
Mengukur dan Meningkatkan Performa Throughput Tulis di GCP Menggunakan SIOS DataKeeper untuk Windows
Latar belakang
Postingan ini berfungsi untuk mendokumentasikan temuan saya di GCP terkait performa penulisan ke disk yang direplikasi ke GCP. Tapi pertama-tama, beberapa informasi latar belakang. Seorang pelanggan menyatakan keprihatinannya bahwa DataKeeper menambahkan sejumlah besar overhead ke kinerja tulis mereka saat menguji dengan cermin sinkron antara Google Zones di wilayah yang sama. Tes asli yang mereka lakukan adalah dengan file bitmap pada drive C, yang merupakan SSD persisten. Dalam konfigurasi ini mereka hanya mendorong sekitar 70 MBps. Mereka mencoba merelokasi bitmap ke disk GCP ekstrem, tetapi performanya tidak meningkat.
Memindahkan Bitmap ke SSD Lokal
Saya menyarankan agar mereka memindahkan bitmap ke SSD lokal, tetapi mereka ragu-ragu karena mereka percaya disk ekstrim yang mereka gunakan untuk bitmap memiliki latensi dan throughput yang sama baiknya atau lebih baik daripada SSD lokal, jadi mereka ragu itu akan membuat perbedaan. Selain itu, menambahkan SSD lokal bukanlah tugas sepele karena hanya dapat ditambahkan saat VM awalnya disediakan.
Memilih Jenis Instance
Saat saya mulai menyelesaikan tugas saya, hal pertama yang saya temukan adalah tidak semua jenis instans mendukung SSD lokal. Misalnya, E2-Standard-8 tidak mendukung SSD lokal. Untuk pengujian pertama saya, saya memilih jenis instans C2-Standar-8, yang dianggap “dioptimalkan untuk komputasi”. Saya memasang SSD persisten 500 GB dan mulai menjalankan beberapa tes kinerja tulis dan dengan cepat menemukan bahwa saya hanya bisa membuat disk menulis sekitar 140MBps daripada kecepatan maksimal 240MBps. Pelanggan mengkonfirmasi bahwa mereka melihat hal yang sama. Itu membingungkan, tetapi kami memutuskan untuk melanjutkan dan mencoba jenis instance yang berbeda.
Jenis instans kedua yang kami pilih adalah N2-Standar-8. Dengan jenis instans ini, kami dapat mendorong disk ke kecepatan throughput maksimum 240 MBps saat tidak mereplikasi disk. Saya memindahkan bitmap ke SSD lokal yang telah saya sediakan dan mengulangi tes yang sama pada mirror sinkron (DataKeeper v8.8.2) dan mendapatkan hasil yang ditunjukkan di bawah ini.
Hasil
Parameter uji diskspd diskspd.exe -c96G -d10 -r -w100 -t8 -o3 -b64K -Sh -LD:data.dat diskspd.exe -c96G -d10 -r -w100 -t8 -o3 -b8K -Sh -LD:data .dat diskspd.exe -c96G -d10 -r -w100 -t8 -o3 -b4K -Sh -LD:data.dat
MBps
Data
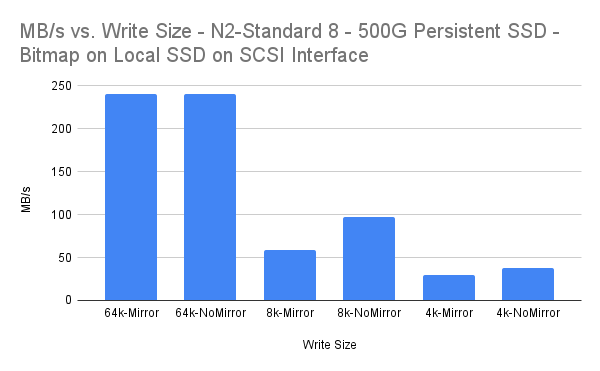
| Tulis Ukuran | MB/dtk | Persen MBps Overhead |
| 64k-Cermin | 240.01 | 0,00% |
| 64k-Tanpa Cermin | 240.02 | |
| 8k-Cermin | 58.87 | 39,18% |
| 8k-NoCermin | 96.8 | |
| 4k-Cermin | 29.34 | 21,84% |
| 4k-NoCermin | 37.54 |
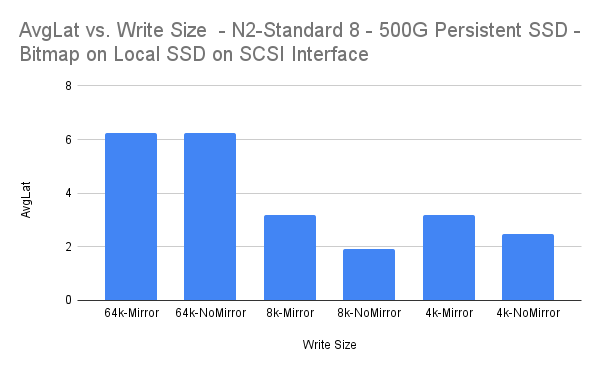
| Tulis Ukuran | Rata-RataLat | Overhead Rata-rata |
| 64k-Cermin | 6.247 | -0,02% |
| 64k-Tanpa Cermin | 6.248 | |
| 8k-Cermin | 3.183 | 39,21% |
| 8k-NoCermin | 1.935 | |
| 4k-Cermin | 3.194 | 21,88% |
| 4k-NoCermin | 2.495 |
Kesimpulan
Ukuran tulis 64k dan 4k semuanya dikenakan overhead yang dapat dianggap sebagai "dapat diterima" untuk replikasi sinkron. Ukuran tulis 8k tampaknya menimbulkan jumlah overhead yang lebih signifikan, meskipun latensi rata-rata 3,183 ms masih cukup rendah.
-Dave Bermingham, Direktur, Keberhasilan Pelanggan Direproduksi dengan izin dari SIOS




