| November 7, 2018 |
Azure Outage Post Mortem Bagian 2 |
| November 6, 2018 |
Azure Outage Post-Mortem Bagian 1 |
| November 5, 2018 |
Mengkonfigurasi File Server Failover Cluster di Azure Across Availability Zones |
| November 4, 2018 |
Panduan Memulai Cepat: Cluster Server SQL Pada Windows Server 2008 R2 Di Azure |
| November 2, 2018 |
Strip Bersama Beberapa Disk Dalam Ruang Penyimpanan Sederhana |

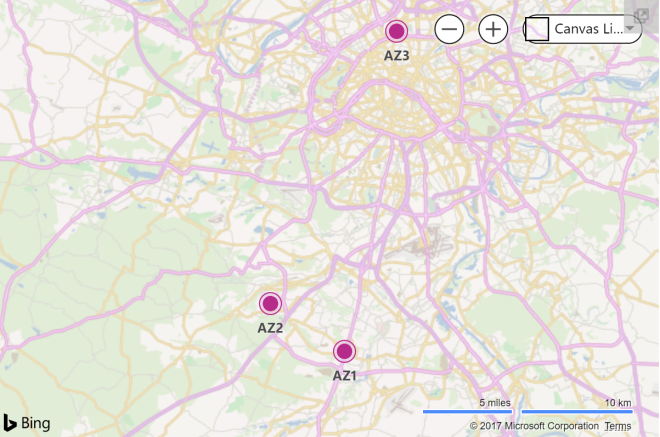 Dalam semua kasus kecuali yang paling ekstrim, mereplikasi data di Zona Ketersediaan harus cukup untuk perlindungan data. Beberapa aplikasi seperti SQL Server telah dibangun dalam teknologi replikasi. Namun untuk berbagai aplikasi, sistem operasi dan tipe data, lakukan selidiki replikasi replikasi level blok SANless. Solusi cluster SANless secara tradisional telah digunakan untuk cluster multisite. Namun teknologi yang sama juga dapat digunakan di cloud di Zona Ketersediaan, Wilayah, atau Hybrid-Cloud untuk ketersediaan tinggi dan pemulihan bencana. Menerapkan cluste
Dalam semua kasus kecuali yang paling ekstrim, mereplikasi data di Zona Ketersediaan harus cukup untuk perlindungan data. Beberapa aplikasi seperti SQL Server telah dibangun dalam teknologi replikasi. Namun untuk berbagai aplikasi, sistem operasi dan tipe data, lakukan selidiki replikasi replikasi level blok SANless. Solusi cluster SANless secara tradisional telah digunakan untuk cluster multisite. Namun teknologi yang sama juga dapat digunakan di cloud di Zona Ketersediaan, Wilayah, atau Hybrid-Cloud untuk ketersediaan tinggi dan pemulihan bencana. Menerapkan cluste

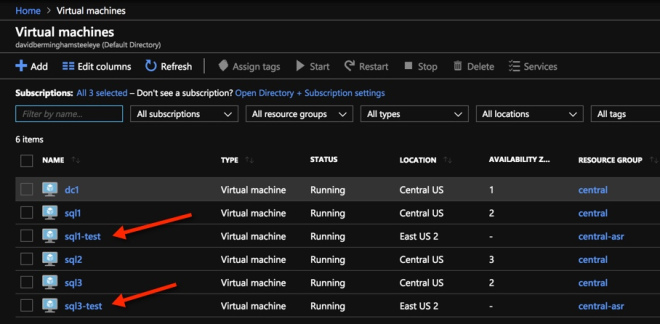 a menggunakan ASR untuk mereplikasi SQL1 dan SQL3 dari Central ke Timur US 2 dan melakukan uji failover. Selain tidak menempatkan VM dalam AZs di AS Timur 2 tampaknya berfungsi. [/ Caption] Saya berharap untuk mengetahui lebih lanjut tentang batasan ini di konferensi Ignite. Meskipun keterbatasan ini tidak sama pentingnya dengan Managed Disk. Karena Zona Ketersediaan belum tersedia secara luas. Jadi semoga ASR akan mengambil dukungan untuk Zona Ketersediaan karena wilayah lain menerangi Zona Ketersediaan dan mereka lebih banyak diadopsi.
a menggunakan ASR untuk mereplikasi SQL1 dan SQL3 dari Central ke Timur US 2 dan melakukan uji failover. Selain tidak menempatkan VM dalam AZs di AS Timur 2 tampaknya berfungsi. [/ Caption] Saya berharap untuk mengetahui lebih lanjut tentang batasan ini di konferensi Ignite. Meskipun keterbatasan ini tidak sama pentingnya dengan Managed Disk. Karena Zona Ketersediaan belum tersedia secara luas. Jadi semoga ASR akan mengambil dukungan untuk Zona Ketersediaan karena wilayah lain menerangi Zona Ketersediaan dan mereka lebih banyak diadopsi.


