SQL Server administrator memiliki banyak pilihan untuk menerapkan ketersediaan tinggi (HA) dalam lingkungan VMware. VMware menawarkan vSphere HA. Microsoft menawarkan Windows Server Failover Clustering (WSFC). Dan SQL Server di WSFC memiliki pilihan HA sendiri dengan grup ketersediaan AlwaysOn dan AlwaysOn Failover cluster. Vendor pihak ketiga juga memberikan solusi dibangun untuk pemulihan HA dan bencana, dan ini sering mengintegrasikan dengan solusi lain untuk membuat bahkan lebih banyak pilihan. Sebagai contoh, beberapa solusi memanfaatkan fitur AlwaysOn Failover Cluster yang disertakan dengan SQL Server untuk memberikan kuat HA dan perlindungan data kurang dari biaya AlwaysOn ketersediaan kelompok yang memerlukan lebih mahal Enterprise Edition. Artikel ini menyoroti lima hal setiap SQL Server administrator harus ketahui sebelum merumuskan strategi ketersediaan tinggi untuk aplikasi mission-critical di lingkungan vSphere. Strategi ini cenderung menyerupai multi-situs konfigurasinya ditunjukkan dalam gambar 1, yang tidak mungkin dengan beberapa pilihan HA. 1. Ketersediaan tinggi cluster untuk vSphere memerlukan mentah Disk pemetaan lapisan abstraksi digunakan di server virtual mampu fleksibilitas yang besar, tetapi abstraksi tersebut dapat menyebabkan masalah ketika sebuah mesin virtual (VM) harus antarmuka dengan perangkat fisik. Ini adalah kasus vSphere dengan Storage Area Networks (SANs). Untuk mengaktifkan kompatibilitas dengan SAN tertentu dan fitur berbagi penyimpanan lainnya, seperti I/O Anggar dan Pemesanan SCSI, vSphere menggunakan teknologi yang disebut mentah perangkat pemetaan (RDM) untuk membuat link langsung melalui hypervisor antara VM dan sistem penyimpanan eksternal. Persyaratan untuk menggunakan RDM dengan penyimpanan bersama ada untuk cluster apapun, termasuk SQL Server Failover Cluster. Dalam sebuah cluster tradisional yang dibuat dengan WSFC di vSphere, RDM harus beused untuk menyediakan mesin virtual (VM) akses langsung ke penyimpanan mendasari (SAN). RDM mampu mempertahankan 100 persen kompatibilitas dengan semua perintah SAN, membuat virtualisasi penyimpanan akses mulus untuk sistem operasi dan aplikasi yang merupakan persyaratan penting dari WSFC. RDM dapat dibuat untuk bekerja secara efektif, tetapi mencapai hasil yang diinginkan tidak selalu mudah, dan bahkan mungkin tidak mungkin. Sebagai contoh, RDM tidak mendukung partisi disk, sehingga perlu menggunakan "mentah" atau seluruh LUNs (nomor unit Logis), dan pemetaan tidak tersedia untuk blok terlampir langsung penyimpanan dan divais RAID tertentu. 2. Penggunaan mentah Disk pemetaan berarti mengorbankan populer VMware fitur lain penting aspek menjadi sepenuhnya informasi tentang RDM melibatkan pemahaman rintangan yang dapat membuat untuk menggunakan fitur VMware lainnya, banyak di antaranya populer dengan SQL Server administrator. Ketika rintangan ini dianggap tidak dapat diterima, karena mereka sering, mereka menghilangkan mentah perangkat pemetaan sebagai pilihan untuk mengimplementasikan ketersediaan yang tinggi. Masalah mendasar adalah bagaimana RDM mengganggu VMware fitur yang mempekerjakan file mesin virtual disk (VMDK). Misalnya, RDM mencegah penggunaan VMware snapshot, dan ini pada gilirannya mencegah penggunaan fitur-fitur yang memerlukan snapshot, seperti Virtual konsolidasi backup (VCBs). Mentah Disk pemetaan juga merumitkan data mobilitas, yang menciptakan hambatan untuk menggunakan fitur yang membuat virtualisasi server sangat bermanfaat, termasuk mengubah VMs ke template untuk menyederhanakan penggunaan, dan menggunakan vMotion untuk bermigrasi VMs dinamis antara host. Masalah lain yang potensial untuk transaksi-intensif aplikasi seperti SQL Server adalah ketidakmampuan untuk memanfaatkan Flash Cache dibaca ketika RDM dikonfigurasi. 