Date: Januari 17, 2023

Memahami Kompleksitas Ketersediaan Tinggi untuk Aplikasi Penting Bisnis
Meminimalkan downtime dalam sistem, database, dan aplikasi adalah kunci untuk memaksimalkan produktivitas. Organisasi modern bergantung pada sistem, database, dan aplikasi bisnis penting—seperti perencanaan sumber daya perusahaan (ERP), manajemen hubungan pelanggan (CRM), e-commerce, sistem keuangan, dan manajemen rantai pasokan—untuk beroperasi secara efisien dan memberikan pengalaman pelanggan yang unggul . Ketika sistem, database, atau aplikasi gagal, perlindungan ketersediaan tinggi memulihkan operasi agar bisnis tetap aktif dan berjalan.
Apa itu Ketersediaan Tinggi?
Ketersediaan tinggi adalah atribut dari sistem, database, atau aplikasi yang dirancang untuk beroperasi terus menerus dan andal untuk waktu yang lama. Sasaran ketersediaan tinggi adalah untuk mengurangi atau menghilangkan downtime terencana dan tidak terencana untuk aplikasi kritis dengan memasukkan komponen redundan dan teknologi lainnya untuk mengatasi satu titik kegagalan dalam sistem, database, atau aplikasi.
Secara sederhana dinyatakan, ketersediaan tinggi memastikan bahwa sistem, database, atau aplikasi Anda beroperasi saat dan seperti yang diharapkan: "kapan" mengacu pada persentase waktu sistem, database, atau aplikasi harus aktif dan berjalan seperti yang diharapkan—artinya aplikasi beroperasi dengan cara yang diharapkan dan dipenuhi pengguna kebutuhan mereka secara tepat waktu.
Model IDC
Perjanjian tingkat layanan (SLA) untuk ketersediaan tinggi membantu memastikan bahwa komponen utama infrastruktur TI beroperasi dan tersedia selama jam kerja. IDC telah membuat model SLA untuk ketersediaan tinggi yang menetapkan lima level dengan persyaratan waktu aktif berikut: • AL4 (Ketersediaan Berkelanjutan—Toleransi Kesalahan Sistem): Tidak ada gangguan pengguna dan total maksimum tidak lebih dari 5 menit dan 15 detik waktu henti terencana dan tidak terencana per tahun (99,999% atau ketersediaan "lima sembilan").
• AL3 (Ketersediaan Tinggi—Pengelompokan Tradisional): Gangguan pengguna minimal dan total maksimum tidak lebih dari 52 menit dan 35 detik waktu henti terencana dan tidak terencana per tahun (99,99% atau ketersediaan "empat-sembilan").
• AL2 (Pemulihan—Replikasi dan Pencadangan Data): Beberapa gangguan pengguna dan total maksimum tidak lebih dari 8 jam, 45 menit, dan 56 detik waktu henti terencana dan tidak terencana per tahun (99,9% atau ketersediaan "tiga sembilan").
• AL1 (Keandalan—Komponen yang Dapat Ditukar): Semua layanan berhenti dan total 87 jam, 39 menit, dan 29 detik waktu henti terencana dan tidak terencana per tahun (99% atau ketersediaan "dua-sembilan").
• AL0 (Server Tidak Terproteksi): Semua layanan berhenti, dan tidak ada SLA uptime yang ditentukan.