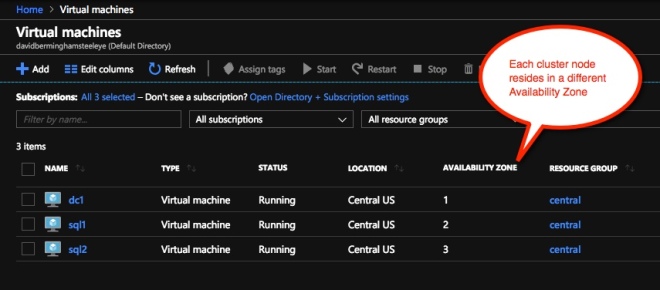 stikan untuk menambahkan setiap node cluster ke Zone Ketersediaan yang berbeda. Jika Anda memanfaatkan File Share Witness, ia harus berada di 3rd Availability Zone. [/ Caption]
stikan untuk menambahkan setiap node cluster ke Zone Ketersediaan yang berbeda. Jika Anda memanfaatkan File Share Witness, ia harus berada di 3rd Availability Zone. [/ Caption] Pastikan setiap node cluster menggunakan IP statis [/ caption]
Pastikan setiap node cluster menggunakan IP statis [/ caption] Akun layanan harus merupakan akun domain yang ada di grup admin lokal pada setiap node. Setelah DataKeeper diinstal dan dilisensikan pada setiap node, Anda harus mereboot server.
Akun layanan harus merupakan akun domain yang ada di grup admin lokal pada setiap node. Setelah DataKeeper diinstal dan dilisensikan pada setiap node, Anda harus mereboot server. Untuk membuat DataKeeper Volume Resource Anda harus memulai UI DataKeeper dan terhubung ke kedua server. Terhubung ke SQL1 [/ caption] Terhubung ke SQL2 [/ caption] Setelah Anda terhubung ke setiap server, Anda siap untuk membuat Volume DataKeeper Anda. Klik kanan pada Jobs dan pilih "Buat Pekerjaan
Untuk membuat DataKeeper Volume Resource Anda harus memulai UI DataKeeper dan terhubung ke kedua server. Terhubung ke SQL1 [/ caption] Terhubung ke SQL2 [/ caption] Setelah Anda terhubung ke setiap server, Anda siap untuk membuat Volume DataKeeper Anda. Klik kanan pada Jobs dan pilih "Buat Pekerjaan " Berikan pekerjaan nama dan deskripsi.
" Berikan pekerjaan nama dan deskripsi.  Pilih server sumber Anda, IP dan volume. Alamat IP adalah apakah lalu lintas replikasi akan bepergian.
Pilih server sumber Anda, IP dan volume. Alamat IP adalah apakah lalu lintas replikasi akan bepergian.  Pilih server target Anda.
Pilih server target Anda.  Pilih opsi Anda. Untuk tujuan kami di mana kedua VM berada di wilayah geografis yang sama, kami akan memilih replikasi yang sinkron. Untuk replikasi jarak yang lebih jauh, Anda akan ingin menggunakan asynchronous dan mengaktifkan beberapa kompresi.
Pilih opsi Anda. Untuk tujuan kami di mana kedua VM berada di wilayah geografis yang sama, kami akan memilih replikasi yang sinkron. Untuk replikasi jarak yang lebih jauh, Anda akan ingin menggunakan asynchronous dan mengaktifkan beberapa kompresi.  Dengan mengklik ya pada pop-up terakhir, Anda akan mendaftarkan Sumber Daya Volume DataKeeper Baru dalam Penyimpanan Tersedia dalam Failover Clustering.
