| Januari 10, 2023 |
SIOS DataKeeper Clustering Software Memungkinkan Gulliver International untuk Memindahkan Sistem IT Internal ke Amazon Web Services dengan Aman |
| Januari 5, 2023 |
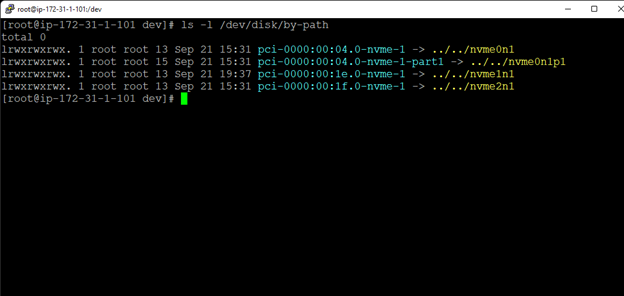
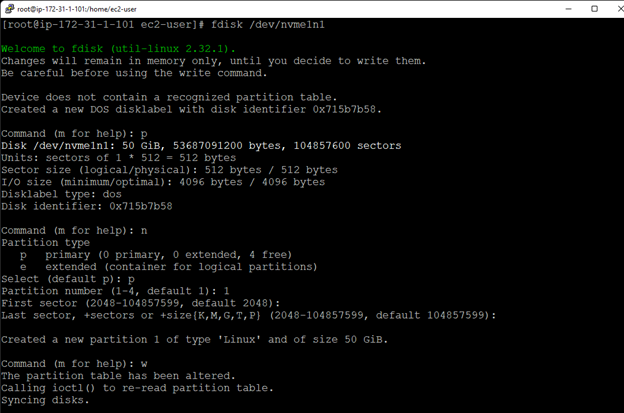
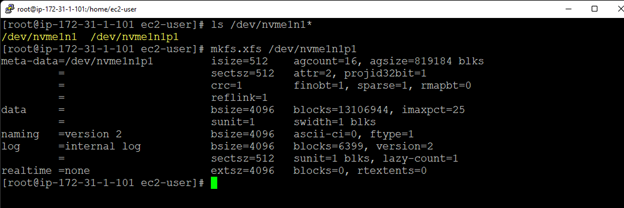
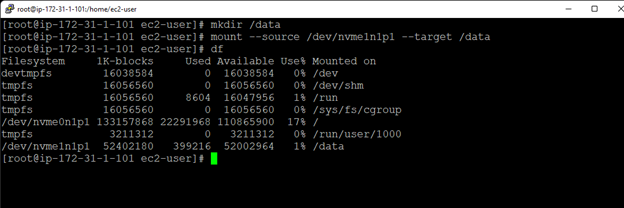
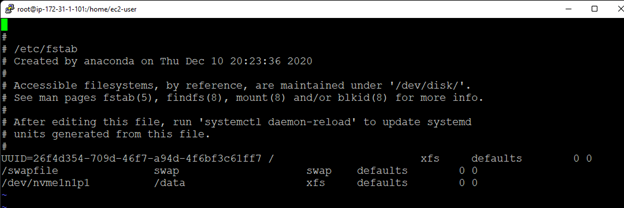
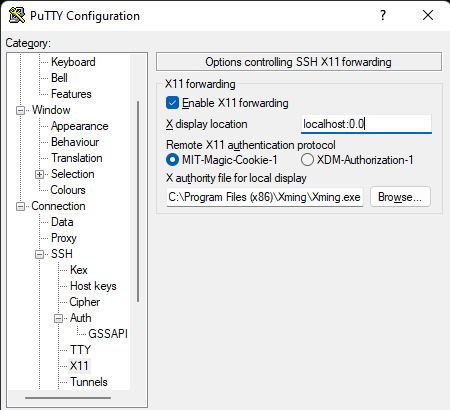
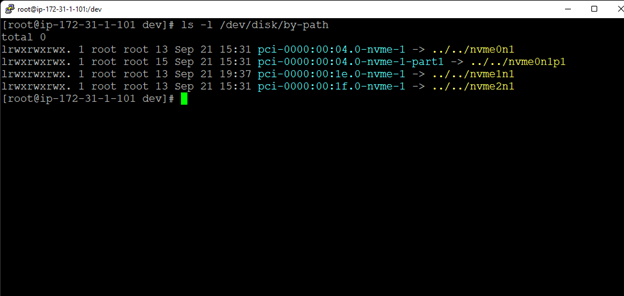
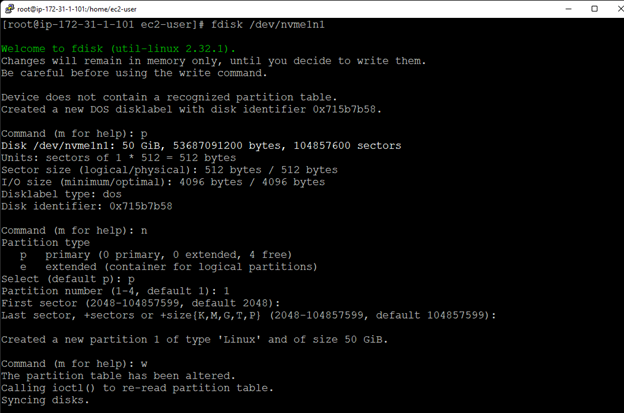
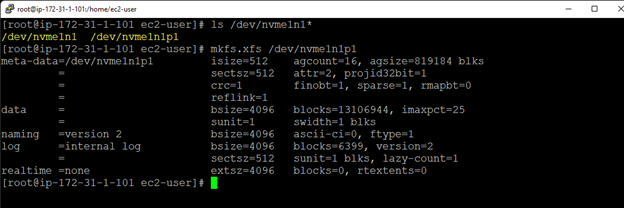
