Date: Februari 19, 2018
Tag: Microsoft Windows Server Failover Clustering
Mengkonfigurasi Cluster Failover Sanless Hyper-V Dengan DataKeeper
Pertanyaan tentang SANLess
T. Apa itu cluster SANLess?
A. Ini adalah cluster yang menggunakan penyimpanan lokal dan bukan SAN.
Q. Mengapa saya ingin mengonfigurasi Cluster Failover Sanless Hyper-V?
A. Ada beberapa alasan:
- Hilangkan biaya SAN
- Hilangkan SAN sebagai satu titik kegagalan
- Manfaatkan opsi penyimpanan kecepatan tinggi seperti ioDrives Fusion-io dan perangkat penyimpanan berkecepatan tinggi lainnya yang disambungkan secara lokal
- Peregangan cluster melintasi lokasi geografis untuk pemulihan bencana
- Sederhanakan manajemen
- Hilangkan kebutuhan administrator SAN
Mengkonfigurasi Sanless Hyper-V Failover Cluster dengan DataKeeper Cluster Edition mudah
Jika Anda tahu apa-apa tentang Windows Server Failover Clustering, maka Anda sudah tahu 99% solusinya. Tidak perlu khawatir jika Anda belum pernah membangun Windows Server Failover Cluster sebelumnya. Microsoft telah membuatnya mudah dan tidak menyakitkan. Untuk pemula, saya telah menulis artikel selangkah demi selangkah yang memberi tahu Anda cara membangun cluster Windows Server 2012 #SANLess di posting blog saya di sini.
Dua Pilihan Untuk Membuat Mesin Virtual Yang Sangat Tersedia
Jika Anda telah mengikuti langkah-langkah di posting saya, Anda siap untuk membuat mesin virtual pertama yang sangat tersedia. Pilihan pertama mengasumsikan bahwa Anda memiliki mesin virtual yang ada yang ingin Anda jadikan sangat tersedia. Pilihan kedua mengasumsikan Anda membangun mesin virtual yang sangat tersedia dari awal.
Mengkonfigurasi Sumber Data Cluster Volume DataKeeper
SANLess Hyper-V cluster membutuhkan satu VM per volume. Oleh karena itu, Anda harus memastikan bahwa penyimpanan Anda telah dipartisi sehingga Anda memiliki volume yang cukup untuk setiap VM. Penyimpanan pada setiap node cluster harus dikonfigurasi secara identik dalam hal huruf drive dan ukuran partisi. Apakah partisi dikonfigurasi dengan benar dan VM Anda berada di partisi yang ingin Anda tiru. Kemudian, buka antarmuka DataKeeper dan berjalan melalui wizard tiga langkah untuk membuat Sumber Daya Volume DataKeeper seperti yang ditunjukkan di bawah ini.
Pertama, buka antarmuka DataKeeper dan klik Connect to Server. Lakukan ini dua kali untuk terhubung ke kedua server.

Setelah terhubung, klik Buat Ayub untuk membuat cermin volume yang berisi mesin virtual yang ingin Anda buat sangat tersedia seperti yang ditunjukkan di bawah ini. Dalam contoh ini kita akan merefleksikan drive E.

Bila mungkin, teruskan replikasi lalu lintas di jaringan pribadi. Dalam kasus ini, kami menggunakan jaringan 10.0.0.0/8 untuk lalu lintas replikasi. Ini bisa menjadi kabel patch sederhana yang menghubungkan dua server di dua NIC yang tidak terpakai.


