Date: Januari 29, 2022

Meminimalkan Waktu Henti dengan Ketersediaan Tinggi
Waktu henti menjadi lebih mahal daripada sebelumnya untuk bisnis modern. Survei Biaya Henti Per Jam ITIC 2021 menemukan bahwa di 91% organisasi, satu jam waktu henti dalam sistem, basis data, atau aplikasi yang sangat penting bagi bisnis menghabiskan biaya rata-rata lebih dari $300.000, dan untuk 18% perusahaan besar, biaya satu jam waktu henti melebihi $5 juta.
Ketersediaan tinggi (HA) adalah atribut dari sistem, database, atau aplikasi yang dirancang untuk beroperasi terus menerus dan andal untuk waktu yang lama. Tujuan HA adalah untuk mengurangi atau menghilangkan waktu henti yang tidak direncanakan untuk aplikasi kritis. Hal ini dicapai dengan menghilangkan satu titik kegagalan dengan menggabungkan komponen yang berlebihan dan teknologi lainnya dalam desain sistem, database, atau aplikasi yang penting bagi bisnis.
Metrik SLA dan HA
Perjanjian tingkat layanan (SLA) digunakan oleh penyedia layanan untuk menjamin bahwa sistem, basis data, atau aplikasi penting bisnis pelanggan aktif dan berjalan saat bisnis membutuhkannya.
IDC telah membuat model SLA yang mendefinisikan persyaratan uptime di lima level sebagai berikut:
- AL4 (Ketersediaan Berkelanjutan – Toleransi Kesalahan Sistem): Tidak lebih dari 5 menit dan 15 detik waktu henti yang direncanakan dan tidak direncanakan per tahun (ketersediaan 99,999% atau "lima-sembilan")
- AL3 (Ketersediaan Tinggi – Pengelompokan Tradisional): Tidak lebih dari 52 menit dan 35 detik waktu henti yang direncanakan dan tidak direncanakan per tahun (ketersediaan 99,99% atau "empat-sembilan")
- AL2 (Pemulihan – Replikasi dan Cadangan Data): Tidak lebih dari 8 jam, 45 menit, dan 56 detik waktu henti yang direncanakan dan tidak direncanakan per tahun (99,9% atau ketersediaan "tiga-sembilan")
- AL1 (Keandalan – Komponen Hot Swappable): Tidak lebih dari 87 jam, 39 menit, dan 29 detik waktu henti yang direncanakan dan tidak direncanakan per tahun (ketersediaan 99% atau "dua-sembilan")
- AL0 (Server Tidak Terlindungi): Tidak ada ketersediaan atau jaminan uptime
Menurut ITIC, 89% organisasi yang disurvei sekarang memerlukan ketersediaan "empat-sembilan" untuk sistem, database, dan aplikasi penting bisnis mereka, dan 35% dari organisasi-organisasi tersebut berupaya lebih lanjut untuk mencapai ketersediaan "lima-sembilan".
Selain waktu aktif dan ketersediaan, dua metrik HA penting lainnya adalah Tujuan Waktu Pemulihan (RTO) dan Tujuan Titik Pemulihan (RPO). RTO adalah durasi maksimum yang dapat ditoleransi dari setiap pemadaman dan RPO adalah jumlah maksimum kehilangan data yang dapat ditoleransi ketika terjadi kegagalan. Tidak seperti metrik RTO dan RPO untuk pemulihan bencana yang biasanya ditentukan dalam jam dan hari, metrik RTO dan RPO untuk sistem, database, dan aplikasi penting bisnis seringkali hanya beberapa detik (RTO) dan nol (RPO).
Pengelompokan HA
Pengelompokan HA biasanya terdiri dari node server, penyimpanan, dan perangkat lunak pengelompokan.
Pengelompokan Tradisional
Cluster HA lokal tradisional adalah grup dari dua atau lebih node server yang terhubung ke penyimpanan bersama (biasanya, jaringan area penyimpanan, atau SAN) yang dikonfigurasi dengan sistem operasi, database, dan aplikasi yang sama (lihat Gambar 1 ).