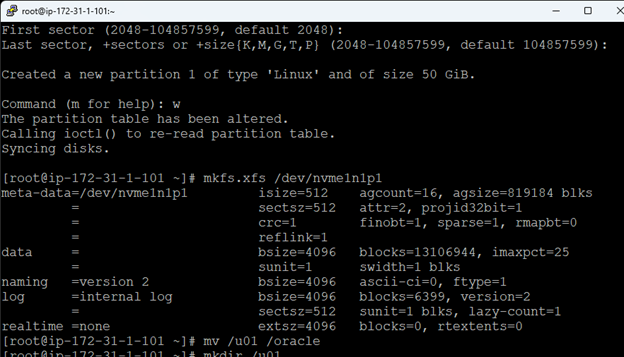
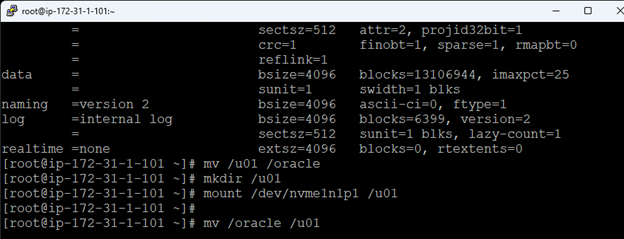
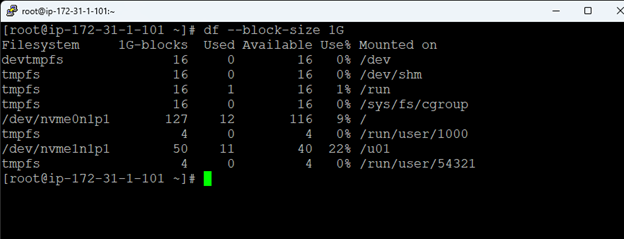
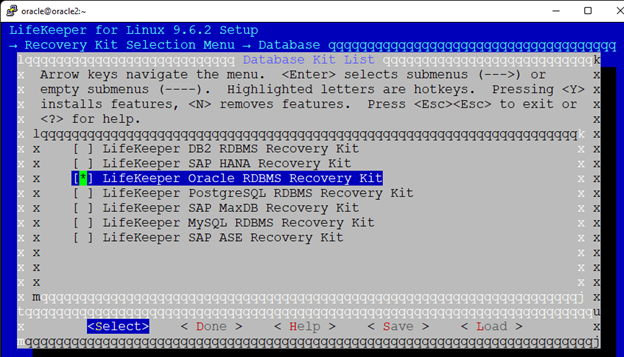
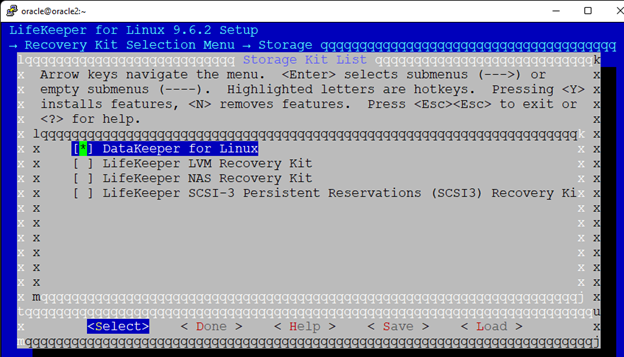
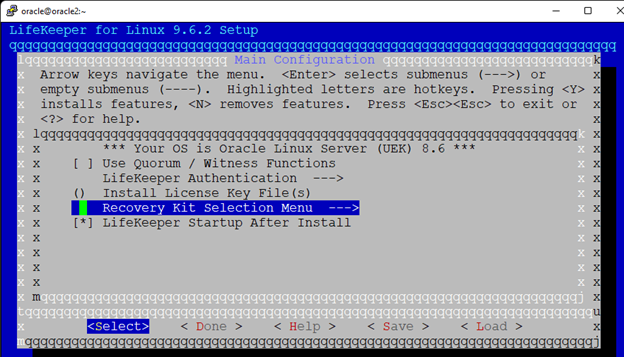
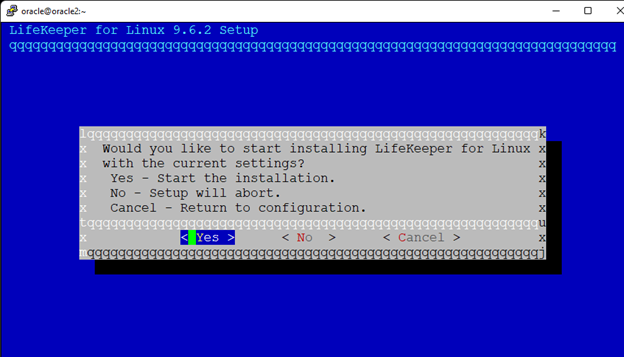
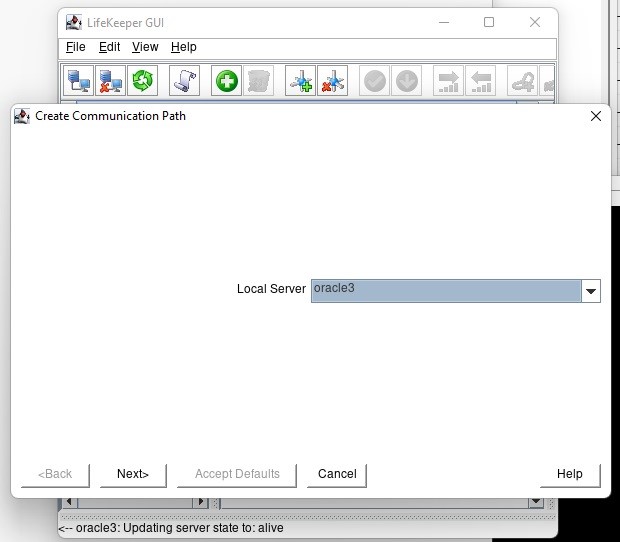
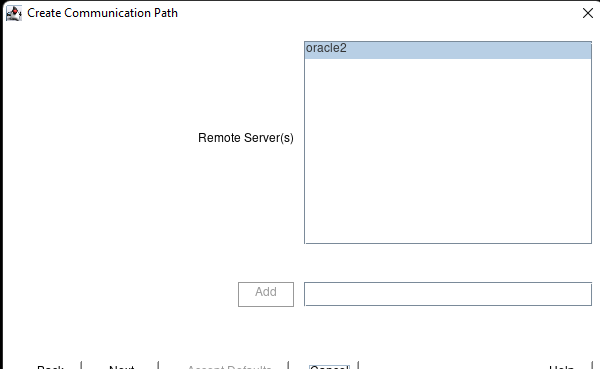
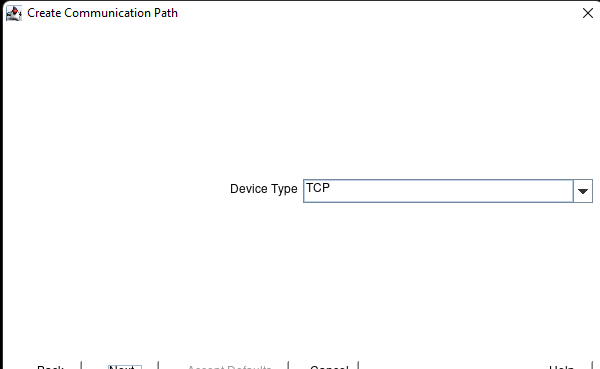
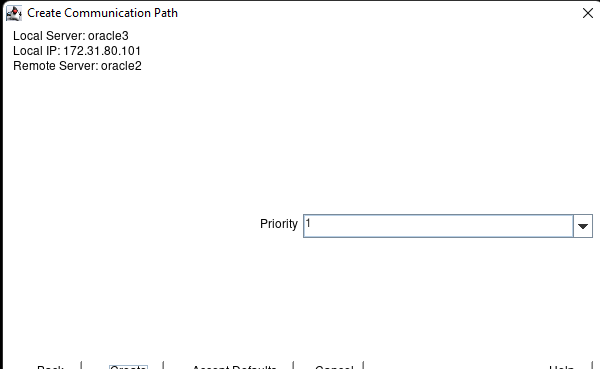
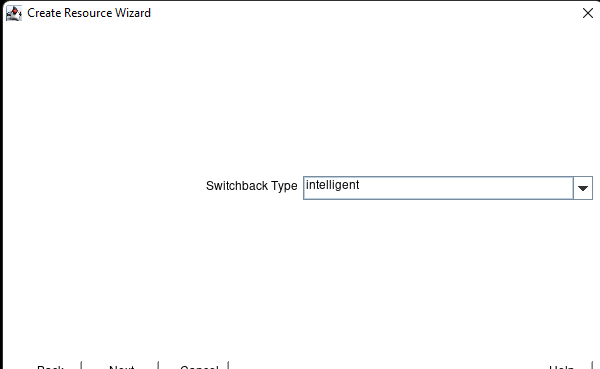
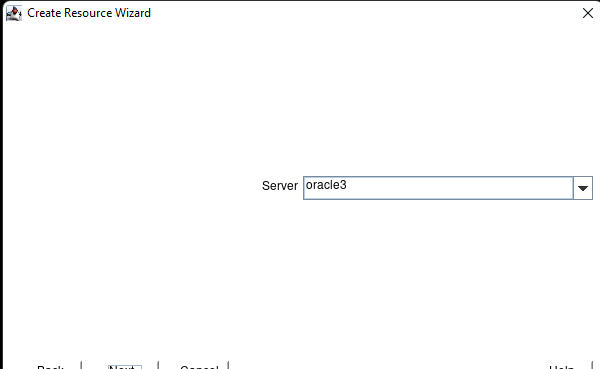
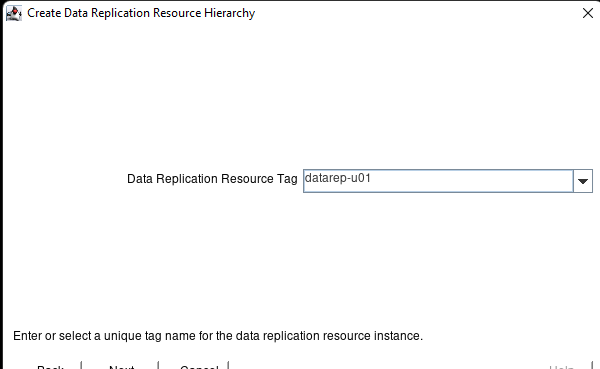
