| Januari 21, 2018 |
Membuat Pilihan Ketersediaan VirtualizationApakah Opsi Ketersediaan Virtualisasi?Microsoft Windows Server 2008 R2 dan vSphere 4.0 baru dirilis. Mari kita lihat beberapa Opsi Ketersediaan Virtualisasi ketika mempertimbangkan ketersediaan server virtual Anda dan aplikasi yang berjalan pada mereka. Saya juga akan memanfaatkan kesempatan ini untuk menjelaskan beberapa fitur yang memungkinkan ketersediaan mesin virtual. Selain itu, saya telah mengelompokkan fitur-fitur ini ke dalam fungsi fungsi mereka untuk membantu menyoroti tujuan mereka. Direncanakan DowntimeTidak aktif downtimeMicrosoft Windows Server Failover Clustering dan VMware's High Availability (HA) adalah solusi yang tersedia untuk melindungi mesin virtual jika terjadi downtime yang tidak terencana. Kedua solusi serupa. Mereka memantau mesin virtual untuk ketersediaan. VM dipindahkan ke node siaga jika ada kegagalan. Kemudian, mesin di-reboot untuk proses pemulihan ini. Tidak ada waktu untuk menyinkronkan memori sebelum failover. Pemulihan bencanaBagaimana cara memulihkan mesin virtual saya jika ada kerugian situs lengkap? Kabar baiknya adalah bahwa virtualisasi membuat proses ini jauh lebih mudah. Mesin virtual hanyalah sebuah file yang dapat diambil dan dipindahkan ke server lain. Hingga titik ini, VMware dan Microsoft sangat mirip dalam fitur dan fungsionalitas ketersediaan mereka. Namun, di sinilah Microsoft benar-benar bersinar. VMware menawarkan Site Recovery Manager yang merupakan produk bagus. Tetapi terbatas dalam dukungan hanya solusi replikasi berbasis array SRM-bersertifikat. Selain itu, proses failover dan failback tidak sepele dan dapat mengambil bagian yang lebih baik dalam sehari untuk melakukan perjalanan pulang-pergi lengkap dari situs DR ke pusat data primer. Itu memang memiliki beberapa fitur bagus seperti pengujian DR. Berdasarkan pengalaman saya dengan solusi Microsoft untuk pemulihan bencana, mereka memiliki solusi yang jauh lebih baik dalam hal pemulihan bencana. Solusi Hyper-V DR MicrosoftSolusi Hyper-V DR Microsoft adalah Windows Server Failover Clustering dalam konfigurasi cluster multi-situs (lihat demo video). Dalam konfigurasi ini, kinerja dan perilaku adalah sama dengan kluster area lokal, namun dapat menjangkau pusat data. Pada dasarnya, Anda benar-benar dapat memindahkan mesin virtual Anda di seluruh pusat data dengan downtime yang sedikit atau tidak ada. Failback adalah proses yang sama, cukup arahkan dan klik untuk memindahkan sumber daya mesin virtual kembali ke pusat data primer. Tidak ada "Pengujian DR" internal. Meskipun saya pikir lebih baik untuk melakukan tes DR yang sebenarnya hanya dalam hitungan satu atau dua menit tanpa downtime yang dapat dilihat. Vendor Replikasi Berbasis HostSatu hal lain yang saya suka tentang klaster multi-situs WSFC adalah bahwa opsi replikasi tidak hanya mencakup vendor replikasi berbasis-array, tetapi juga vendor replikasi berbasis host. Ini benar-benar memberi Anda berbagai solusi replikasi dalam semua rentang harga dan tidak mengharuskan Anda meningkatkan infrastruktur penyimpanan yang ada. Toleransi kesalahanToleransi kesalahan pada dasarnya menghilangkan kebutuhan untuk melakukan reboot mesin virtual jika terjadi kegagalan yang tidak terduga. VMware memiliki keunggulan di sini karena menawarkan VMware FT. Ada beberapa vendor perangkat keras dan