Date: November 2, 2021
Tag: SIOS

Pemulihan bencana
Cara Mengaktifkan Pemulihan Bencana dengan Solusi Perangkat Lunak Pengelompokan Tunggal
Lindungi Aplikasi Windows atau Linux yang Beroperasi dalam Kombinasi Infrastruktur Fisik, Virtual, Cloud, atau Hybrid Cloud dengan Pemulihan Bencana
Apa itu Pemulihan Bencana?
Pemulihan Bencana Sangat Penting untuk Operasi Bisnis yang Berkelanjutan
Pemulihan bencana (DR) adalah strategi dan serangkaian kebijakan, prosedur, dan alat yang memastikan sistem TI, basis data, dan aplikasi penting terus beroperasi dan tersedia bagi pengguna ketika bencana buatan manusia atau alam terjadi. Sementara tim TI memiliki strategi pemulihan bencana, DR merupakan komponen penting dari Rencana Kesinambungan Bisnis setiap organisasi, yang merupakan strategi dan serangkaian kebijakan, prosedur, dan alat yang membuat seluruh bisnis kembali aktif dan berjalan setelah bencana.
Tetapi ketika kita berbicara tentang bencana, itu tidak perlu menjadi badai besar, tornado, banjir, atau gempa bumi yang berdampak pada bisnis Anda. Bencana datang dalam berbagai bentuk, termasuk serangan dunia maya, kesalahan pengguna, kebakaran, pencurian, perusakan, bahkan serangan teroris. Singkatnya, bencana adalah krisis apa pun yang mengakibatkan sistem down dalam jangka waktu lama dan/atau kehilangan data besar dalam skala besar yang berdampak pada infrastruktur TI, pusat data, dan bisnis Anda.
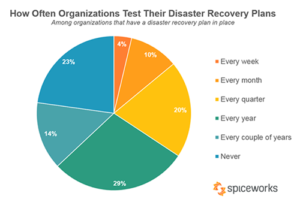
Dalam Spiceworks baru-baru ini survei , 59 persen organisasi mengindikasikan bahwa mereka telah mengalami satu hingga tiga pemadaman (yaitu, gangguan apa pun pada tingkat normal layanan terkait TI) selama satu tahun, 11 persen telah mengalami empat hingga enam, dan 7 persen telah mengalami tujuh atau lagi. Selain itu, survei juga menunjukkan bahwa perusahaan yang lebih besar, yang mengandalkan lebih banyak layanan, lebih mungkin mengalami pemadaman daripada organisasi yang lebih kecil. Misalnya, 71 persen bisnis kecil mengalami satu atau lebih pemadaman dalam 12 bulan terakhir, dibandingkan dengan 79 persen bisnis menengah, dan 87 persen bisnis besar. Ketika Anda melihat statistik tersebut, Anda tahu bahwa Anda hidup dengan waktu pinjaman jika Anda tidak memiliki rencana pemulihan bencana.
Tapi ada kabar baik. Dibandingkan dengan statistik dari tahun-tahun sebelumnya, tampaknya organisasi dari semua ukuran dan dari semua industri bekerja lebih baik dalam hal memiliki rencana pemulihan bencana. Menurut survei Spiceworks yang sama, 95 persen organisasi memiliki rencana DR tetapi sayangnya, 23 persen tidak pernah menguji atau menjalankan rencana mereka. Melatih rencana DR Anda sama pentingnya dengan latihan kebakaran atau latihan pengumpulan siswa. Memiliki rencana di tempat hanyalah langkah pertama. Jika orang-orang yang terlibat dalam pelaksanaan rencana tidak tahu apa yang harus dilakukan, Anda tidak akan dapat pulih dari bencana.
Ketersediaan Tinggi Vs. Pemulihan bencana
Namun sebelum kita melangkah lebih jauh, mari kita perjelas perbedaan antara praktik terbaik untuk menangani kegagalan sistem versus bencana. Untuk memulihkan dari kegagalan sistem, sistem, perangkat lunak, dan data yang berlebihan harus berada di jaringan area lokal (LAN) Anda. Untuk aplikasi database penting, Anda dapat mereplikasi data secara sinkron di seluruh LAN. Ini membuat instans siaga Anda “panas” dan sinkron dengan instans aktif Anda, sehingga siap untuk mengambil alih segera jika terjadi kegagalan. Ini disebut sebagai ketersediaan tinggi (HA) .
Namun, untuk memulihkan sistem, perangkat lunak, dan data jika terjadi bencana berarti komponen yang berlebihan harus berada di jaringan area luas (WAN). Dengan WAN, replikasi data tidak sinkron untuk menghindari dampak negatif terhadap kinerja throughput. Ini berarti bahwa pembaruan untuk instans siaga akan menunda pembaruan yang dibuat untuk instans aktif, yang mengakibatkan penundaan selama proses pemulihan. Karena bencana jarang terjadi, beberapa penundaan mungkin dapat ditoleransi dan bergantung pada (a) seberapa penting bagi bisnis Anda untuk mencapai Sasaran Waktu Pemulihan (RTO) dan Sasaran Titik Pemulihan (RPO) serendah mungkin, dan (b) berapa banyak anggaran yang Anda dapat mengalokasikan untuk mencapai RTO dan RPO terbaik.