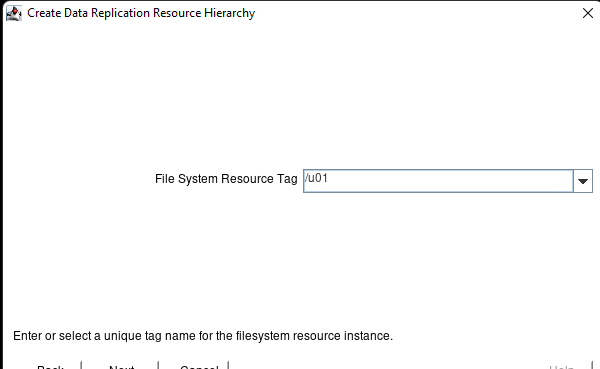
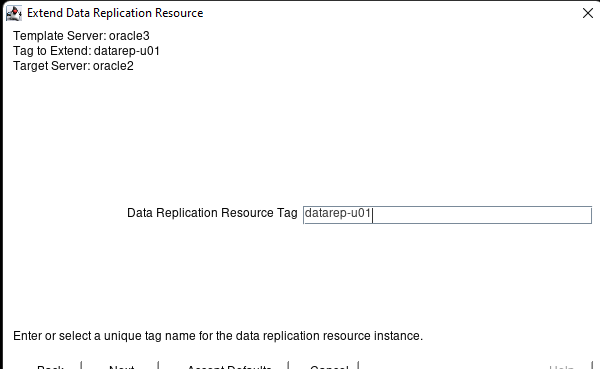
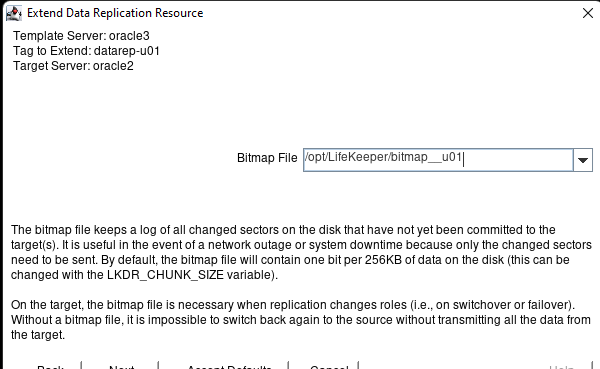
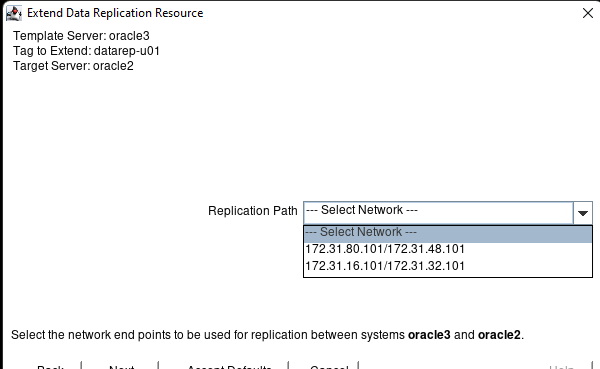
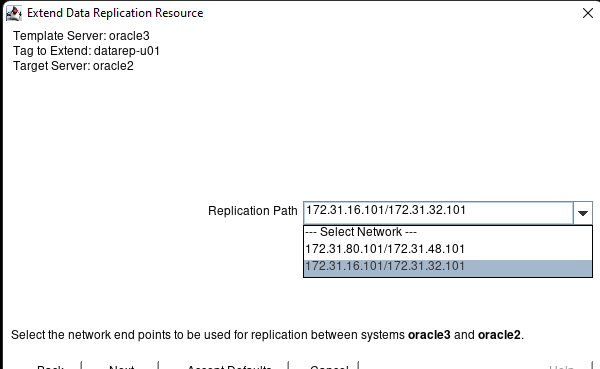
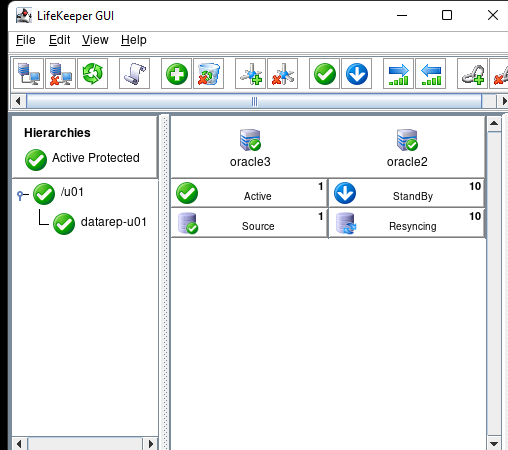
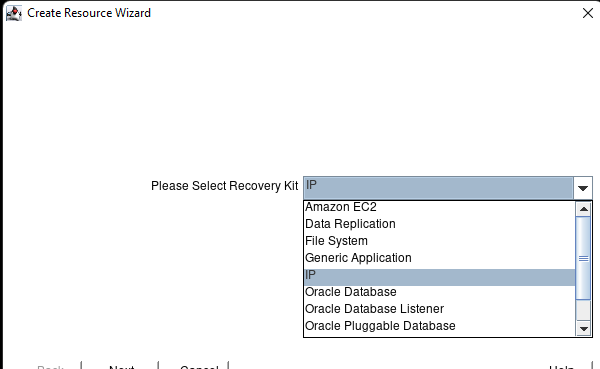
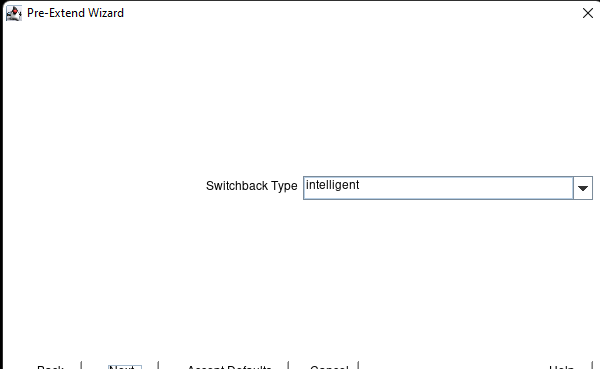
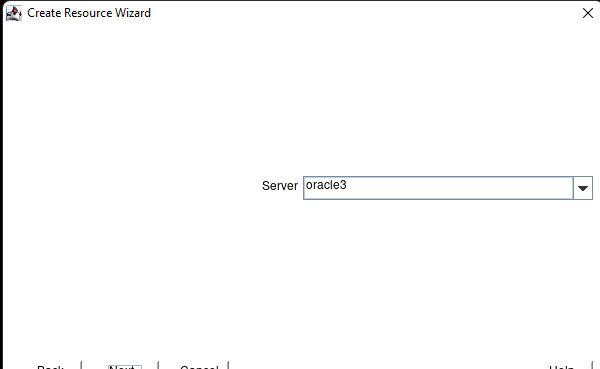
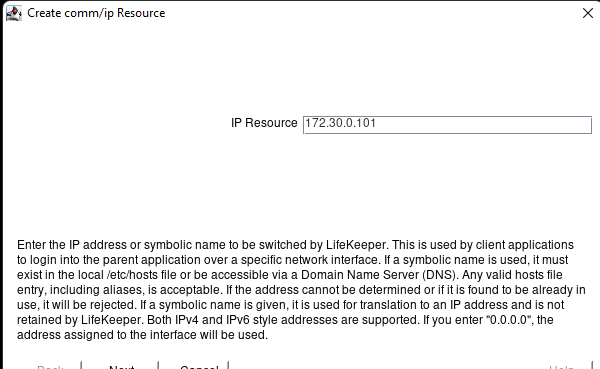
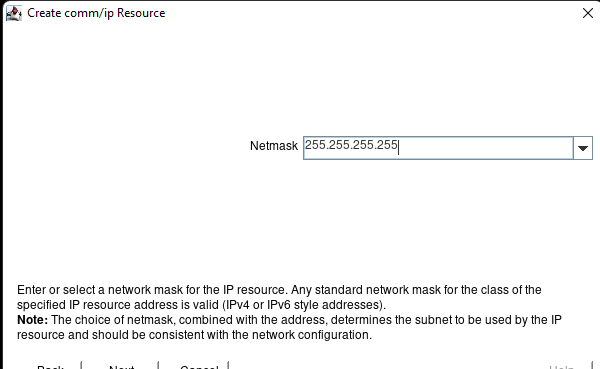
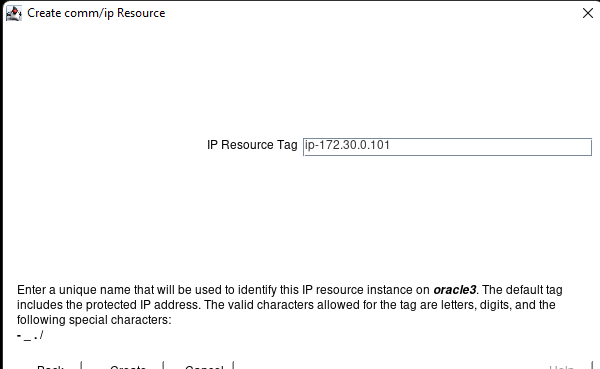
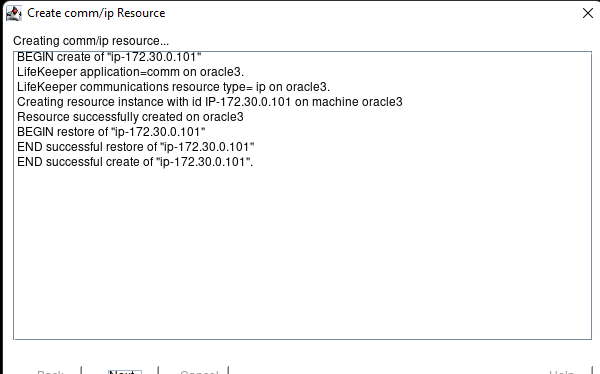
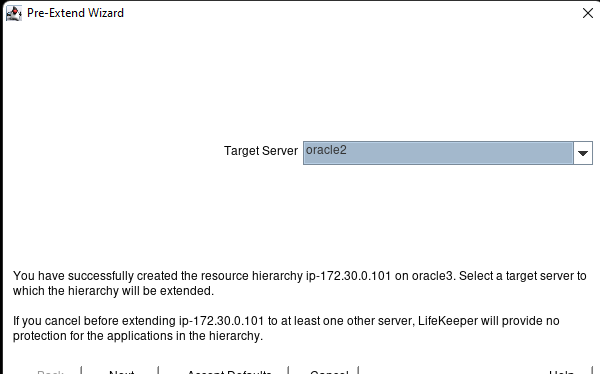