3. Penyimpanan bersama dapat membuat satu titik dari kegagalan perlunya tradisional berkerumun server untuk memiliki akses langsung ke penyimpanan bersama dapat membuat batasan untuk ketersediaan yang tinggi dan bencana pemulihan ketentuan, dan keterbatasan ini dapat, pada gilirannya, menciptakan sebuah penghalang untuk migrasi aplikasi bisnis penting untuk vSphere. Di tradisional failover cluster, dua atau lebih server fisik (gugus node) terhubung ke sistem penyimpanan bersama. Aplikasi berjalan pada satu server, dan dalam hal kegagalan, pengelompokan perangkat lunak, seperti Windows Server Failover Clustering, bergerak aplikasi untuk sebuah node siaga. Pengelompokan serupa juga dimungkinkan dengan virtualisasi server di lingkungan vSphere, tapi ini membutuhkan teknologi seperti pemetaan Disk mentah sehingga VMs dapat mengakses penyimpanan bersama secara langsung. Apakah server fisik atau virtual, menggunakan penyimpanan bersama dapat membuat titik tunggal kegagalan. SAN dapat memiliki konfigurasi ketersediaan yang tinggi, tentu saja, tapi yang meningkatkan biaya dan kompleksitas yang, dan dapat mempengaruhi kinerja, khususnya untuk transaksi-intensif aplikasi seperti SQL Server. 4. HA vSphere cluster dapat dibangun tanpa mengorbankan VMware fungsi beberapa solusi pihak ketiga dibangun untuk mengatasi keterbatasan yang terkait dengan penyimpanan bersama dan persyaratan untuk menggunakan RDM dengan AlwaysOn Failover cluster SQL Server dan Windows Server Failover cluster. [keterangan id = "" align = "alignleft" width = "31 9"] Gambar 1 – konfigurasi high availability multi-situs melindungi aplikasi dari pemadaman yang mempengaruhi seluruh data center. [/ caption] Yang terbaik dari solusi ini memberikan fleksibilitas lengkap konfigurasi, sehingga memungkinkan untuk menciptakan sebuah cluster SANLess untuk memenuhi berbagai kebutuhan dari sebuah cluster dua-simpul di satu situs, sebuah cluster multinode, untuk sebuah cluster dengan node di lokasi geografis yang berbeda untuk perlindungan bencana seperti yang ditunjukkan dalam gambar 1. Beberapa solusi ini juga membuat mungkin untuk menerapkan LAN/WAN-dioptimalkan, real-time replikasi tingkat blok dalam salah satu cara yang sinkron atau asinkron. Akibatnya, solusi ini mampu menciptakan RAID 1 cermin di seluruh jaringan, secara otomatis mengubah arah replikasi data (sumber dan target) yang diperlukan setelah failover dan failback. Sama pentingnya, sebuah cluster SANLess sering lebih mudah untuk menerapkan dan beroperasi dengan server fisik dan virtual. Misalnya, untuk solusi yang terintegrasi dengan WSFC, administrator dapat mengkonfigurasi cluster ketersediaan tinggi menggunakan fitur akrab dengan cara yang menghindari penggunaan penyimpanan bersama sebagai titik tunggal kegagalan potensial. Setelah dikonfigurasi, kebanyakan solusi kemudian secara otomatis menyinkronkan penyimpanan lokal di dua atau lebih server (di satu atau lebih data Center), membuat mereka tampak WSFC seolah-olah itu adalah perangkat penyimpanan bersama. 5. HA SANLess cluster memberikan Superior kemampuan dan kinerja dalam penambahan untuk menciptakan titik tunggal kegagalan, replikasi data SAN dapat secara signifikan mengurangi throughput kinerja dalam lingkungan VMware. Sangat transaksional aplikasi seperti SQL Server sangat rentan terhadap faktor-faktor ini berkaitan dengan kinerja. [keterangan id = "" align = "alignleft" width