Dengan mengklik ya pada pop-up terakhir, Anda akan mendaftarkan Sumber Daya Volume DataKeeper Baru dalam Penyimpanan Tersedia dalam Failover Clustering. 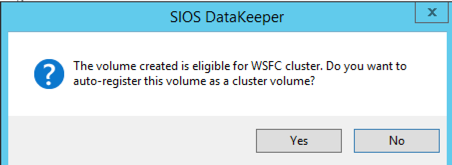 Anda akan melihat Sumber Daya Volume DataKeeper baru dalam Penyimpanan Tersedia.
Anda akan melihat Sumber Daya Volume DataKeeper baru dalam Penyimpanan Tersedia. 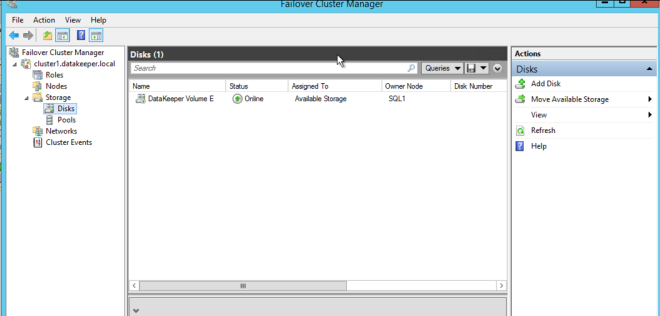
 Setelah Internal Load Balancer (ILB) dibuat, Anda harus mengeditnya. Hal pertama yang akan kita lakukan adalah menambahkan kumpulan backend. Melalui proses ini Anda akan memilih dua node cluster.
Setelah Internal Load Balancer (ILB) dibuat, Anda harus mengeditnya. Hal pertama yang akan kita lakukan adalah menambahkan kumpulan backend. Melalui proses ini Anda akan memilih dua node cluster. 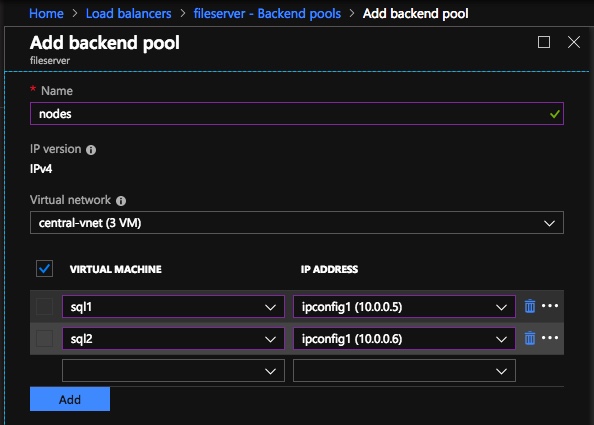 Hal berikutnya yang akan kita lakukan adalah menambahkan Probe. Probe yang kami tambahkan akan memeriksa Port 59999. Probe ini menentukan node mana yang aktif di kluster kami.
Hal berikutnya yang akan kita lakukan adalah menambahkan Probe. Probe yang kami tambahkan akan memeriksa Port 59999. Probe ini menentukan node mana yang aktif di kluster kami. 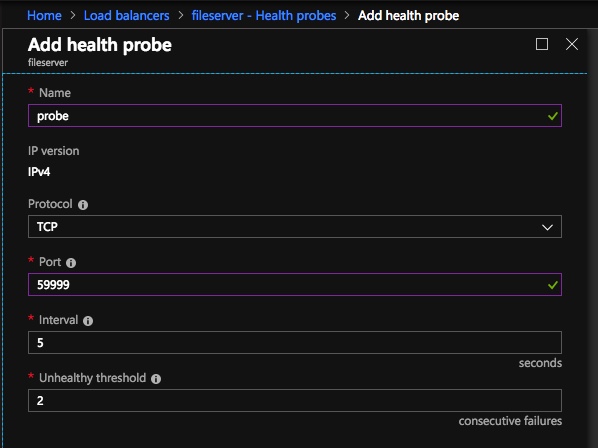 Dan akhirnya, kita membutuhkan aturan load balancing untuk mengarahkan trafik SMB, port TCP 445. Yang penting untuk diperhatikan dalam screenshot di bawah ini adalah Direct Server Return Enabled. Pastikan Anda melakukan perubahan itu.
Dan akhirnya, kita membutuhkan aturan load balancing untuk mengarahkan trafik SMB, port TCP 445. Yang penting untuk diperhatikan dalam screenshot di bawah ini adalah Direct Server Return Enabled. Pastikan Anda melakukan perubahan itu. 