perangkat lunak pihak ketiga lainnya yang bermain di ruang ini juga. Ada banyak keterbatasan dan persyaratan ketika datang untuk menerapkan sistem FT. Ini adalah pilihan jika Anda perlu memastikan kegagalan komponen perangkat keras menghasilkan downtime nol vs. menit atau dua yang diperlukan untuk mem-boot VM dalam konfigurasi HA standar. Anda mungkin ingin memastikan bahwa server Anda yang ada sudah penuh dengan CPU siaga panas, RAM, catu daya, dll. Dan Anda memiliki jalur redundan ke jaringan dan penyimpanan. Kalau tidak, Anda mungkin akan membuang uang yang bagus setelah yang buruk. Toleransi kesalahan sangat bagus untuk perlindungan dari kegagalan perangkat keras. Apa yang terjadi jika aplikasi Anda atau sistem operasi mesin virtual berperilaku buruk? Itu adalah ketika Anda memerlukan pengelompokan tingkat aplikasi seperti yang dijelaskan di bawah ini. Ketersediaan AplikasiSemua yang telah saya diskusikan sampai saat ini benar-benar hanya mempertimbangkan kesehatan server fisik dan mesin virtual Anda secara keseluruhan. Ini semua baik dan bagus, namun, apa yang terjadi jika mesin virtual Anda memiliki layar biru? Atau bagaimana jika paket layanan SQL terbaru ini melanggar aplikasi Anda? Dalam kasus tersebut, tidak satu pun dari solusi ini yang akan Anda lakukan sedikit demi sedikit. Bagi aplikasi yang paling kritis, Anda benar-benar harus berkerumun di lapisan aplikasi. Lihat solusi pengelompokan yang berjalan di dalam OS pada mesin virtual vs. di dalam hypervisor. Di dunia Microsoft, ini berarti MSCS / WSFC atau solusi pengelompokan pihak ke-3. Pilihan penyimpanan Anda, saat mengelompokkan dalam mesin virtual, terbatas cakupannya pada target iSCSI atau solusi replikasi berbasis host. Saat ini, VMware benar-benar tidak memiliki solusi untuk masalah ini. Ini akan menunda solusi yang berjalan di dalam mesin virtual untuk memonitor lapisan aplikasi. RingkasanDengan munculnya virtualisasi, itu bukan masalah jika Anda membutuhkan ketersediaan. Dan lebih banyak pertanyaan tentang apa Opsi Ketersediaan Virtualisasi akan membantu memenuhi persyaratan SLA dan / atau DR Anda. Saya harap informasi ini membantu Anda memahami pilihan ketersediaan yang tersedia bagi Anda. Direproduksi dengan izin dari https://clusteringformeremortals.com/2009/08/14/making-sense-of-virtualization-availability-options-2/ Baca kisah sukses kami untuk memahami bagaimana SIOS dapat membantu Anda |
Hapus Tautan Terlemah, Pastikan Konfigurasi Cluster Ketersediaan TinggiMembangun Konfigurasi Cluster Ketersediaan TinggiKetika kami membangun Konfigurasi Cluster Ketersediaan Tinggi, ketersediaan aplikasi Anda hanya sebagus tautan terlemahnya. Apakah ini berarti bahwa jika Anda membeli server hebat dengan segala sesuatu yang berlebihan (CPU, kipas, daya, RAID, RAM, dll) dan SAN super mewah dengan konektivitas multi-jalur. Ditambah dengan beberapa switch SAN dan mengelompokkan aplikasi Anda dengan perangkat lunak pengelompokan favorit Anda. Anda mungkin memiliki aplikasi yang sangat andal – bukan? Yah, belum tentu. Apakah server terhubung ke UPS yang sama? Apakah mereka pada switch jaringan yang sama? Apakah mereka didinginkan oleh unit AC yang sama? Apakah mereka berada di gedung yang sama? Apakah SAN Anda benar-benar dapat diandalkan? Salah satu dari masalah ini antara lain adalah satu titik kegagalan dalam Konfigurasi Cluster