9"] Gambar 1 – konfigurasi high availability multi-situs melindungi aplikasi dari pemadaman yang mempengaruhi seluruh data center. [/ caption] Yang terbaik dari solusi ini memberikan fleksibilitas lengkap konfigurasi, sehingga memungkinkan untuk menciptakan sebuah cluster SANLess untuk memenuhi berbagai kebutuhan dari sebuah cluster dua-simpul di satu situs, sebuah cluster multinode, untuk sebuah cluster dengan node di lokasi geografis yang berbeda untuk perlindungan bencana seperti yang ditunjukkan dalam gambar 1. Beberapa solusi ini juga membuat mungkin untuk menerapkan LAN/WAN-dioptimalkan, real-time replikasi tingkat blok dalam salah satu cara yang sinkron atau asinkron. Akibatnya, solusi ini mampu menciptakan RAID 1 cermin di seluruh jaringan, secara otomatis mengubah arah replikasi data (sumber dan target) yang diperlukan setelah failover dan failback. Sama pentingnya, sebuah cluster SANLess sering lebih mudah untuk menerapkan dan beroperasi dengan server fisik dan virtual. Misalnya, untuk solusi yang terintegrasi dengan WSFC, administrator dapat mengkonfigurasi cluster ketersediaan tinggi menggunakan fitur akrab dengan cara yang menghindari penggunaan penyimpanan bersama sebagai titik tunggal kegagalan potensial. Setelah dikonfigurasi, kebanyakan solusi kemudian secara otomatis menyinkronkan penyimpanan lokal di dua atau lebih server (di satu atau lebih data Center), membuat mereka tampak WSFC seolah-olah itu adalah perangkat penyimpanan bersama. 5. HA SANLess cluster memberikan Superior kemampuan dan kinerja dalam penambahan untuk menciptakan titik tunggal kegagalan, replikasi data SAN dapat secara signifikan mengurangi throughput kinerja dalam lingkungan VMware. Sangat transaksional aplikasi seperti SQL Server sangat rentan terhadap faktor-faktor ini berkaitan dengan kinerja. [keterangan id = "" align = "alignleft" width 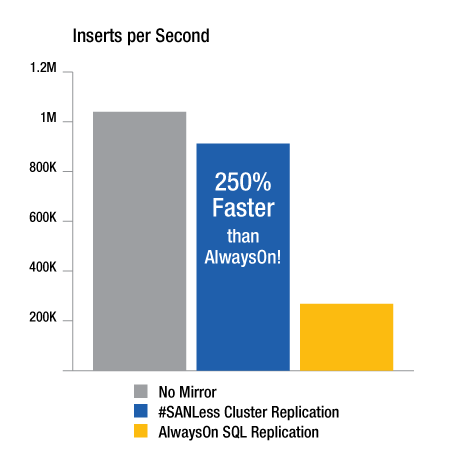 = "362"] Gambar 2 – pengujian SQL Server grup ketersediaan AlwaysOn dan SIOS #SANLess cluster menunjukkan keuntungan throughput mungkin dengan replikasi teknik tujuan dibangun untuk ketersediaan tinggi dan kinerja tinggi. [/ caption] Gambar 2 meringkas hasil tes yang menunjukkan 60-70 persen kinerja penalti yang terkait dengan penggunaan SQL Server AlwaysOn grup ketersediaan melakukan replikasi data. Hasil test ini juga menunjukkan bagaimana tujuan-dibangun ketersediaan tinggi SANLess cluster, yang memanfaatkan penyimpanan lokal, dapat melakukan hampir serta konfigurasi tidak dilindungi dengan replikasi data apapun atau mirroring. Cluster #SANLess yang diuji mampu mencapai kinerja yang mengesankan ini karena driver berada langsung di bawah NTFS. Seperti menulis terjadi pada server utama, pengemudi menulis satu salinan dari blok VMDK lokal dan salinan lain secara bersamaan di seluruh jaringan ke server sekunder yang memiliki VMDK independen sendiri. SANLess kelompok memiliki banyak keuntungan lainnya, juga. Sebagai contoh, mereka yang menggunakan teknologi tingkat blok replikasi yang sepenuhnya terintegrasi dengan WSFC mampu melindungi seluruh SQL Server misalnya, termasuk database, login dan agen pekerjaan-semua dalam mode terpadu. Sebaliknya pendekatan ini dengan AlwaysOn ketersediaan kelompok, yang failover hanya ditetapkan pengguna database, dan memerlukan staf untuk mengelola lain objek data untuk setiap gugus node secara terpisah dan secara manual. ## Tentang penulis Jerry Melnick, COO, SIOS teknologi Corp Jerry Melnick (jmelnick@us.sios.com) bertanggung jawab untuk menentukan strategi perusahaan dan operasi di SIOS teknologi Corp (www.us.sios.com), pembuat perangkat lunak cluster SIOS SAN dan #SANLess (www.clustersyourway.com). Beliau lebih dari 25 tahun pengalaman dalam perusahaan dan industri perangkat lunak tingkat ketersediaan yang tinggi. Ia meraih gelar Bachelor of Science dari Beloit College dengan karya sarjananya di teknik komputer dan ilmu komputer di Universitas Boston.