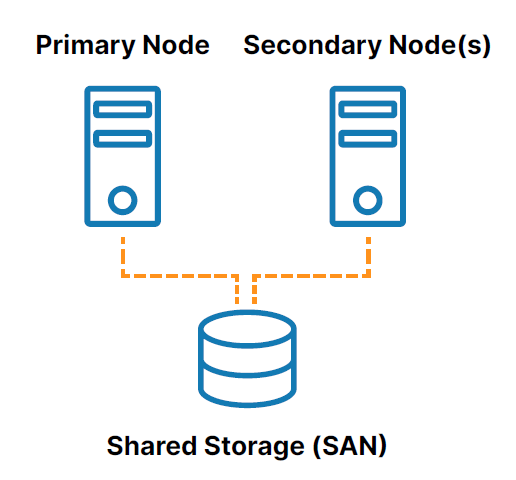
Salah satu node ditunjuk sebagai node primer (atau aktif) dan node lainnya ditunjuk sebagai node sekunder (atau standby). Jika node utama gagal, pengelompokan memungkinkan sistem, database, atau aplikasi untuk secara otomatis gagal ke satu atau lebih node sekunder dan terus beroperasi dengan gangguan minimal. Karena node sekunder terhubung ke penyimpanan yang sama, operasi berlanjut tanpa kehilangan data.
Namun, penggunaan penyimpanan bersama dalam model pengelompokan tradisional menciptakan beberapa tantangan, termasuk:
- Penyimpanan bersama itu sendiri adalah satu titik kegagalan yang berpotensi membuat semua node yang terhubung di cluster offline.
- Penyimpanan SAN juga bisa mahal dan rumit untuk dimiliki dan dikelola.
- Penyimpanan bersama di cloud dapat menambah biaya dan kerumitan yang signifikan dan tidak perlu, dan beberapa penyedia cloud bahkan tidak menawarkan opsi penyimpanan bersama.
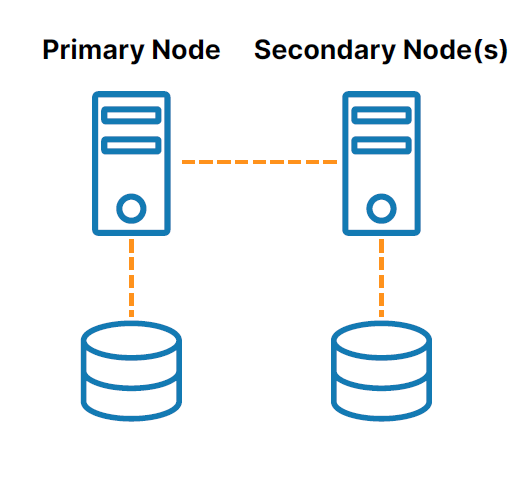
Pengelompokan Tanpa SAN
Cluster SANless atau "tidak berbagi apa-apa" (lihat Gambar 2 ) mengatasi tantangan yang terkait dengan penyimpanan bersama. Dalam konfigurasi ini, setiap node cluster memiliki penyimpanan lokalnya sendiri. Replikasi tingkat blok berbasis host yang efisien digunakan untuk menyinkronkan penyimpanan pada node cluster, menjaganya agar tetap identik. Jika terjadi failover, node sekunder mengakses salinan identik dari penyimpanan yang digunakan oleh node utama.
Perangkat Lunak Pengelompokan
Perangkat lunak pengelompokan memungkinkan Anda mengonfigurasi server sebagai kluster sehingga beberapa server dapat bekerja sama untuk menyediakan HA dan mencegah kehilangan data. Berbagai solusi perangkat lunak pengelompokan tersedia untuk Windows, distribusi Linux, dan berbagai hypervisor mesin virtual. Namun, masing-masing solusi ini membatasi fleksibilitas dan opsi penerapan Anda serta menghadirkan berbagai tantangan seperti kompleksitas teknis dan lisensi yang mahal.
Jangan Menunggu Musibah Mendatang
HA sangat penting untuk sistem, database, dan aplikasi yang penting bagi bisnis. Tetapi dengan berbagai platform yang tersedia, kompleksitas meningkat secara signifikan. Itulah mengapa solusi yang sadar aplikasi sangat masuk akal. Yang Anda butuhkan adalah mitra tepercaya yang memiliki keahlian luas dalam ketersediaan tinggi—mitra seperti SIOS, yang memiliki pengetahuan teknologi untuk memastikan bisnis Anda tetap berjalan.
Jangan menunggu pemadaman atau bencana untuk mengetahui apakah Anda memiliki ketahanan yang dibutuhkan bisnis Anda. Jadwalkan demo yang dipersonalisasi hari ini di https://us.sios.com untuk melihat apa yang dapat dilakukan SIOS untuk bisnis Anda.
Direproduksi dari SIOS