Ketersediaan Tinggi. Cari Dan Hapus Tautan Terlemah dalam Konfigurasi ClusterTentu saja, Anda harus tahu kapan "cukup baik" adalah "cukup baik". Anggaran dan SLA Anda akan membantu menentukan apa sebenarnya yang cukup baik. Namun, satu area dimana saya khawatir orang bisa skimping berada di area penyimpanan. Dengan munculnya solusi perangkat lunak iSCSI target murah atau gratis, saya melihat beberapa orang merekomendasikan agar Anda hanya membuang beberapa perangkat lunak target iSCSI di server cadangan dan voila – penyimpanan bersama instan. Ingatlah, saya tidak sedang berbicara tentang solusi OEM iSCSI yang memiliki teknologi failover dan / atau fitur ketersediaan lainnya; atau bahkan solusi virtualisasi penyimpanan seperti FalconStor. Saya sedang berbicara tentang orang yang memiliki server yang menjalankan Windows Server 2008 yang telah dimuatinya dengan penyimpanan dan ingin mengubahnya menjadi target iSCSI. Ini bagus di laboratorium. Tetapi jika Anda serius tentang HA, Anda harus berpikir lagi. Bahkan Microsoft hanya menyediakan perangkat lunak iSCSI target mereka kepada pembangun OEM berkualitas yang berpengalaman dalam memberikan array penyimpanan kelas enterprise. Apa yang Sebenarnya Anda Dapatkan?Pertama-tama, ini adalah Windows. Tidak beberapa OS yang dikeraskan dibangun untuk hanya melayani penyimpanan. Ini akan memerlukan perawatan, update keamanan, perbaikan perangkat keras, dll. Ini pada dasarnya memiliki keandalan yang sama dengan server aplikasi yang Anda coba lindungi. Apakah masuk akal untuk mengelompokkan server aplikasi Anda. Namun gunakan kelas server dan OS yang sama untuk meng-host penyimpanan Anda? Anda pada dasarnya telah memindahkan satu titik kegagalan Anda dari server aplikasi Anda dan memindahkannya ke server penyimpanan Anda. Ini bukan langkah yang cerdas sejauh yang saya ketahui. Beberapa perangkat lunak target Enterprise Class iSCSI mencakup perangkat lunak replikasi sinkron dan / atau asinkron serta kemampuan snapshot. Fungsi ini tentu saja membantu dalam hal tujuan titik pemulihan (RPO) Anda. Meskipun itu tidak akan membantu tujuan waktu pemulihan Anda (RTO) kecuali jika failover otomatis dan mulus ke perangkat lunak pengelompokan Anda. Katakanlah array penyimpanan iSCSI utama gagal di tengah malam. Siapa yang akan ada di sana untuk mengaktifkan salinan yang direplikasi? Anda mungkin jatuh selama beberapa waktu sebelum Anda bahkan menyadari ada masalah. Sekali lagi, ini mungkin "cukup baik"; Anda hanya perlu menyadari apa yang Anda sign up. Apakah itu Konfigurasi Cluster Ketersediaan Tinggi yang Anda cari? SIOS DataKeeperSatu hal yang dapat Anda lakukan untuk meningkatkan keandalan server target iSCSI Anda adalah menggunakan produk replikasi seperti SteelEye DataKeeper Cluster Edition untuk menghilangkan satu titik kegagalan. Mari saya gambarkan.  Jika kami mengambil konfigurasi yang sama seperti ditunjukkan di atas dan menambahkan target siaga panas iSCSI menggunakan SteelEye DataKeeper Cluster Edition untuk melakukan replikasi DAN failover otomatis, Anda baru saja memberi Anda solusi target iSCSI tingkat ketersediaan yang sama sekali baru. Solusi itu akan terlihat sangat mirip dengan ini. 