= "362"] Gambar 2 – pengujian SQL Server grup ketersediaan AlwaysOn dan SIOS #SANLess cluster menunjukkan keuntungan throughput mungkin dengan replikasi teknik tujuan dibangun untuk ketersediaan tinggi dan kinerja tinggi. [/ caption] Gambar 2 meringkas hasil tes yang menunjukkan 60-70 persen kinerja penalti yang terkait dengan penggunaan SQL Server AlwaysOn grup ketersediaan melakukan replikasi data. Hasil test ini juga menunjukkan bagaimana tujuan-dibangun ketersediaan tinggi SANLess cluster, yang memanfaatkan penyimpanan lokal, dapat melakukan hampir serta konfigurasi tidak dilindungi dengan replikasi data apapun atau mirroring. Cluster #SANLess yang diuji mampu mencapai kinerja yang mengesankan ini karena driver berada langsung di bawah NTFS. Seperti menulis terjadi pada server utama, pengemudi menulis satu salinan dari blok VMDK lokal dan salinan lain secara bersamaan di seluruh jaringan ke server sekunder yang memiliki VMDK independen sendiri. SANLess kelompok memiliki banyak keuntungan lainnya, juga. Sebagai contoh, mereka yang menggunakan teknologi tingkat blok replikasi yang sepenuhnya terintegrasi dengan WSFC mampu melindungi seluruh SQL Server misalnya, termasuk database, login dan agen pekerjaan-semua dalam mode terpadu. Sebaliknya pendekatan ini dengan AlwaysOn ketersediaan kelompok, yang failover hanya ditetapkan pengguna database, dan memerlukan staf untuk mengelola lain objek data untuk setiap gugus node secara terpisah dan secara manual. ## Tentang penulis Jerry Melnick, COO, SIOS teknologi Corp Jerry Melnick (jmelnick@us.sios.com) bertanggung jawab untuk menentukan strategi perusahaan dan operasi di SIOS teknologi Corp (www.us.sios.com), pembuat perangkat lunak cluster SIOS SAN dan #SANLess (www.clustersyourway.com). Beliau lebih dari 25 tahun pengalaman dalam perusahaan dan industri perangkat lunak tingkat ketersediaan yang tinggi. Ia meraih gelar Bachelor of Science dari Beloit College dengan karya sarjananya di teknik komputer dan ilmu komputer di Universitas Boston.
17 Februari 2015: Cluster MVP untuk hadir di Silicon Valley SQL Server Group
SIOS bangga mensponsori pertemuan Silicon Valley SQL Server User Group bulan ini. Jika Anda berada di daerah, saya sangat menyarankan memeriksa sesi bulan ini menampilkan kita sendiri Senior teknologi penginjil & Cluster MVP Dave Bermingham: menggelar sangat tersedia SQL Server di Microsoft Azure IaaS.