RTO adalah durasi maksimum yang dapat ditoleransi dari setiap pemadaman dan RPO adalah jumlah maksimum kehilangan data yang dapat ditoleransi ketika bencana terjadi. Untuk pemulihan bencana, RTO beberapa menit atau bahkan berjam-jam adalah umum dengan beberapa solusi karena terlalu mahal untuk mencoba memulihkan di WAN hanya dalam beberapa menit. Untuk aplikasi mission-critical, organisasi Anda ingin mencapai RPO rendah tetapi semakin rendah RPO Anda, semakin Anda membutuhkan proses untuk memastikan semua data telah direplikasi di server siaga sebelum failover. Upaya ini cenderung meningkatkan waktu pemulihan.
Namun dengan solusi pemulihan bencana SIOS, Anda dapat mencapai RPO minimal hingga tanpa kehilangan data dan RTO satu hingga dua menit.
SIOS Memberikan Satu Solusi untuk Memenuhi Kebutuhan HA dan DR Anda
| Baik Anda memerlukan HA lokal dalam satu situs atau DR yang cepat dan efisien di beberapa situs, solusi SIOS memenuhi semua kebutuhan kelangsungan bisnis Anda. |
NS Solusi pemulihan bencana SIOS adalah cluster multi-situs yang tersebar secara geografis yang menyediakan RPO detik dan RTO menit. Apa yang membuat SIOS berbeda dari banyak penyedia DR lainnya adalah ia menawarkan satu solusi yang memenuhi kebutuhan ketersediaan tinggi dan pemulihan bencana.
Untuk mendukung DR, Anda mengonfigurasi kluster dengan cara yang sama seperti yang Anda lakukan untuk ketersediaan tinggi tetapi dengan dua perbedaan berbeda yang telah dibahas sebelumnya:
- Node klaster DR berada di situs geografis – lokal, virtual, atau di cloud – yang jauh dari instans HA.
- Situs DR berada di jaringan area luas (WAN), yang berarti bahwa replikasi data akan asinkron untuk menghindari dampak negatif terhadap kinerja throughput.
Ingat, replikasi data asinkron berarti bahwa pembaruan ke instans DR akan menunda pembaruan yang dibuat untuk instans aktif tetapi biasanya hanya beberapa detik paling lama. Tetapi dengan replikasi data SIOS yang sangat cepat di seluruh WAN, Anda dapat menyimpan salinan data real-time yang disinkronkan di beberapa server dan pusat data untuk mencapai HA dan DR.
Selain satu solusi tunggal untuk HA/DR dan replikasi data waktu nyata, solusi SIOS HA/DR juga menyediakan:
- Kompresi data tingkat blok untuk meminimalkan beban jaringan
- Pelambatan bandwidth untuk mengatur dan meminimalkan kemacetan jaringan
- Optimalisasi WAN untuk meningkatkan kinerja jaringan
- Integrasi dengan failover tombol tekan untuk mendukung DR dan failover otomatis untuk mendukung HA
- Pendekatan platform agnostik, memungkinkan Anda memilih solusi DR lokal, virtual, cloud, atau hybrid
Studi kasus berikut menunjukkan penggunaan SIOS DataKeeper untuk memberikan HA dan DR dalam satu solusi.
—————————————————————————————————————————————————
Mengaktifkan Perlindungan HA dan DR di Pusat Kesehatan Premier
Rumah Sakit ALYN, yang terletak di Israel, adalah pusat kesehatan rehabilitasi pediatrik utama, yang mengkhususkan diri dalam mendiagnosis dan merehabilitasi bayi, anak-anak, dan remaja penyandang cacat fisik. Orang tua membawa anak-anak mereka dari Israel dan luar negeri untuk menerima berbagai layanan medis, terapi paramedis, dan layanan rehabilitasi canggih tambahan.
Pencarian Solusi yang Tepat
Rumah Sakit ALYN mengoperasikan berbagai aplikasi – termasuk catatan medis elektronik (EMR), manajemen hubungan pelanggan (CRM), database SQL Server, Microsoft Exchange, dan Microsoft Office untuk mendukung operasi klinis dan administratifnya. Sebagai penyedia layanan kesehatan, rumah sakit tunduk pada peraturan pemerintah yang ketat dan perlu menerapkan ketentuan DR yang kuat untuk memastikan perlindungan dan ketersediaan aplikasi mission-critical mereka. Rumah sakit memilih Hyper-V Replica untuk mendukung strategi DR-nya, mengoperasikan dua ruang server yang terpisah secara fisik di tempat, memungkinkan semua mesin virtual (VN) penting yang berjalan di server host Hyper-V mana pun untuk direplikasi ke yang lain di ruangan lain. Sayangnya, konfigurasi ini tidak memenuhi persyaratan RPO dan RTO, sehingga tim TI mulai menyelidiki opsi lain.