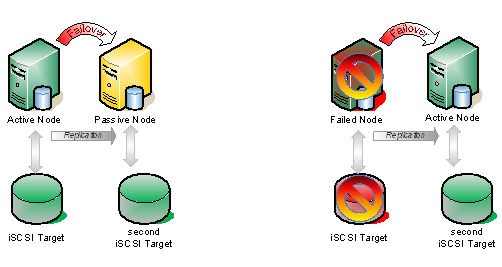 Perbedaan utama dalam solusi SteelEye DataKeeper Cluster Edition vs solusi replikasi yang diberikan oleh beberapa vendor target iSCSI adalah dalam integrasi dengan WSFC. Pertanyaan untuk meminta vendor solusi iSCSI Anda adalah ini … Apa yang terjadi jika saya menarik kabel daya pada server target iSCSI yang aktif? Jika proses pemulihan adalah prosedur manual, ini bukan solusi HA yang benar. Tetapi bagaimana jika itu otomatis dan sepenuhnya terintegrasi dengan WSFC? Kemudian Anda memiliki tingkat ketersediaan yang jauh lebih tinggi dan telah menghilangkan array iSCSI sebagai satu titik kegagalan. Mengobrol dengan kami juga untuk mencapai Konfigurasi Cluster Ketersediaan Tinggi Direproduksi dengan izin dari Clusteringformortals. |
|
| Januari 20, 2018 |
Steeleye Datakeeper Cluster Edition Memenangkan Windows It Pro Best High Availability / Disaster Recovery AwardsDengan senang hati saya umumkan bahwa Windows IT Pro telah memberikan SteelEye DataKeeper Cluster Edition sebagai Produk Ketersediaan dan Pemulihan Bencana Terbaik dalam dua kategori; Penghargaan Emas Pilihan Komunitas dan Penghargaan Perak Terbaik dari para editor.
Saya sangat bangga menjadi bagian dari tim SteelEye DataKeeper dan saya menghargai semua komunitas Windows IT Pro yang memilih kami dalam penghargaan Community Choice! Direproduksi dengan izin dari https://clusteringformeremortals.com/2009/11/20/steeleye-datakeeper-cluster-edition-wins-windows-it-pro-best-high-availabilitydisaster-recovery-awards/ |
| Januari 18, 2018 |
Bagaimana Replikasi Asinkron Bisa Digunakan dalam Cluster Multi-Situs? Bukankah Data Out Of Sync?Bagaimana Replikasi Asinkron Bisa Digunakan dalam Cluster Multi-Situs? Bukankah Data Out Of Sync?Saya telah mengajukan pertanyaan ini lebih dari beberapa kali, jadi saya pikir saya akan menjawabnya di posting blog pertama saya. Jawaban dasarnya adalah ya, Anda bisa kehilangan data dalam kegagalan yang tak terduga saat menggunakan replikasi asinkron dalam cluster multi-situs. Dalam dunia ideal, setiap perusahaan akan memiliki koneksi serat gelap ke situs DR mereka dan menggunakan replikasi sinkron dengan cluster multi-situs mereka, sehingga menghilangkan kemungkinan kehilangan data. Namun, kenyataannya adalah bahwa dalam banyak kasus, konektivitas WAN ke situs DR memiliki latency terlalu banyak untuk mendukung replikasi sinkron. Dalam kasus tersebut, replikasi asinkron adalah alternatif yang sangat baik. Apa Pilihan Saya?Ada lebih dari beberapa opsi ketika memilih solusi replikasi asinkron untuk digunakan dengan klaster multi-situs WSFC Anda. Ini termasuk solusi berbasis array dari perusahaan seperti EMC, IBM, HP, dll. dan solusi berbasis host, seperti yang dekat dan saya sukai, "SteelEye DataKeeper Cluster Edition". Karena saya mengenal DataKeeper dengan baik, saya akan menjelaskan bagaimana semua ini bekerja dari calon DataKeeper. Bagaimana dengan SteelEye DataKeeper?Saat menggunakan SteelEye DataKeeper dan replikasi asinkron, kami mengizinkan sejumlah penulisan untuk disimpan dalam antrian asinkron. Jumlah penulisan yang dapat antri ditentukan oleh "tanda air tinggi". Ini adalah nilai yang dapat disesuaikan yang digunakan oleh DataKeeper untuk menentukan berapa banyak data yang bisa berada dalam antrian sebelum kondisi mirror diubah dari "mirroring" menjadi "dijeda". Status "dijeda" juga dimasukkan kapan saja ada kegagalan komunikasi antara server sekunder dan primer. Sementara dalam keadaan berhenti, failover otomatis di cluster multi-situs