Daftar sekarang
Lokasi: Microsoft, 1065 La Avenida, bangunan 1, Mountain View, CA (peta) tanggal: 17 Feb 2014 waktu: 6:00 PM – 9:00 PM
Sesi abstrak
Penggelaran sangat tersedia SQL Server di Microsoft Azure IaaS Abstrak: Microsoft Cluster MVP David Bermingham akan membahas pilihan Windows Azure ketersediaan yang tinggi untuk SQL Server. SQL Server AlwaysOn AG dan FCI masih membentuk bantalan dari SQL Server ketersediaan dalam Windows Azure, tetapi ada beberapa hal yang perlu Anda ketahui sebelum Anda melompat dengan kedua kaki. Jika Anda pernah berencana menggelar SQL Server di Windows Azure IaaS, ini adalah pertemuan Anda tidak mau ketinggalan. Tentang Dave Bermingham Dave Bermingham diakui dalam masyarakat teknologi sebagai ahli ketersediaan yang tinggi dan telah dihormati oleh rekan oleh terpilih menjadi Microsoft MVP di Clustering sejak 2010. Dave’s bekerja sebagai Direktur penginjil teknis di SIOS memiliki dia berfokus pada penginjilan Microsoft ketersediaan dan bencana pemulihan solusi tinggi serta memberikan tangan pada dukungan, pelatihan dan profesional layanan untuk cluster implementasi. Dave mengadakan berbagai sertifikasi teknis dan menarik lebih dari dua puluh tahun pengalaman, termasuk bekerja di bidang keuangan, kesehatan dan pendidikan, untuk membantu organisasi desain solusi untuk memenuhi ketersediaan tinggi mereka dan kebutuhan pemulihan bencana. Dave telah baru saja mulai berbicara pada menjalankan server SQL sangat tersedia di Azure awan dan menyebarkan Azure hibrida awan bagi pemulihan bencana. Check out Dave’s blog di www.ClusteringForMereMortals.com dan mengikutinya on twitter (@DaveBerm).
12 Maret 2015: Microsoft MVP menyajikan ketersediaan yang tinggi dan Azure di New York City Metro SQL Server pengguna Group
SIOS bangga mensponsori kelompok pengguna Metro New York City Maret Rapat. Jika Anda berada di daerah, saya sangat menyarankan memeriksa sesi bulan ini “Tinggi ketersediaan dan Azure untuk SQL Server” disajikan oleh Microsoft Cluster MVP dan SIOS’ Senior teknologi penginjil, Dave Bermingham.
Daftar sekarang
Lokasi: Microsoft, 11 Times Square, New York, NY (NE sudut 41st St dan 8 Ave.) Tanggal: Maret 12, 2014 waktu: 6:00 PM
Sesi abstrak
Ketersediaan yang tinggi dan Azure untuk SQL Server datang dan bergabung dengan kami untuk presentasi tentang SQL Server ketersediaan tinggi menggunakan Azure sponser oleh SIOS. Minuman akan disediakan. David Bermingham diakui dalam masyarakat teknologi sebagai ahli ketersediaan yang tinggi dan telah dihormati oleh rekan oleh terpilih menjadi Microsoft MVP di Clustering sejak 2010. Sementara pekerjaan David ini sebagai Direktur penginjil teknis di SIOS memiliki dia berfokus pada penginjilan Microsoft ketersediaan dan bencana pemulihan solusi tinggi serta memberikan tangan pada dukungan, pelatihan dan profesional layanan untuk cluster implementasi. David memegang berbagai sertifikasi teknis dan menarik lebih dari dua puluh tahun pengalaman, termasuk bekerja di bidang keuangan, kesehatan dan pendidikan, untuk membantu organisasi desain solusi untuk memenuhi ketersediaan tinggi mereka dan kebutuhan pemulihan bencana. David baru-baru ini telah mulai berbicara pada menjalankan server SQL sangat tersedia di Azure awan dan menyebarkan Azure hibrida awan bagi pemulihan bencana. Presentasi:
- Memahami konsep Azure kesalahan domain dan domain Update sehubungan dengan SQL Server ketersediaan tinggi di Azure IaaS
- Pelajari bagaimana contoh SQL Server AlwaysOn grup ketersediaan dan Failover Cluster dapat dikerahkan di Azure tingkat ketersediaan
- Pelajari bagaimana Azure Internal beban pengimbang digunakan dalam penyebaran AlwaysOn untuk klien pengalihan
- Pelajari bagaimana konfigurasi awan Azure hibrida dapat digunakan di Azure untuk memberikan tingkat ketersediaan yang tinggi dan pemulihan bencana
Tentang Dave Bermingham Dave Bermingham diakui dalam masyarakat teknologi sebagai ahli ketersediaan yang tinggi dan telah dihormati oleh rekan oleh terpilih menjadi Microsoft MVP di Clustering sejak 2010. Dave’s bekerja sebagai Direktur penginjil teknis di SIOS memiliki dia berfokus pada penginjilan Microsoft ketersediaan dan bencana pemulihan solusi tinggi serta memberikan tangan pada dukungan, pelatihan dan profesional layanan untuk cluster implementasi. Dave mengadakan berbagai sertifikasi teknis dan menarik lebih dari dua puluh tahun pengalaman, termasuk bekerja di bidang keuangan, kesehatan dan pendidikan, untuk membantu organisasi desain solusi untuk memenuhi ketersediaan tinggi mereka dan kebutuhan pemulihan bencana. Dave telah baru saja mulai berbicara pada menjalankan server SQL sangat tersedia di Azure awan dan menyebarkan Azure hibrida awan bagi pemulihan bencana. Check out Dave’s blog di www.ClusteringForMereMortals.com dan mengikutinya on twitter (@DaveBerm).
4-7 Maret 2015: SIOS sponsor dan menghadiri London bit SQL
SIOS bangga menjadi Sponsor Exhibitor di London bit SQL. Ini konferensi SQL Server multi-hari yang membawa pikiran terbaik dan tercerdas di komunitas SQL dari seluruh kata. Bergabung dengan kami di ini salah satu acara semacam pelatihan untuk mempelajari lebih lanjut tentang SAN dan #SANLess pengelompokan solusi kami. Bit SQL ini diadakan di Pusat Pameran ExCel di London dari Maret 4-7, 2015. Lewat konferensi lengkap tersedia dari £599 (GBP). Ada juga paket harian tersedia dan tanpa biaya sesi pada Sabtu 7 Maret. Informasi tambahan harga dapat ditemukan di sini. Kunjungi SQLBits.com untuk mempelajari lebih lanjut atau untuk mendaftar.
Bit SQL XIII
Pameran dan pusat konferensi London, Inggris Raya 4-7 Maret 2014 Ikhtisar exCel | Sesi | Agenda acara
Storage Switzerland: Penyimpanan Q&A: ketersediaan yang tinggi untuk Pusat Data dari semua ukuran
SIOS teknologi dan Storage Switzerland baru saja bergabung untuk sangat menghadiri webinar. Peserta ditanya beberapa pertanyaan yang luar biasa tentang fleksibel HA dan DR untuk virtual server dan lingkungan awan. Bergabung dengan penyimpanan Swiss pendiri dan kepala George Crump pada Webinar adalah Direktur dari bidang teknik Tony Tomarchio dari SIOS.