Layar terakhir menunjukkan pilihan yang tersedia untuk mirroring. Untuk jaringan area lokal, Synchronous mirroring lebih diutamakan. Saat mereplikasi jaringan wide area, Anda akan ingin menggunakan replikasi asinkron dan mungkin mengaktifkan kompresi. Saya tidak akan membatasi bandwidth Maksimum. Karena itu berpotensi menyebabkan cermin Anda tidak sinkron jika tingkat perubahan Anda (Disk Right Bytes / detik) melebihi bandwidth Maksimum yang ditentukan. Namun, Anda mungkin ingin mengaktifkan bandwidth maksimum sementara selama proses pembuatan cermin awal. Jika tidak, DataKeeper dapat membanjiri jaringan dengan lalu lintas replikasi awal saat mencoba melakukan sinkronisasi sesegera mungkin. Baik bandwidth maksimum dan pengaturan Kompresi dapat disesuaikan setelah cermin dibuat. Namun, Anda tidak dapat mengubah antara mirroring Synchronous dan Asynchronous begitu cermin telah dibuat tanpa menghapus cermin dan menciptakannya kembali.
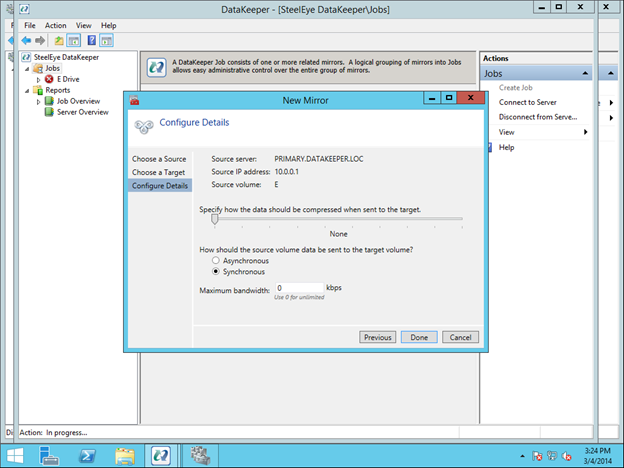
Pada akhir proses pembuatan cermin Anda akan melihat popup yang menanyakan apakah Anda ingin mendaftarkan secara otomatis volume ini sebagai volume cluster. Pilih Ya, ini akan membuat sumber volume DataKeeper dalam Failover Clustering Available Storage.

Anda sekarang siap untuk membuat VMs Anda yang sangat tersedia.
Opsi 1 – Clustering Sebuah VM yang ada
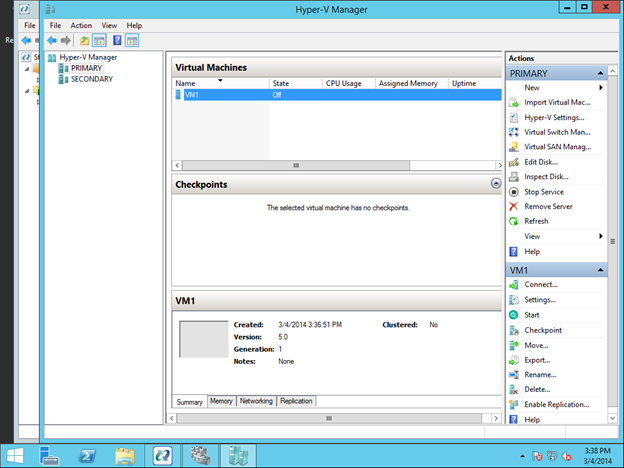
Sekali lagi, prosedur ini mengasumsikan Anda memiliki VM yang ada yang ingin Anda jadikan sangat tersedia. Jika Anda tidak memiliki VM yang ada, Anda akan ingin mengikuti prosedur di Opsi 2 – Membuat VM yang Tersedia dengan Baik. Jika tidak, Anda harus memiliki VM saat melihat Manajer Hyper-V seperti yang ditunjukkan di bawah ini.
Semua file VM seharusnya sudah berada pada volume yang direplikasi, seperti yang ditunjukkan di bawah ini. Jika tidak, Anda harus memindahkan file sebelum mencoba mengelompokkan VM.

Untuk memulai proses clustering, buka Failover Cluster Manager. Klik kanan pada Configure Roles dan pilih Virtual Machine sebagai role yang ingin Anda buat.

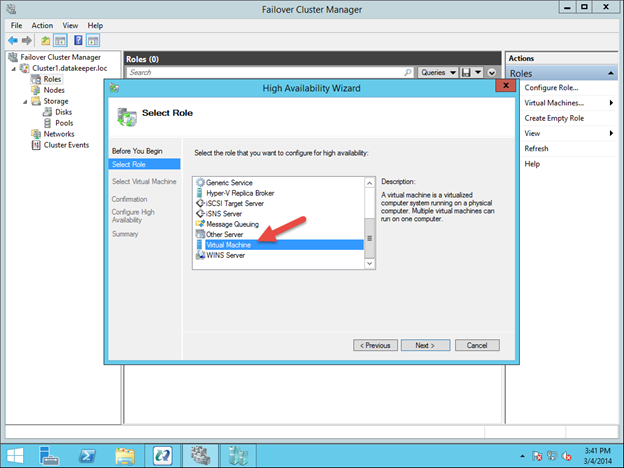
Ini akan meluncurkan Wisaya Ketersediaan Tinggi. Pada titik ini Anda harus memilih VM yang ingin dikelompokkan dan masuk melalui wizard seperti gambar di bawah ini.

