digunakan untuk menentukan apakah aplikasi atau layanan Anda berfungsi seperti yang Anda harapkan pulih: Skrip ini akan digunakan untuk mencoba pemulihan setelah kegagalan, aplikasi dan layanan tertentu memungkinkan untuk dimulai ulang atau perintah tertentu dijalankan untuk mencoba memulihkan dari skenario kegagalan Secara default, skrip quickCheck berjalan setiap 180 detik. Jika skrip quickCheck mendeteksi kegagalan aplikasi, skrip tersebut akan memanggil skrip pemulihan. Skrip pemulihan mencoba memulai ulang aplikasi pada node saat ini. Jika skrip pemulihan gagal memulai ulang aplikasi, atau skrip pemulihan tidak disediakan, skrip hapus akan dijalankan. Ini memulai failover ke node siaga. Template untuk Kit Aplikasi GenerikSIOS menyediakan contoh template untuk Kit Aplikasi Generik.Contoh-contoh ini diinstal dengan perangkat lunak lifekeeper dan dapat ditemukan di sini: quickPeriksa, hapus, dan pulihkan /opt/Lifekeeper/lkadm/subsys/gen/app/template/actions/ pemulihan /opt/Lifekeeper/lkadm/subsys/gen/app/templates/recovery Ada contoh untuk quickCheck, hapus, dan pulihkan dalam bahasa BASH (.sh) dan Perl (.pl). Contoh skrip didokumentasikan sendiri dengan komentar di seluruh skrip. Dengan asumsi Anda terbiasa dengan BASH atau Perl maka Anda akan dapat memahami apa yang dilakukan skrip.. Kode pengembalian 0 menunjukkan proses yang berhasil, nilai lainnya menunjukkan kegagalan. Hasil skrip akan memicu tindakan selanjutnya yang diambil LifeKeeper. Pengaturan dalam LifekeeperSetelah Anda membuat skrip Anda, Anda dapat membuat Aplikasi Generik dengan mengklik tanda plus hijau untuk membuat sumber daya baru. Pilih "Aplikasi Generik" untuk meluncurkan wizard konfigurasi. 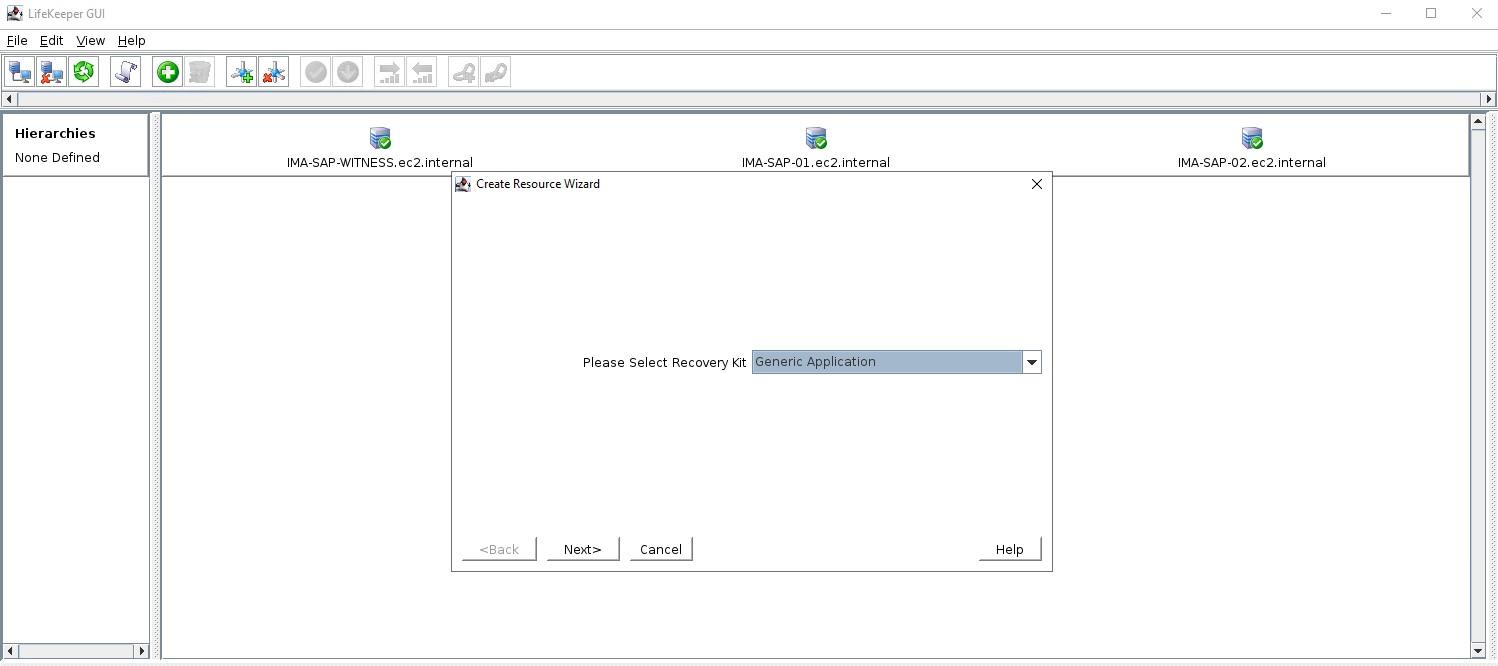 Tambahkan sumber daya dan pilih Aplikasi Generik 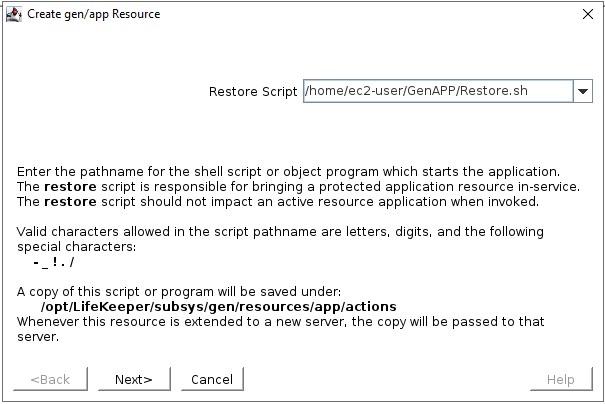 Pilih skrip Pulihkan 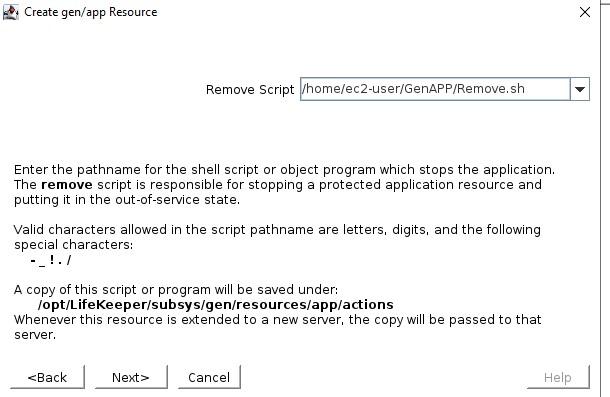 Pilih skrip Hapus mulai dari sini