Pertanyaan 1
"Apa persyaratan konektivitas antara dua geografis tersebar pusat data, seperti bandwidth dan latensi, dalam rangka untuk solusi ketersediaan tinggi Anda bekerja?" Tony: Itu semua bermuara pada beban kerja yang Anda butuhkan untuk melindungi. Kami tidak memiliki persyaratan minimum per se. Itu tergantung pada aktivitas I/O pada sistem Anda, khususnya data tingkat perubahan, yang adalah seberapa cepat disk Anda sedang ditulis. Katakanlah Anda memiliki satu server, yang menulis 3MB/detik ke disk. Perangkat lunak SIOS ingin mengulangi bahwa data secepat Anda menulis ke disk lokal untuk mereplikasi keluar. Anda perlu melihat di server Anda ingin melindungi. Dalam jendela ini sangat mudah untuk dilakukan. Anda dapat menarik PerfMon, lihat di disk Statistik dan biarkan yang menjalankan untuk beberapa periode perwakilan. Yang akan memberitahu Anda persis berapa banyak bandwidth yang Anda butuhkan untuk mendukung real-time replikasi. Sejauh latency aspek dari pertanyaan ini berjalan, kami mendukung replikasi sinkron dan asinkron. Umumnya, Anda akan pergi dengan sinkron replikasi jika Anda memiliki koneksi jaringan berkecepatan tinggi latency rendah. Sinkron memberikan perlindungan maksimum data dan kehilangan data nol karena komit ganda. Menulis tidak dianggap lengkap sampai telah membuatnya menjadi sumber dan target. Tapi Anda harus faktor dalam perjalanan bolak latensi antara sumber target yang akan mempunyai efek pada kinerja menulis Anda. Jika Anda memiliki lebih tinggi latency dan kau lebih kinerja sensitif, Anda mungkin pergi dengan asinkron. Tapi Anda harus memahami bahwa saat terjadi gangguan mungkin ada beberapa data penerbangan yang mungkin tidak membuatnya dari sumber ke target. Jadi mungkin ada beberapa kehilangan data. Itulah klasik trade-off antara sinkron dan asinkron. Untuk meringkas, kita tidak memiliki persyaratan minimum bandwidth dan latensi. Itu benar-benar bermuara pada seberapa sibuk server adalah, seberapa cepat mereka menulis ke disk, apa performa yang adalah toleransi, dan berapa banyak kehilangan data, jika ada, Anda dapat menahan.
Pertanyaan 2
"Bagaimana Apakah cluster SAN-kurang bermanfaat dalam lingkungan VMware?" Tony: Jika Anda menggunakan VMware, it's got fitur built-in seperti VMware HA. Itu adalah solusi parsial dari perspektif HA. Jika Anda melihat VMware HA apa, melindungi Anda terhadap kegagalan tuan rumah. Jika host gagal, itu reboot mesin virtual ke host fisik yang lain di klaster VMware. Jika Anda memiliki masalah dengan jaringan atau aplikasi yang ada di dalam mesin virtual, mesin virtual pada dasarnya adalah sebuah blok kotak dan jenis masalah tidak akan selalu dilindungi. Menambahkan aplikasi tingkat ketersediaan dan kekelompokan di tingkat tamu dapat menyediakan Anda dengan tingkat ketersediaan yang tinggi. Tantangan lain yang saya sebutkan sebelumnya dengan melakukan semua tingkat pengelompokan dalam jenis lingkungan adalah bahwa Anda harus lulus penyimpanan hingga mesin virtual. Biasanya Anda harus mengkonfigurasi perangkat mentah pemetaan (RDM), dan kemudian Anda akan kehilangan hal-hal seperti VMotion. Anda memberikan beberapa fitur virtualisasi untuk HA, tetapi dengan solusi cluster SAN-kurang dari SIOS Anda dapat memiliki keduanya. Kami melakukan segalanya dari dalam tamu. Ada tidak ada perubahan spesifik yang Anda butuhkan untuk membuat di tingkat hypervisor.