dinonaktifkan, sehingga membatasi jumlah data yang dapat hilang dalam kegagalan yang tidak terduga. Jika kumpulan data asli dianggap "hilang selamanya", maka data yang tersisa pada server target dapat dibuka secara manual dan node cluster kemudian dapat dibawa ke layanan. Saat berada dalam keadaan "berhenti sejenak", DataKeeper mengizinkan antrian asinkron mengalir sampai mencapai "tanda air rendah", dan pada saat mana cermin memasuki keadaan "resync" sampai semua data sekali lagi sinkron. Pada saat itu, cermin sekali lagi berada dalam keadaan "mirroring" dan failover otomatis sekali lagi diaktifkan. Selama link WAN Anda tidak jenuh atau rusak, Anda seharusnya tidak pernah melihat lebih dari beberapa menulis pada waktu tertentu dalam antrian asinkron ini. Dalam kegagalan yang tak terduga (pikirkan kabel daya yang ditarik) Anda akan kehilangan tulisan yang ada di antrian asinkron. Ini adalah trade off yang Anda buat ketika Anda menginginkan tujuan titik pemulihan yang mengagumkan (RPO) dan tujuan waktu pemulihan (RTO) yang Anda capai dengan cluster multi-situs, namun tautan WAN Anda memiliki latensi terlalu banyak untuk mendukung replikasi sinkron secara efektif. Coba The SteelEye DataKeeperLuangkan waktu untuk memantau Antrian DataKeeper Async melalui Windows Performance Logs and Alerts. Saya pikir Anda akan terkejut menemukan bahwa sebagian besar waktu antrian async kosong karena efisiensi mesin replikasi DataKeeper. Bahkan di masa-masa penulisan yang berat, antrian async jarang tumbuh sangat besar dan selalu terkuras segera. Jadi jumlah data yang berisiko pada waktu tertentu minimal. Dibandingkan dengan alternatif dalam bencana untuk dipulihkan dari cadangan semalam, jumlah penulisan yang bisa Anda hilangkan dalam kegagalan tak terduga menggunakan replikasi asinkron sangat minim! Tentu saja, ada beberapa kasus di mana bahkan kehilangan satu menulis pun tidak dapat ditolerir. Dalam kasus tersebut, disarankan untuk menggunakan opsi replikasi sinkron SteelEye DataKeeper di koneksi LAN latency berkecepatan tinggi dan rendah. Diproduksi ulang dengan izin dari Clusteringformeremortals.com |
| November 13, 2017 |
Berlangganan Informasi Data IT Shift dari Ilmu Komputer ke Ilmu DataSaat ini, hampir setiap perusahaan besar memiliki bagian virtual, atau semua, dari pusat data mereka. Dengan virtualisasi, tim TI mendapatkan akses ke berbagai variasi dan volume data mesin real-time yang ingin mereka gunakan untuk memahami dan memecahkan masalah di lingkungan operasi TI mereka. Namun, kompleksitas pengelolaan lingkungan TI virtual menekankan departemen TI tradisional. Akibatnya, IT pro menemukan bahwa solusinya terletak pada data dan alat berbasis kecerdasan buatan yang dapat memanfaatkannya. Ilmu Data untuk RescueSeiring dengan tingkat data digital di seluruh dunia yang terus meningkat, perusahaan bekerja untuk menemukan nilai bisnis dalam data mereka, dan untuk menyesuaikan strategi sains komputer mereka ke pasar sains data yang berkembang. Alat manajemen dan pemantauan lawas menggunakan pendekatan yang sama dengan yang mereka gunakan untuk lingkungan server fisik – yaitu dengan melihat silo diskrit (jaringan, penyimpanan, infrastruktur, aplikasi). Mereka menggunakan beberapa ambang batas yang ditetapkan secara manual untuk berfokus pada metrik individual – utilisasi CPU, pemanfaatan memori, latensi jaringan, dll., Di