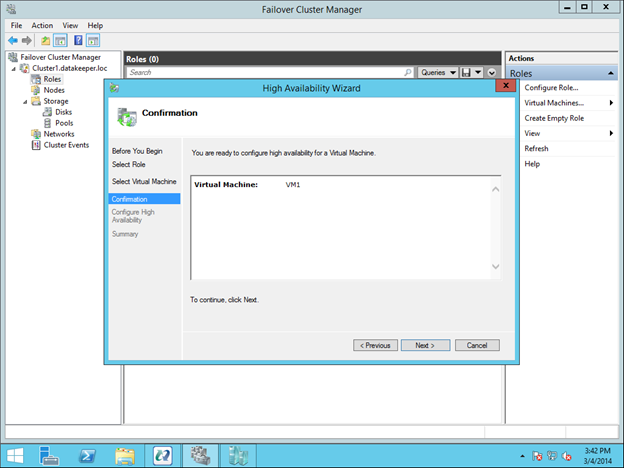
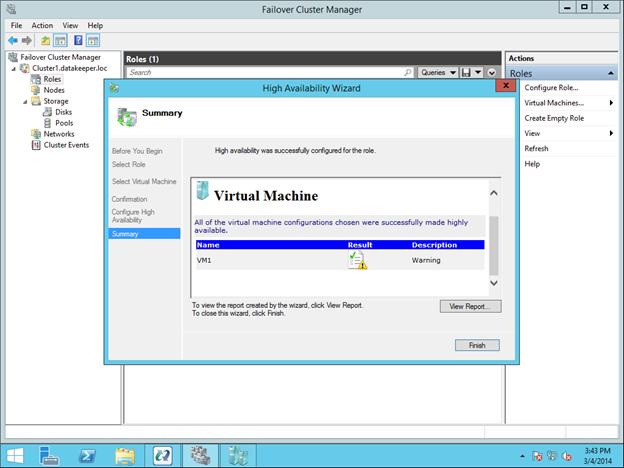
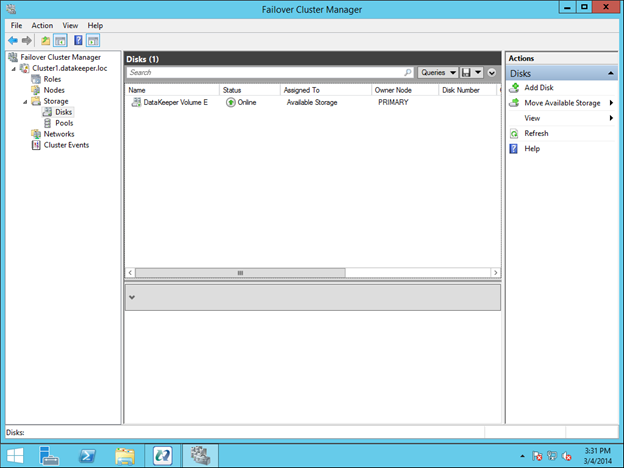
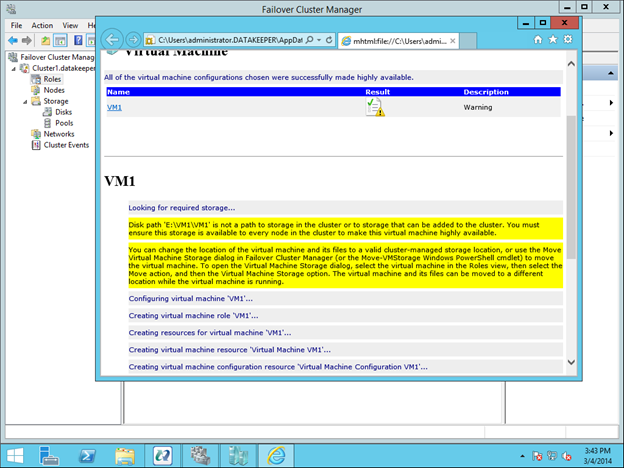
Anda akan melihat bahwa sumber VM akan dibuat, namun akan ada beberapa peringatan. Peringatan menunjukkan bahwa drive E saat ini tidak menjadi bagian dari Grup Sumber Cluster VM.
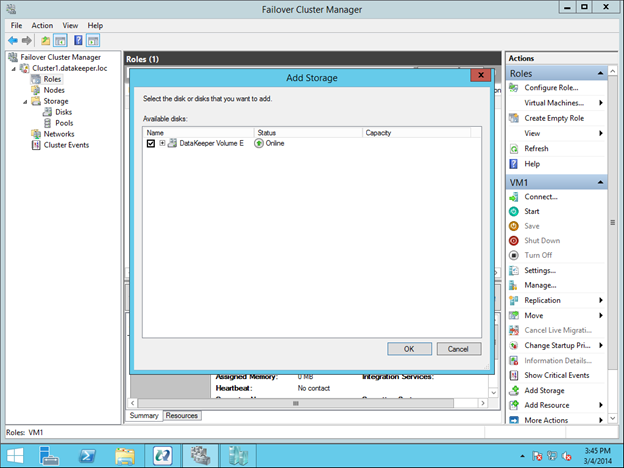
Untuk membuat bagian DataKeeper Volume E dari Grup Sumber Cluster VM, klik kanan pada peran dan pilih Add Storage. Tambahkan Volume DataKeeper yang akan Anda lihat tercantum di Available Disk.


