Lembar Fakta: Ketersediaan Tinggi BMS
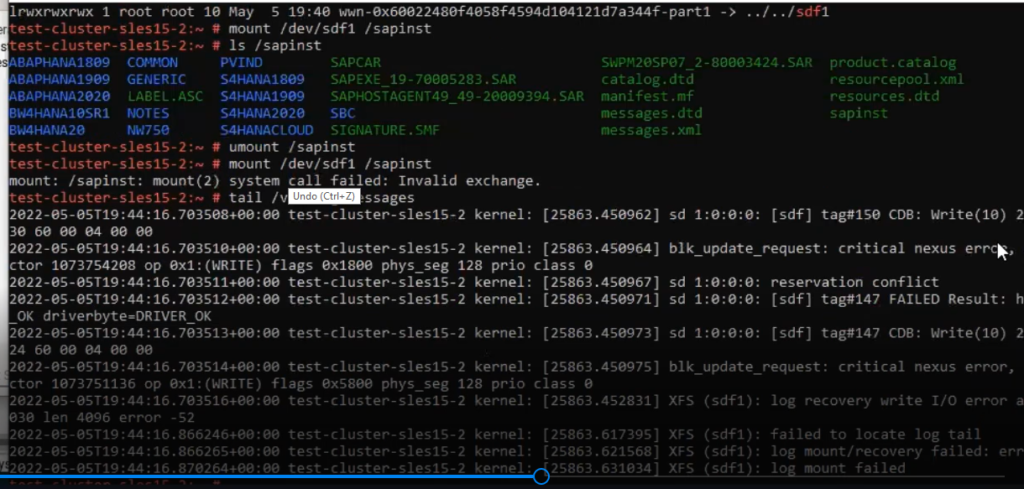
Teknologi SIOS membuat pengelompokan ketersediaan tinggi dan perangkat lunak replikasi yang memastikan aplikasi penting, database, dan sistem BMS, secara otomatis pulih dari kegagalan infrastruktur, jaringan, dan aplikasi – menjaga data Anda tetap terlindungi, aplikasi online, memenuhi persyaratan peraturan, dan pengguna tetap produktif.
Temui SLA Ketersediaan dan RTO/RPO dengan Mudah
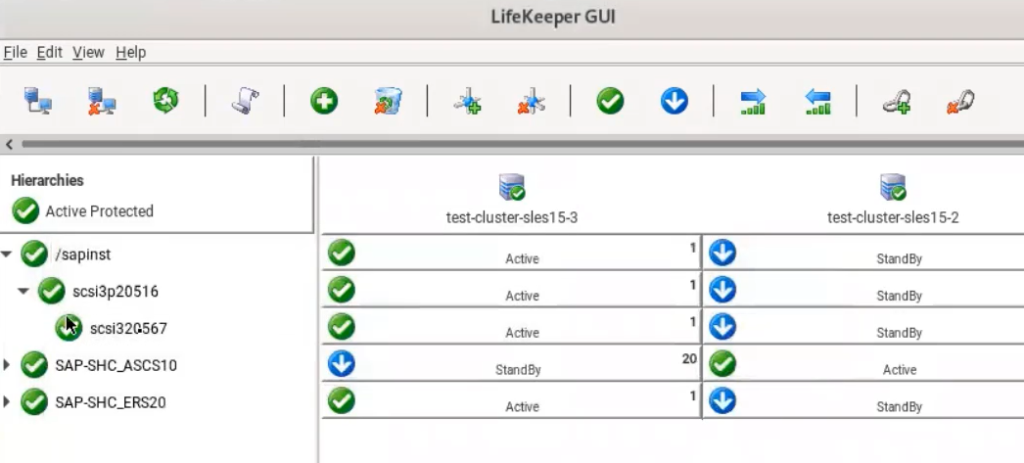
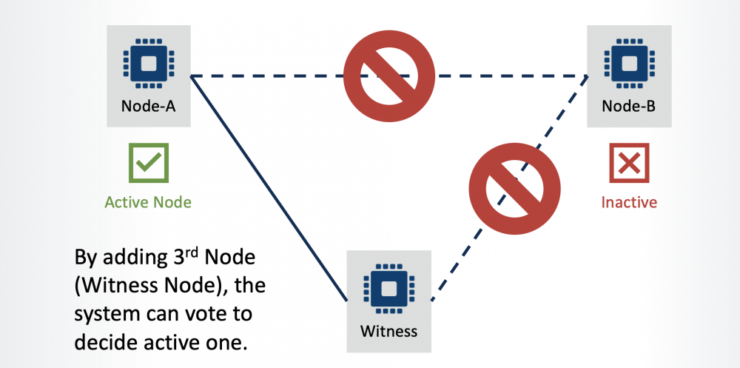
SIOS memberi Anda fleksibilitas untuk membangun klaster SAN dan SANless untuk lingkungan Windows atau Linux di server fisik, server virtual, dan di cloud. Anda dapat menggunakan perangkat lunak SIOS untuk mencapai ketersediaan tinggi atau toleransi bencana. Pindahkan Windows Server Failover Clustering dengan mudah ke cloud tanpa gangguan atau dengan mudah membangun lingkungan clustering Linux dengan kecerdasan khusus aplikasi bawaan. Di cloud, Anda dapat mengonfigurasi cluster di seluruh zona atau wilayah ketersediaan untuk perlindungan HA/DR maksimum atau membuat konfigurasi cloud hybrid atau multicloud untuk memenuhi ketersediaan SLA dan RTO/RPO dengan mudah.