Persyaratan ketersediaan tinggi Anda bergantung pada kekritisan keseluruhan sistem, aplikasi, dan berbagai faktor lainnya, termasuk: • Seberapa penting aplikasi bagi bisnis • Apakah pelanggan menyadari adanya dampak • Seberapa sering aplikasi dijalankan • Berapa banyak pengguna yang terpengaruh oleh downtime • Seberapa cepat database atau aplikasi harus dialihkan ke sistem redundan untuk menghindari gangguan • Berapa banyak data kerugian dapat ditolerir Ketersediaan Five Nines biasanya dicadangkan untuk aplikasi yang memerlukan operasi "stateful" yang berkelanjutan. Untuk aplikasi bisnis penting, ketersediaan empat-sembilan adalah standar. Sistem dan aplikasi non-kritis, Anda mungkin hanya memerlukan ketersediaan dua-sembilan. Saat menentukan waktu henti yang dapat diterima, penting untuk mempertimbangkan: • Waktu henti yang tidak direncanakan (yaitu, kegagalan perangkat keras atau perangkat lunak) • Waktu henti yang direncanakan untuk pemeliharaan rutin perangkat keras dan perangkat lunak • Waktu aktif di tingkat aplikasi dan basis data Berbagai solusi ketersediaan tinggi dapat membantu bisnis mencapai tujuan SLA mereka untuk sistem, database, dan aplikasi yang berbeda. Meskipun ketersediaan berkelanjutan (AL4) mungkin tampak seperti tujuan yang paling tepat untuk penyebaran kritis bisnis, penting untuk menemukan keseimbangan yang tepat antara biaya dan ketersediaan. Ketersediaan berkelanjutan juga dapat berdampak negatif pada waktu henti yang diperlukan untuk pemeliharaan terencana karena sistem umumnya harus dibuat offline saat pembaruan aplikasi atau OS diterapkan, versus ketersediaan tinggi, yang biasanya memungkinkan pembaruan bergulir.
Metrik Ketersediaan Tinggi: RTO vs. RPO
Selain waktu aktif dan ketersediaan, Tujuan Waktu Pemulihan (RTO) dan Tujuan Titik Pemulihan (RPO) adalah metrik penting yang digunakan untuk menilai ketersediaan tinggi (serta pemulihan bencana) dalam sistem, database, atau aplikasi.
RTO adalah durasi maksimum yang dapat ditoleransi dari pemadaman apa pun. Aplikasi pemrosesan transaksi online umumnya memiliki RTO terendah, dan aplikasi yang penting bagi bisnis seringkali memiliki RTO hanya beberapa detik.
RPO adalah jumlah maksimum kehilangan data yang dapat ditoleransi ketika terjadi kegagalan. Untuk pemulihan bencana, RPO tipikal untuk aplikasi dan data terkaitnya mungkin 24 jam. Pencadangan setiap malam memastikan bahwa setiap perubahan pada data selama 24 jam terakhir dapat dipulihkan jika terjadi bencana. Namun, untuk aplikasi dan data dengan ketersediaan tinggi, RPO seringkali nol. Artinya, tidak boleh ada kehilangan data di bawah skenario kegagalan apa pun.
Pengelompokan Tradisional
Kluster ketersediaan tinggi adalah grup node server (dan komponen lainnya) yang mendukung aplikasi penting bisnis yang memerlukan waktu henti minimal.Perangkat lunak pengelompokan memungkinkan Anda mengonfigurasi server Anda sebagai kluster sehingga beberapa server dapat bekerja bersama untuk menyediakan ketersediaan tinggi dan mencegah kehilangan data. Organisasi TI mengandalkan pengelompokan ketersediaan tinggi untuk menghilangkan satu titik kegagalan dan meminimalkan risiko downtime dan kehilangan data.
Kluster ketersediaan tinggi tradisional lokal adalah grup yang terdiri dari dua atau lebih node server yang terhubung ke penyimpanan bersama (biasanya, jaringan area penyimpanan, atau SAN) yang dikonfigurasi dengan sistem operasi, database, dan aplikasi yang sama (lihat Gambar 1 ).
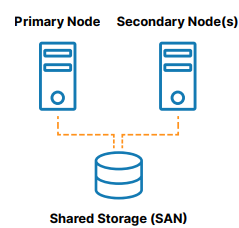
Salah satu node ditetapkan sebagai node primer (atau aktif) dan node lainnya ditetapkan sebagai node sekunder (atau standby). Jika simpul utama gagal, pengelompokan memungkinkan pengoperasian sistem, database, atau aplikasi untuk secara otomatis mengalihkan ke satu atau lebih simpul sekunder dan terus beroperasi seperti biasa dengan gangguan minimal. Karena node sekunder terhubung ke penyimpanan yang sama, operasi berlanjut tanpa kehilangan data. Keuntungan dari arsitektur cluster ini adalah berkurangnya downtime, penghapusan kehilangan data, dan integritas data yang terlindungi.