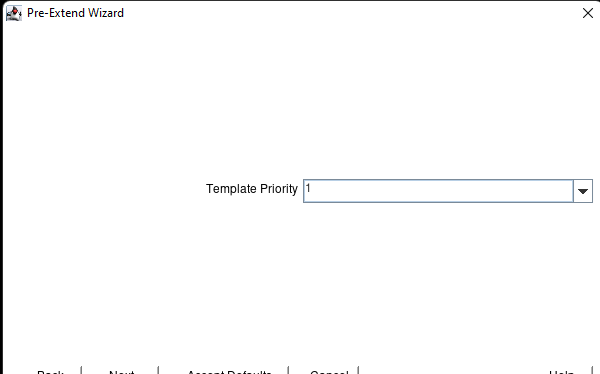
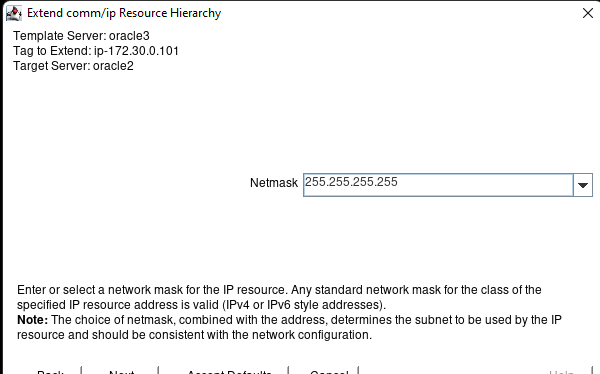
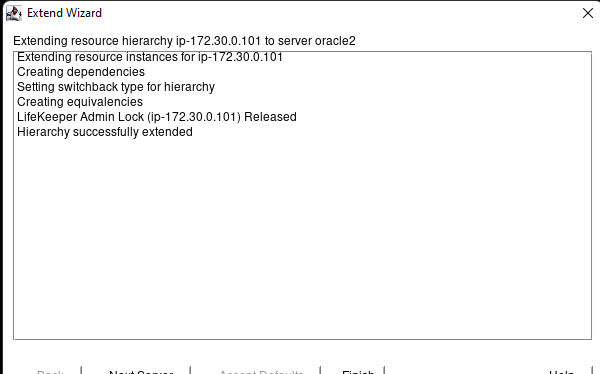
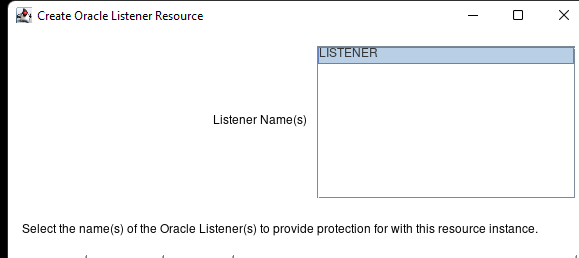
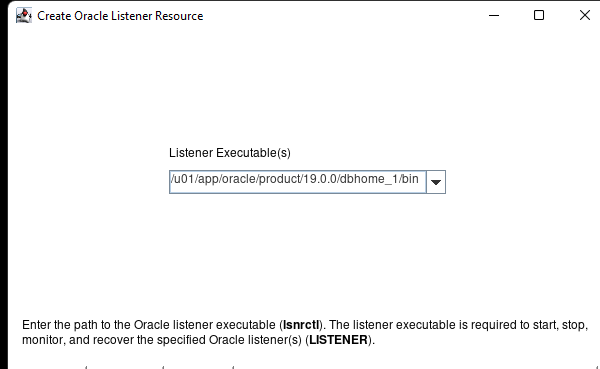
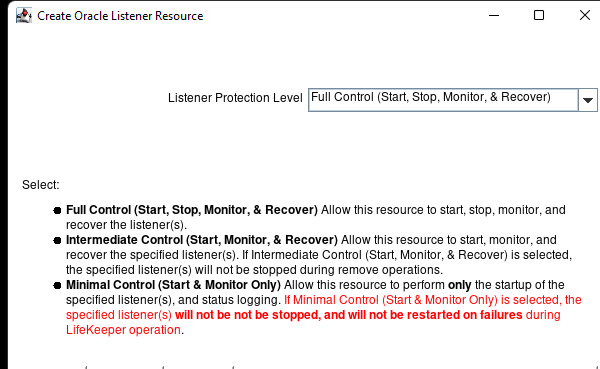
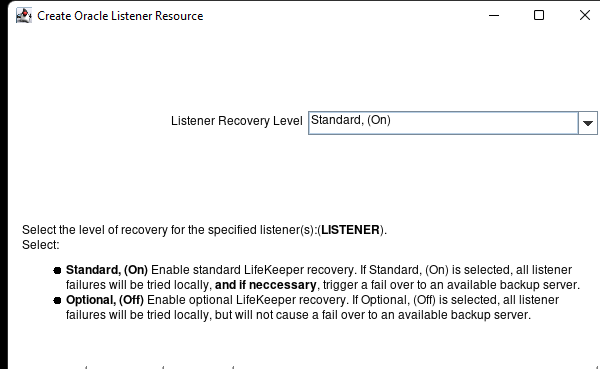
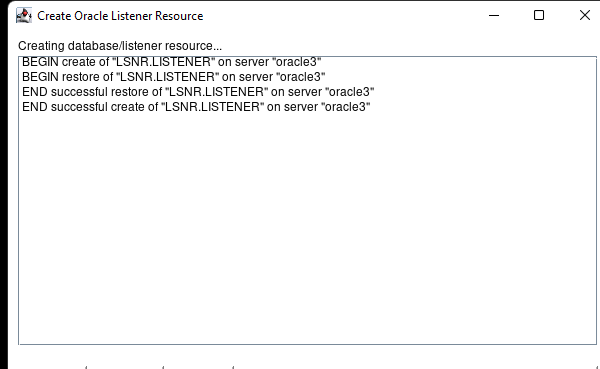
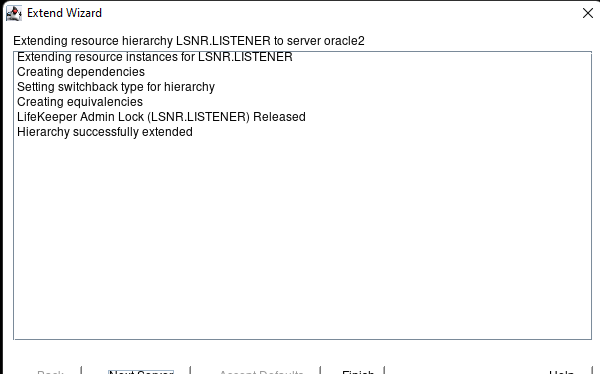
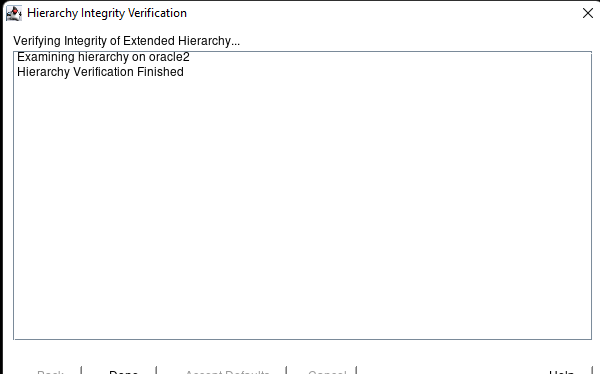
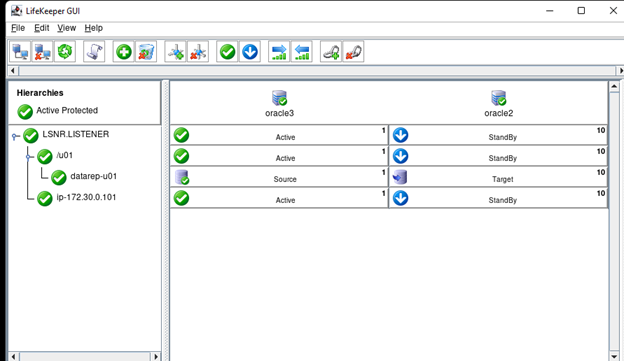
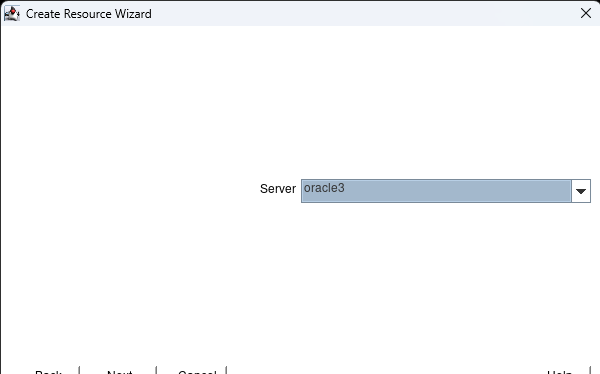
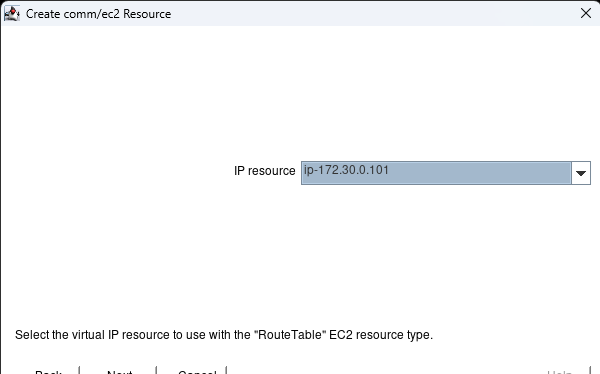
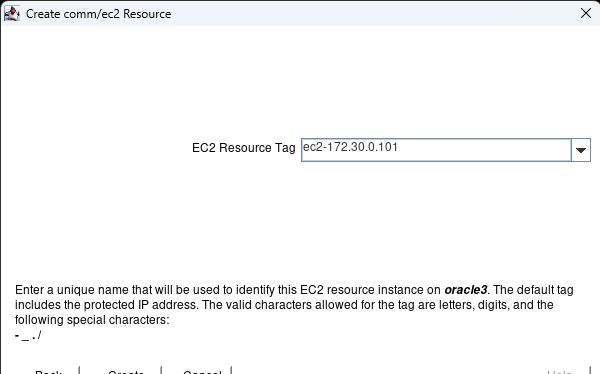