Produk SIOS Ketersediaan Tinggi
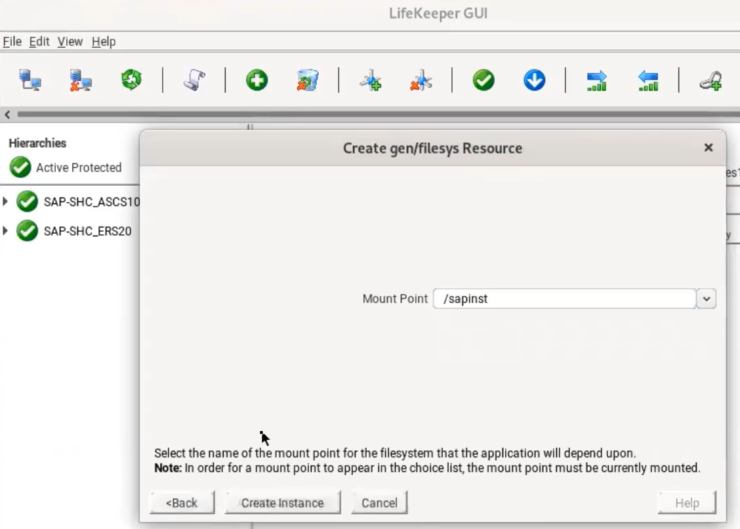
Penjaga Data SIOSTambahkan SIOS DataKeeper ke lingkungan Windows Server Failover Clustering untuk membuat cluster SANless di mana cluster penyimpanan bersama tradisional tidak mungkin atau tidak praktis, seperti lingkungan cloud dan hybrid cloud. Replikasi berbasis host yang cepat dan efisien menyinkronkan penyimpanan lokal di semua node cluster untuk fleksibilitas konfigurasi maksimum. Atau, tambahkan replikasi ke klaster Windows berbasis SAN yang ada untuk DR. Gunakan perangkat lunak SIOS DataKeeper Cluster Edition untuk melindungi aplikasi Windows dan sistem BMS yang sangat penting bagi bisnis Anda dan database yang dijalankannya, termasuk Microsoft SQL Server, Oracle, dalam lingkungan fisik, virtual, atau cloud.
|
Suite Perlindungan SIOSSuite Perlindungan SIOS untuk Linux memungkinkan Anda menjalankan aplikasi EHR penting bisnis Anda di tempat atau di lingkungan cloud yang fleksibel dan dapat diskalakan, seperti Amazon Web Services (AWS) dan Microsoft Azure tanpa mengorbankan kinerja atau perlindungan HA/DR. SIOS mengelompokkan failover unik di seluruh wilayah cloud atau zona ketersediaan untuk perlindungan HA yang sebenarnya.
|
HA/DR untuk Lembar Fakta Sistem Manajemen Gedung
Sistem BMS Dilindungi
|
Lingkungan & Platform Dilindungi
|
Database dan ERP DilindungiSQL Server, SAP, SAP S/4HANA, Oracle, SharePoint Belajarlah lagi
|
Studi Kasus KesehatanPusat Perawatan Kanker Rumah Sakit Chris O'Brien, Rumah Sakit Allyn, Rumah Sakit Carroll, Penyedia Layanan Kesehatan Terkemuka. Belajarlah lagi |
- Dapatkan uji coba gratis SIOS High Availability dan Disaster Recovery Clustering Software
- Pelajari lebih lanjut tentang SIOS DataKeeper
- Unduh Lembar Fakta PDF
Direproduksi dengan izin dari SIOS