Namun, ada banyak skenario di mana penyimpanan bersama tidak diinginkan. Kegagalan dalam penyimpanan bersama akan membuat semua kluster offline, menjadikannya risiko satu titik kegagalan (SPoF). Penyimpanan SAN juga mahal dan rumit untuk dimiliki dan dikelola. Terakhir, menggunakan penyimpanan bersama di cloud dapat menambah biaya dan kompleksitas yang signifikan dan tidak perlu. Beberapa cloud tidak menawarkan opsi penyimpanan bersama sama sekali.
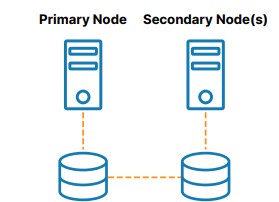
Seperti yang ditunjukkan di Gambar 2, Kluster SANless atau "shared nothing" adalah alternatif terbaik untuk penyimpanan bersama. Dalam konfigurasi ini, setiap node cluster memiliki penyimpanan lokalnya sendiri. Replikasi tingkat blok berbasis host yang efisien digunakan untuk menyinkronkan penyimpanan pada node cluster, menjaganya tetap identik. Jika terjadi failover, node sekunder mengakses salinan identik penyimpanan yang digunakan oleh node utama. Manfaat arsitektur cluster ini adalah penghapusan SPoF, penghapusan biaya dan kompleksitas SAN, kemudahan penggunaan dan penghematan biaya di cloud, pengurangan waktu henti, dan mitigasi kehilangan data.
Prinsip desain
Kluster ketersediaan tinggi paling canggih menggabungkan prinsip desain berikut: • Mereka secara otomatis dan cepat melakukan failover ke sistem redundan saat komponen aktif gagal • Mereka memelihara praktik terbaik khusus aplikasi selama dan setelah kegagalan • Mereka memberikan kemampuan untuk beralih dan beralih kembali secara manual untuk mengaktifkan pengujian yang efisien dan pemeliharaan “rolling” dengan minimal downtime terencana • Mereka dapat secara otomatis mendeteksi kegagalan dalam jaringan, penyimpanan, OS, perangkat keras, atau aplikasi • Mereka mencegah kehilangan data jika terjadi kegagalan sistem • Mereka melakukan failover di node yang terpisah secara geografis untuk pemulihan bencana
Clustering Ketersediaan Tinggi
Berbagai solusi perangkat lunak pengelompokan tersedia untuk Windows, distribusi Linux, dan berbagai hypervisor (solusi mesin virtual). Satu grup hanya mendukung satu sistem operasi, seperti berikut ini: • Kluster Failover Windows Server (WSFC): Menyediakan ketersediaan tinggi dan pemulihan bencana untuk aplikasi yang dihosting seperti Microsoft SQL Server dan Microsoft Exchange • Ekstensi Ketersediaan Tinggi SUSE Linux Enterprise (HAE): Mendukung pengelompokan server Linux fisik dan virtual dengan pengelompokan berbasis kebijakan dan replikasi data berkelanjutan • Alat Pacu Jantung Topi Merah (Pacu Jantung): Membuat klaster situs tunggal untuk kinerja, ketersediaan tinggi, penyeimbangan beban, dan skalabilitas Tidak ada solusi yang tercantum di sini yang dapat melindungi SAP yang berjalan di sistem operasi Oracle Linux misalnya. Dengan demikian, setiap solusi membatasi fleksibilitas dan opsi penerapan Anda. Lebih maju solusi ketersediaan tinggi , seperti SIOS Protection Suite untuk Linux, menyediakan perlindungan sadar aplikasi di distribusi Linux utama, termasuk Oracle Linux, Red Hat, dan SUSE.