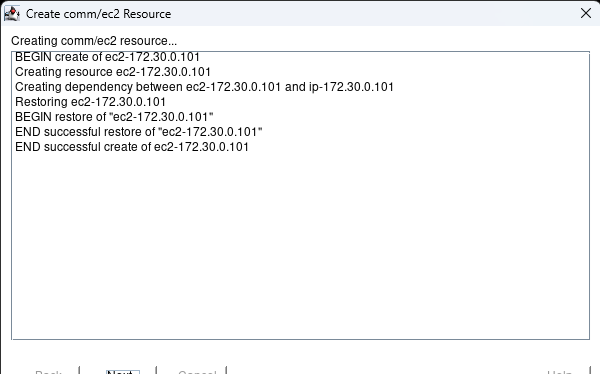
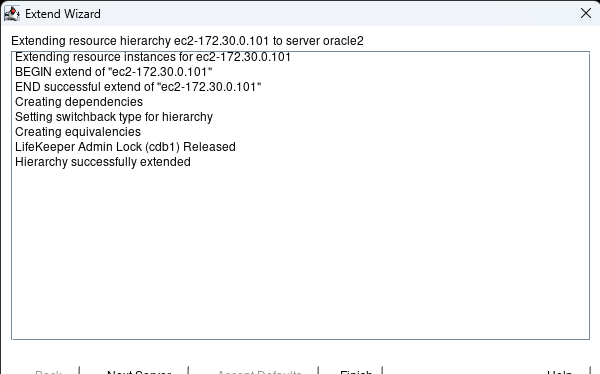
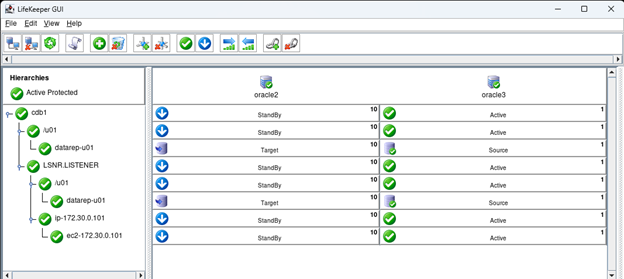
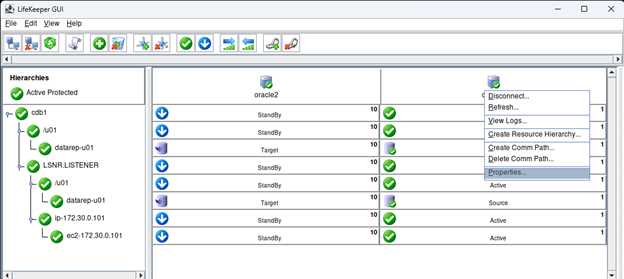
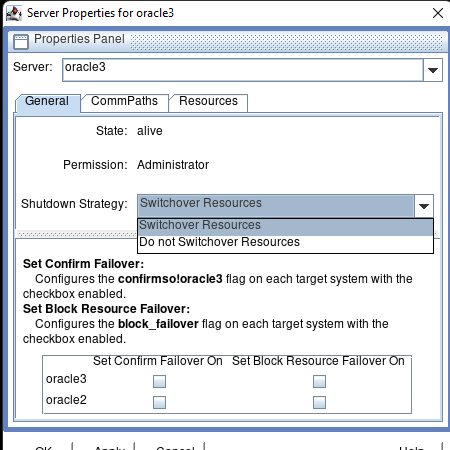
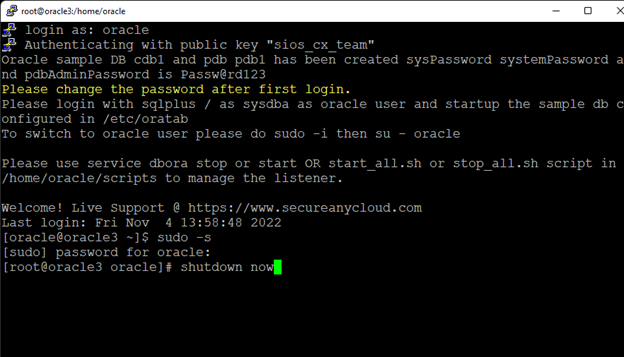
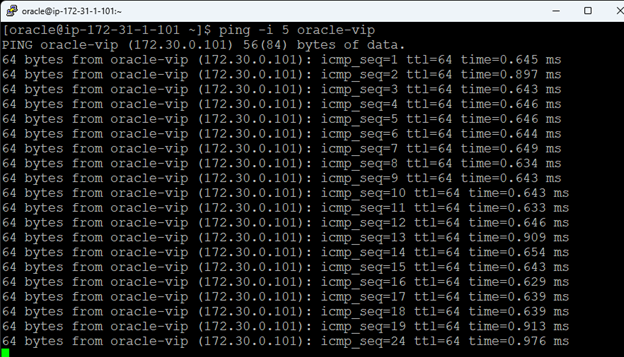
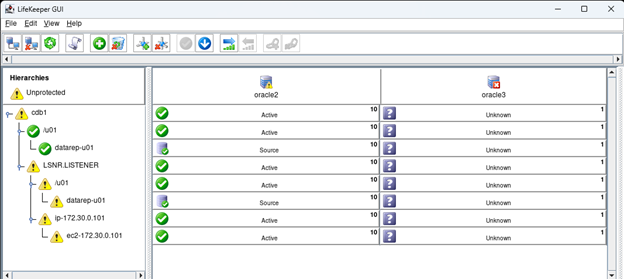
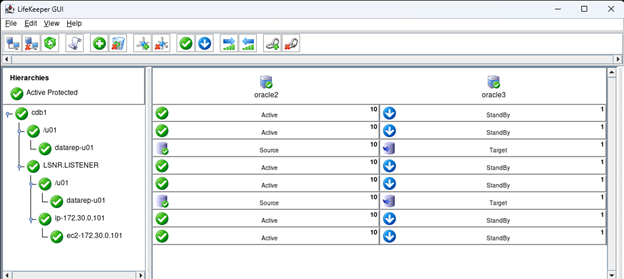
Membuat klaster server HA Oracle Database di AWS |
| Desember 30, 2022 |
Produsen Minuman Terkemuka Melindungi ERP SAP Penting di AWS EC2 Cloud |
| Desember 26, 2022 |