dalam setiap silo. Pendekatan berbasis ambang ini berasal dari lingkungan server fisik yang relatif statis dan dipahami dengan baik yang telah terbukti tidak efektif dalam menangani kompleksitas lingkungan virtual saat ini. Tidak seperti rekan-rekan mereka di lingkungan server fisik, komponen di lingkungan virtual berbagi sumber daya host, menciptakan hubungan yang kompleks dan saling tergantung antara keduanya. Mereka juga sangat dinamis, memungkinkan TI untuk terus menciptakan dan memindahkan beban kerja di VM. IT pro tidak dapat lagi membuat keputusan berdasarkan pendekatan ilmu komputer manual kemarin dan menganalisis peringatan dari silo tunggal pada satu waktu. Inilah sebabnya mengapa perusahaan beralih ke pendekatan "ilmu data" yang memanfaatkan disiplin ilmu AI yang canggih dalam pembelajaran mesin dan belajar secara mendalam untuk mendapatkan solusi otomatis menyeluruh untuk menghilangkan proses manual pemecahan masalah yang problematis dan mengoptimalkan lingkungan virtual. Mesin Belajar Analytics Tools Memberikan JawabanAlih-alih memonitor metrik individu sebagai alat berbasis ambang, solusi berbasis pembelajaran mesin canggih mempelajari perilaku kompleks komponen yang saling terkait saat mereka berubah dari waktu ke waktu. Mereka dapat mempertimbangkan beberapa metrik komponen terkait secara bersamaan. Akibatnya, mereka memberikan informasi yang akurat dan akurat tentang lingkungan virtual daripada alat pembelajaran mesin primitif atau alat berbasis ambang tradisional. Alih-alih menciptakan "badai peringatan", mereka mengidentifikasi insiden bermakna yang terkait dengan perilaku abnormal pada waktu tertentu dalam hari, minggu, bulan dan tahun. Dan karena pembelajaran mesin sangat penting dalam desain, tidak ada konfigurasi manual yang diperlukan. Solusi pembelajaran mesin yang canggih, bisa berjalan dan berjalan dalam hitungan menit dan segera belajar perilaku. Akibatnya, pergeseran ke pendekatan berbasis perilaku data-sentris ini memiliki implikasi besar yang secara signifikan memberdayakan profesional TI. IT pro akan selalu membutuhkan keahlian domain dalam ilmu komputer, tapi kemampuan analisis apa yang dibutuhkan TI agar efektif di dunia berbasis AI yang baru ini? Alih-alih menghabiskan hari-hari mereka untuk bereaksi dan memperbaiki masalah kinerja aplikasi, TI akan mengalihkan fokus mereka dari mendiagnosis masalah untuk secara proaktif memprediksi dan menghindarinya sejak awal. Membebaskan kebutuhan untuk menyediakan lebih banyak untuk memastikan kinerja dan keandalan, mereka akan dapat mencari cara untuk mengoptimalkan efisiensi dan menghabiskan waktu mereka dengan fokus pada sasaran yang lebih besar. Hal ini memungkinkan TI untuk memberikan nilai bisnis sejati, dan mengerjakan proyek yang mendorong tujuan perusahaan ke depan. Umumnya, nilai seperti itu memberi TI suara penting dalam manajemen senior, membawa mereka ke dalam proses pengambilan keputusan dan menutup kesenjangan antara TI dan operasi. Dan karena TI memahami dan menggunakan alat analisis berbasis pembelajaran mesin, mereka akan berada di garis depan untuk membangun fondasi otomasi dan masa depan pusat data mandiri. Bio Jim: Jim Shocrylas adalah Direktur Manajemen Produk di SIOS. Jim memiliki lebih dari 20 tahun di industri TI, terakhir sebagai Portfolio Manager untuk Divisi Emerging Technologies EMC. |