Selain itu, setiap aplikasi, database, dan sistem ERP memiliki kebutuhannya sendiri untuk konfigurasi dan pengelolaan yang berkelanjutan. Untuk memenuhi persyaratan ini, HAE dan Pacemaker biasanya memerlukan keterampilan teknis tingkat tinggi, dan pembuatan skrip manual yang rumit, yang menimbulkan kemungkinan kesalahan manusia dan kegagalan yang tidak dapat diandalkan.
Beberapa contoh aplikasi bisnis penting, database, dan sistem ERP yang umumnya dilindungi dengan failover clustering termasuk SAP S/4HANA, SQL Server, dan aplikasi serta database lainnya.
SAP S/4HANA Beberapa vendor Linux menawarkan ekstensi open source high availability untuk SAP dalam langganan “Enterprise for SAP” mereka. Lingkungan SAP S/4HANA terdiri dari beberapa layanan seperti ABAP SAP Central Service (ASCS), Evaluated Receipt Settlement (ERS), dan komponen SAP lainnya, yang perlu dipertahankan di lokasi yang tepat dan dimulai dengan urutan yang benar. Dalam produk pengelompokan sumber terbuka, seperti SUSE HAE dan Red Hat Pacemaker, mengonfigurasi dan mengelola kluster secara manual di lingkungan yang kompleks ini dapat memakan waktu dan rentan terhadap kesalahan manusia yang meningkatkan risiko waktu henti yang sangat besar dan kehilangan data.
Keahlian mendalam khusus dalam aplikasi dan database juga diperlukan untuk membuat solusi ketersediaan tinggi yang menyadari aplikasi. Sebaliknya, Suite Perlindungan SIOS untuk Linux termasuk kit pemulihan aplikasi untuk SAP dan HANA yang memastikan kegagalan mempertahankan praktik terbaik aplikasi.
SAP juga menawarkan Replikasi Sistem HANA, fitur yang disertakan dengan perangkat lunak HANA. Ini memberikan sinkronisasi berkelanjutan dari database SAP HANA ke lokasi sekunder di pusat data yang sama, di situs jarak jauh, atau di cloud. Data direplikasi ke situs sekunder dan dimuat ke dalam memori. Saat terjadi kegagalan, situs sekunder mengambil alih tanpa memulai ulang database, yang membantu mengurangi RTO. Namun, failback ke node utama harus dipicu secara manual. HSR perlu dipasangkan dengan perangkat lunak pengelompokan yang sadar aplikasi seperti SIOS Protection Suite yang dapat mendeteksi kegagalan dan mengatur kegagalan jika perlu.
Server SQL
Banyak perusahaan mengandalkan SQL Server sebagai database back-end untuk aplikasi utama yang mendukung fungsi bisnis penting. Microsoft WSFC umumnya digunakan untuk mendukung Always On Availability Groups (AG) dan SQL Server Failover Cluster Instances (FCI) untuk aplikasi SQL Server.
Namun, WSFC dengan AG memerlukan lisensi SQL Server Enterprise Edition yang mahal. Selain itu, Dengan FCI, seluruh instans dialihkan ke node siaga. Dengan AG hanya database dalam grup yang dilindungi.
Menggunakan Penjaga Data SIOS dengan WSFC memungkinkan Anda memberikan perlindungan ketersediaan tinggi tingkat lanjut untuk SQL Server menggunakan lisensi Edisi Standar yang hemat biaya.
Aplikasi dan Database Lainnya
Perangkat lunak SIOS dapat digunakan untuk melindungi berbagai aplikasi penting bisnis, database, dan ERP, termasuk Oracle, MaxDB, MySQL, PostgreSQL, dan DB2. Perangkat lunak SIOS memungkinkan pengelompokan dan pemulihan bencana.
Di blog kami berikutnya, kami akan melihat kasus penggunaan industri tertentu untuk membantu Anda memahami bagaimana berbagai bisnis mencapai ketersediaan tinggi untuk aplikasi penting mereka.
Direproduksi dengan izin dari SIOS