Video: Bagaimana SIOS Memastikan Ketersediaan Tinggi Untuk Industri Jasa KeuanganVideo: Bagaimana SIOS Memastikan Ketersediaan Tinggi Untuk Industri Jasa Keuangan Dalam rangkaian berkelanjutan tentang ketersediaan tinggi (HA) dan pemulihan bencana (DR) untuk berbagai industri, Greg Tucker , Insinyur Dukungan Produk Senior (Windows) di Teknologi SIOS , bergabung dengan kami untuk membagikan wawasannya tentang bagaimana perusahaan melindungi industri keuangan dari downtime dan failover. SIOS hadir secara global di industri keuangan dengan pelanggan mulai dari perbankan komersial, berbagai perusahaan pialang, manajemen kekayaan, perusahaan CPA, dan sebagainya. Tidak ada industri lain yang lebih kritis terhadap misi dan sensitif terhadap downtime dan kegagalan daripada industri keuangan, dengan pelanggan mengandalkan aplikasi penting untuk sistem perbankan online, ATM, dan sistem pembayaran mereka. “Kami menyediakan perangkat lunak kegagalan atau pengelompokan yang akan melindungi aplikasi dan data penting mereka dari waktu henti dan/atau peristiwa bencana,” kata Tucker. Tucker menjelaskan bahwa pada dasarnya, aplikasi kritis diterapkan di server utama, baik itu di tempat atau di cloud, karena dikelompokkan dengan server sekunder atau beberapa server. “Jika perangkat lunak pengelompokan mendeteksi kegagalan, ia akan memindahkan semua sumber daya ke simpul sekunder dan mengembalikan layanan ke pengguna akhir secara otomatis; tidak ada kehilangan data, tidak ada gangguan,” tambahnya. Lihat seluruh wawancara di atas untuk mempelajari lebih lanjut. Sorotan diskusi:
Solusi
Terhubung dengan Greg Tucker ( LinkedIn ) Direproduksi dengan izin dari SIOS |
| Desember 18, 2022 |
Video: Ketersediaan Tinggi untuk Pengelolaan dan Keamanan Gedung |