Pilih skrip QuickCheck 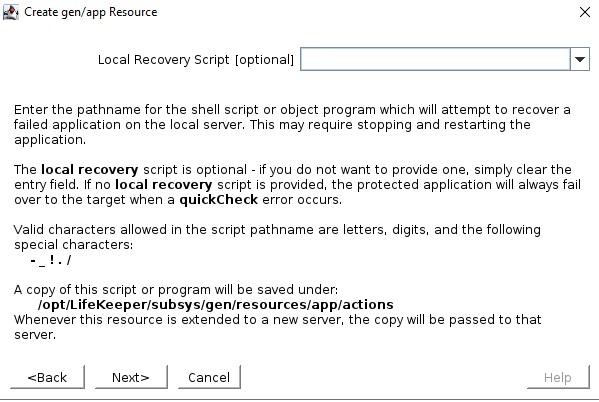 Pilih skrip Pemulihan (tidak ada dalam contoh ini)  Info Aplikasi adalah cara untuk menyampaikan informasi ke skrip GenAPP. Sebagai contoh, di GenAPP kami untuk penyeimbang beban generik, kami menggunakan bidang ini untuk melewati port yang didengarkan oleh penyeimbang beban. 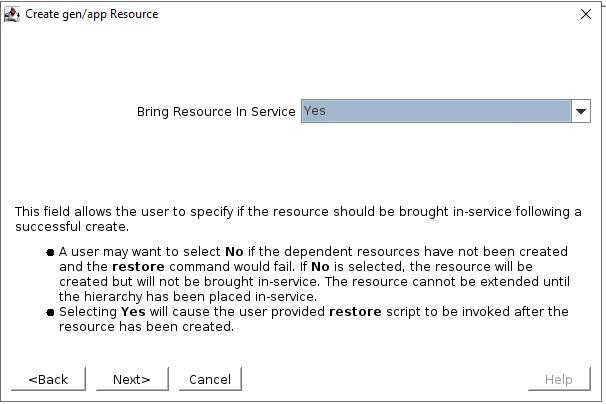 Pilih apakah Anda ingin membawa GenAPP online atau tidak setelah dibuat, terkadang Anda ingin membiarkan GenAPP offline sehingga Anda dapat membuat dependensi apa pun yang mungkin diperlukan. 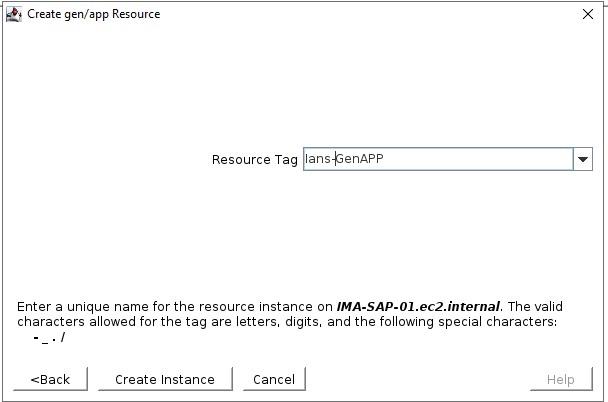 Beri nama resource yang akan dibuat  Setelah Anda memasukkan semua informasi, sumber daya akan dibuat. Jadi, Anda dapat melihat bahwa membuat GenAPP untuk melindungi hampir semua aplikasi sangatlah mudah dan sederhana. GenAPP memungkinkan Anda untuk melindungi aplikasi APAPUN, bahkan aplikasi khusus yang dibuat secara internal. Jika Anda ingin mempelajari lebih lanjut tentang bagaimana SIOS dapat membantu Anda menjaga agar aplikasi penting bisnis Anda tetap tersedia, silakan hubungi kami! Direproduksi dengan izin oleh SIOS |
| Oktober 4, 2022 |
AWS Summit Singapura – SPONSOR PERAK |
| Oktober 2, 2022 |
Cara mengonversi dari sumber daya SIOS NFS ke EFS |
| September 28, 2022 |
Apa yang baru di SIOS LifeKeeper untuk Linux v 9.6.2? |
| September 24, 2022 |
Opsi Baru untuk Cluster Ketersediaan Tinggi, SIOS Memperkuat Dukungannya untuk Disk Bersama Microsoft Azure |