| April 2, 2023 |
Webinar: Opsi Ketersediaan untuk SQL Server di AWS |
| Maret 29, 2023 |
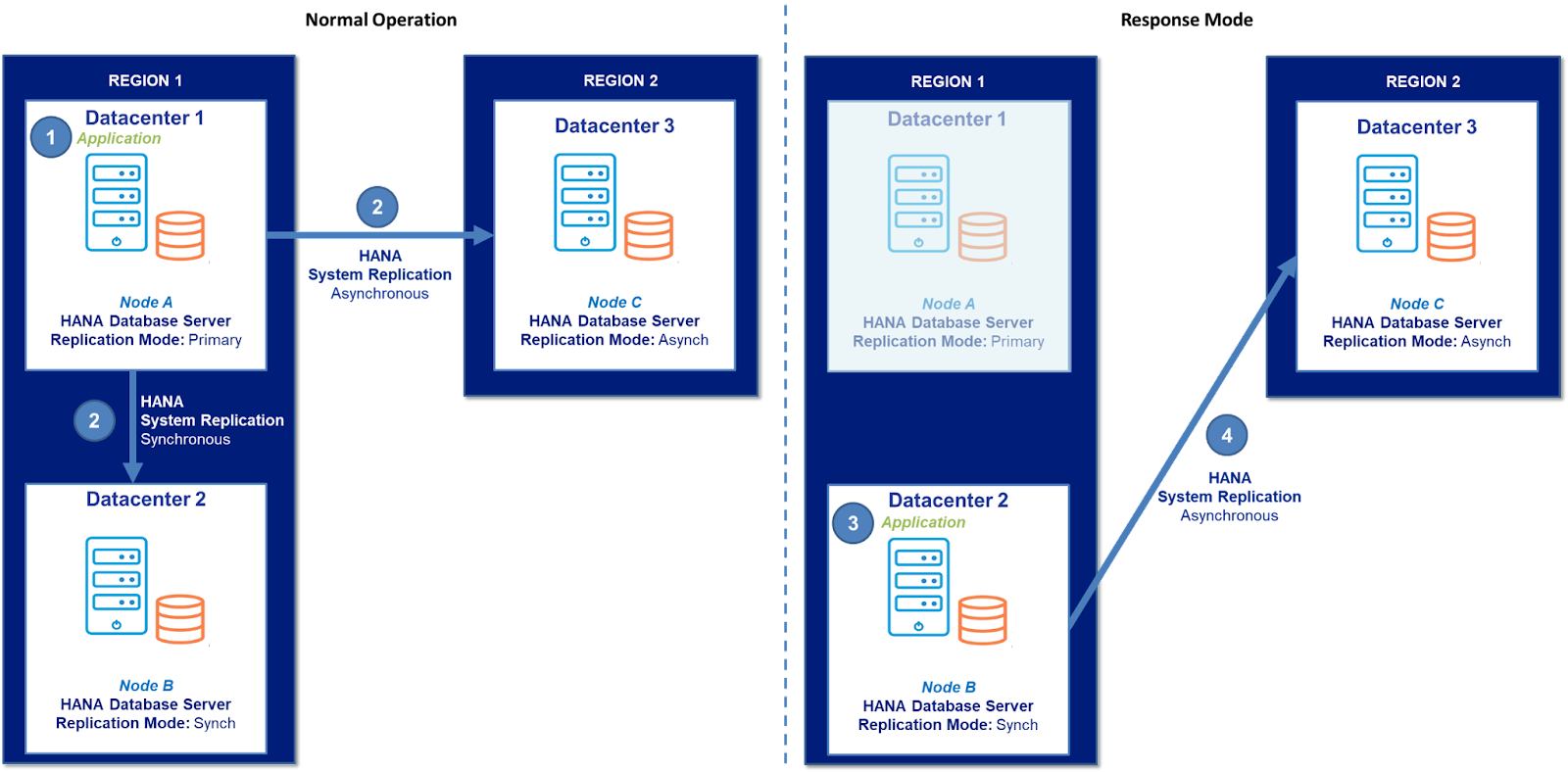
Pemulihan Bencana Terlengkap di Industri untuk Database SAP HANA |
| Maret 24, 2023 |
Webinar: Memaksimalkan Waktu Aktif: Strategi Ketersediaan Tinggi untuk SQL Server dan Lingkungan Multi-Platform |
| Maret 15, 2023 |
3-node Cluster Pertanyaan dan Jawaban yang Sering Diajukan |
| Maret 11, 2023 |
Repatriasi Cloud dan HA |