Pertanyaan 3
"Konfigurasi penyimpanan apa menyediakan HA terbaik?" George: I'ma SAN guy. Tapi jelas dari perspektif biaya, kemampuan untuk menggunakan drive eksternal harus menarik baik dari perspektif biaya dan keakraban. Apakah sikap Anda itu? Tony: Pasti SANs kuat dan memiliki banyak redundansi, seperti berlebihan controller, disk dan seterusnya. Tetapi pada akhir hari penyimpanan bersama dalam cluster Anda mewakili titik tunggal kegagalan. Sekali lagi, itu tidak mungkin kegagalan perangkat keras. Banyak kali itu adalah konfigurasi atau kesalahan pengguna yang menyebabkan kerugian konektivitas SAN yang bisa turun cluster seluruh Anda. Dengan pergi ke SAN-kurang konfigurasi, Anda menghilangkan penyimpanan sebagai titik tunggal kegagalan dan mencapai tingkat ketersediaan yang tinggi. Jika Anda telah membuat investasi di SAN, saya tidak mengatakan tidak menggunakannya. Anda tentu saja dapat menggunakan penyimpanan yang ada dan sumber daya server yang Anda miliki dalam infrastruktur. Tetapi jika itu adalah cara Anda adalah pengelompokan di masa lalu, mari kita berkata dua server dan SAN, Anda dapat mempertimbangkan menambahkan node ketiga dengan penyimpanan independen itu sendiri. Ini bisa menjadi sebuah SAN berbeda atau itu bisa penyimpanan lokal. Dengan cara itu Anda sekarang punya node lain di klaster sehingga Anda dapat menahan satu kegagalan host lain. Anda juga akan menghilangkan penyimpanan sebagai titik kegagalan, jadi secara teknis Anda melangkah satu takik di rantai ketersediaan. George: saya menulis sebuah makalah tentang ini dan ada bagian yang disebut, "Apa bisa pergi salah dengan Array SAN Anda." Salah satu hal yang menarik yang bisa salah kebanyakan sistem memiliki serangan atau sesuatu terjadi untuk melindunginya dalam kasus kegagalan drive. Tapi satu hal yang saya menemukan yang membutuhkan orang-orang lengah adalah apa kinerja seperti sementara membangun kembali serangan terjadi. Ia biasanya meninggalkan Anda dengan dua pilihan. Anda dapat menolak kecepatan di mana membangun kembali terjadi meninggalkan Anda terkena untuk jangka waktu yang lebih lama, atau Anda dapat mempercepat membangun kembali RAID yang biasanya menyakitkan disk performa i/o. Kedengarannya bagi saya bahwa di lingkungan Anda, saya dapat gagal untuk sistem terpisah berdiri sendiri dan membiarkan rebuild serangan yang terjadi dengan sendirinya pada sistem utama yang terpisah. Yang akan mampu bekerja, bukan? Tony: Ya, Anda bisa pasti melakukannya jika kinerja selama operasi yang menjadi perhatian. Pada dasarnya apa yang terjadi pada tingkat fisik, seperti membangun kembali RAID, transparan untuk perangkat lunak kami. Itulah salah satu alasan mengapa Anda dapat mencampur dan mencocokkan server. Salah satu persyaratan dengan solusi Windows kami adalah huruf drive yang sesuai dan semua volume adalah ukuran yang sama. Apakah itu adalah satu disk atau RAID 0, 1, 5 atau 10, di bawah selimut semua transparan. Jadi ya, apakah itu kekhawatiran, Anda berpotensi failover untuk node lain di klaster dan membiarkan semuanya menjalankan yang sementara Anda PENYERBUAN membangun kembali di sisi lain.
Pertanyaan 4
"Anda bisa menggunakan perangkat lunak Anda untuk apa pun selain SQL?" Tony: Ya, Anda dapat menggunakannya dengan cluster-mampu layanan atau aplikasi. Umumnya kita melindungi SQL. Kami memiliki solusi untuk Linux yang mana kami melakukan banyak SAP, Oracle dan NFS jenis cluster. Itu adalah seluruh peta. Kami juga dapat melindungi aplikasi kustom. Itu adalah salah satu manfaat dari memiliki sebuah blok replikasi tingkat teknologi. Ini adalah server, Penyimpanan, dan bahkan aplikasi agnostik. Anda hanya memberitahu kami partisi atau volume yang ingin meniru dan data apapun yang kebetulan tinggal di sana dan kami akan melindungi. Dari hal itu, ini dapat digunakan untuk lebih dari sekedar SQL.
Pertanyaan 5
"Bagaimana kinerja aplikasi dipengaruhi oleh menjalankan perangkat lunak SAN-kurang?" Tony: Ini datang kembali ke mode replikasi. Kami mendukung replikasi sinkron dan asinkron. Dengan replikasi asinkron, Anda tidak akan melihat kinerja dampak apapun. Jika sinkron, maka Anda hanya akan melihat dampak pada menulis ke disk karena komit ganda. Dibaca tidak terpengaruh. Jika Anda pergi dengan sinkron replikasi, Anda pasti ingin memiliki koneksi jaringan latency rendah untuk meminimalkan biaya overhead replikasi sinkron yang memaksakan pada menulis.
- « Previous Page
- 1
- …
- 43
- 44
- 45
- 46
- 47
- …
- 76
- Next Page »