Dalam mencari solusi DR yang tepat, tim IT mempertimbangkan Windows Server Failover Clustering (WSFC) yang menggunakan shared storage. Sayangnya, ALYN tidak memiliki SAN dan karena keterbatasan anggaran, penerapan SAN identik di kedua ruang server menjadi sangat mahal. Untuk alasan ini, ALYN menyelidiki solusi pihak ketiga.
Dalam pencariannya untuk failover pihak ketiga perangkat lunak pengelompokan , ALYN menetapkan tiga kriteria:
- Solusinya harus bekerja dengan perangkat keras yang ada.
- Solusinya harus memberikan perlindungan ketersediaan tinggi (HA) dan pemulihan bencana (DR) di semua aplikasi penting rumah sakit.
- Total biaya kepemilikan (TCO) harus sesuai dengan anggaran departemen yang terbatas.
SIOS DataKeeper – Pilihan Jelas
Setelah mengevaluasi beberapa solusi yang berbeda, staf TI memilih SIOS DataKeeper, yang digambarkan oleh tim sebagai solusi “yang memberikan kemampuan kelas operator dengan total biaya kepemilikan yang sangat rendah” dan memberikan HA dan DR dalam satu solusi hemat biaya.
SIOS DataKeeper menggabungkan real-time, replikasi data tingkat blok dengan pemantauan tingkat aplikasi berkelanjutan dan kebijakan failover/failback yang fleksibel dalam solusi total yang mudah diterapkan dan dikelola. DataKeeper memanfaatkan WSFC dan mempertahankan kompatibilitas dengan lingkungan operasi, sehingga memudahkan tim TI untuk mempelajari cara menggunakan solusi dengan cepat dan menyelesaikan konfigurasi HA untuk semua aplikasi dengan cepat.
Dengan DataKeeper, tim TI dapat membuat SANless tiga node cluster failover dengan satu instans aktif dan dua instans siaga. Dengan konfigurasi ini, ALYN dapat terus memperbarui sistem dan perangkat lunak tanpa mengganggu operasi karena instans aktif dapat dipindahkan ke server mana pun dalam kluster tiga simpul dan tetap terlindungi sepenuhnya selama periode pemeliharaan perangkat keras dan perangkat lunak yang direncanakan.
Selain itu, SIOS dapat bekerja dengan semua jenis penyimpanan dan replikasi data yang dioptimalkan WAN, yang menyederhanakan implementasi situs DR jarak jauh ALYN. Untuk mempertahankan kinerja throughput transaksional yang tinggi, replikasi data di seluruh WAN terjadi secara asinkron tetapi SIOS DataKeeper menggunakan teknik khusus untuk mengoptimalkan transmisi data, memungkinkan ALYN untuk mencapai RPO dan RTO yang menuntut.
Garis bawah
Hari ini, SIOS DataKeeper menyediakan perlindungan ketersediaan tinggi untuk semua aplikasi penting Rumah Sakit ALYN. Komentar Uri Inbar, Direktur TI Rumah Sakit ALYN, “Dengan SIOS kami menemukan solusi yang memberikan kemampuan kelas operator dengan total biaya kepemilikan yang sangat rendah. Bagi kami, itu adalah pilihan yang jelas.
Rumah Sakit ALYN menguji konfigurasi secara teratur, dan secara rutin mengubah penunjukan aktif dan siaga, sambil mengarahkan replikasi data sesuai kebutuhan selama pembaruan perangkat lunak yang direncanakan. Aplikasi terus berjalan tanpa gangguan.
——————————————————————————————————————————————————
Pemikiran Terakhir tentang Pemulihan Bencana SIOS
Di lingkungan Windows, SIOS DataKeeper untuk Windows Server tersedia dalam Edisi Standar dan Edisi Cluster yang lebih tangguh.SIOS DataKeeper Edisi Standar menyediakan replikasi data real-time untuk perlindungan pemulihan bencana di lingkungan Windows Server.SIOS DataKeeper Cluster Edition mulus terintegrasi dengan Windows Server Failover Clustering (WSFC), memungkinkan ketersediaan tinggi dan konfigurasi pemulihan bencana.
SIOS LifeKeeper dan DataKeeper mendukung semua distribusi Linux utama, termasuk Red Hat Enterprise Linux, SUSE Linux Enterprise Server, CentOS, dan Oracle Linux dan mengakomodasi berbagai arsitektur penyimpanan.
Kunjungi referensi di bawah ini untuk informasi lebih lanjut tentang SIOS DataKeeper atau SIOS LifeKeeper: Referensi
- https://betanews.com/2019/05/28/disaster-recovery-sql-server/
- https://community.spiceworks.com/blog/3138-data-snapshot-how-well-ecomplete-are-businesses-to-bounce-back-from-disaster
- https://www.spiceworks.com/press/releases/spiceworks-study-reveals-one-in-four-companies-never-test-their-disaster-recovery-plan/
Lihat Buku Putih kami: Memahami Pemulihan Bencana untuk Opsi untuk SQL Server