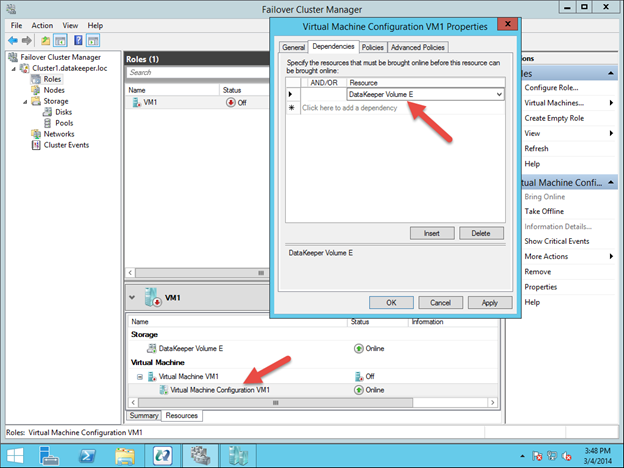
Bagian terakhir adalah memilih Properties of the Virtual Machine Configuration (bukan Mesin Virtual) dan membuatnya bergantung pada penyimpanan yang baru saja Anda tambahkan ke grup sumber daya.
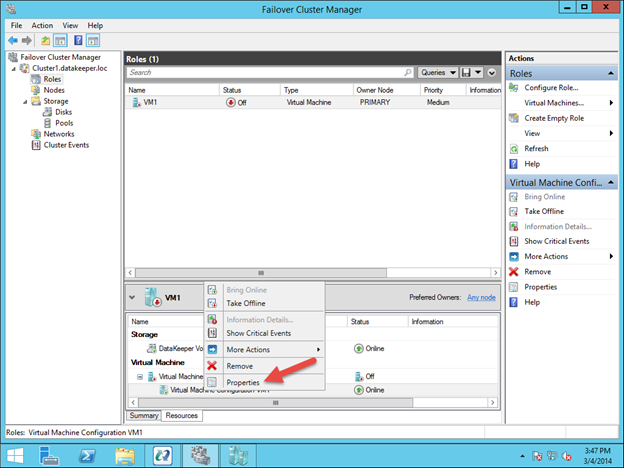
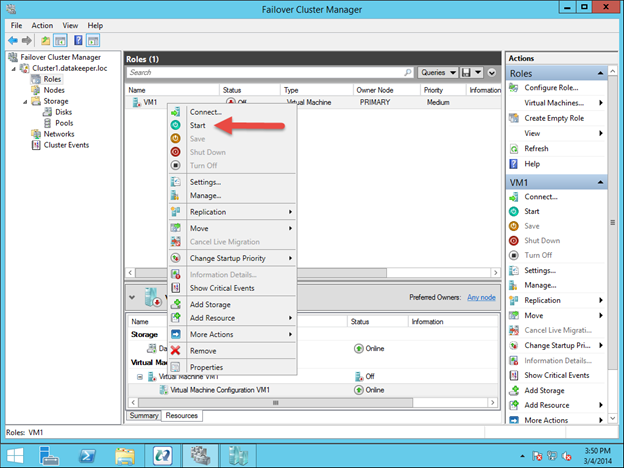
Anda sekarang harus bisa memulai VM.

Opsi 2 – Menciptakan VM yang Sangat Tersedia dari Gores
Dengan asumsi Anda ingin membuat VM yang sangat tersedia dari awal, Anda dapat menyelesaikan keseluruhan proses ini dari Hyper-V Virtual Machine Manager seperti yang ditunjukkan di bawah ini. Langkah ini mengasumsikan bahwa Anda telah membuat cermin drive E menggunakan DataKeeper seperti yang dijelaskan dalam Mengkonfigurasi bagian Sumber Volume DataKeeper.
Untuk memulai, buka Failover Cluster Manager dan klik kanan pada Peran dan pilih Virtual Machine – New Virtual Machine.

Ikuti langkah demi langkah wizard dan pilih opsi yang ingin Anda gunakan untuk VM. Saat memilih tempat untuk menempatkan VM, pilih node cluster yang saat ini merupakan pemilik dari Available Storage. Ini juga akan menjadi sumber cermin.
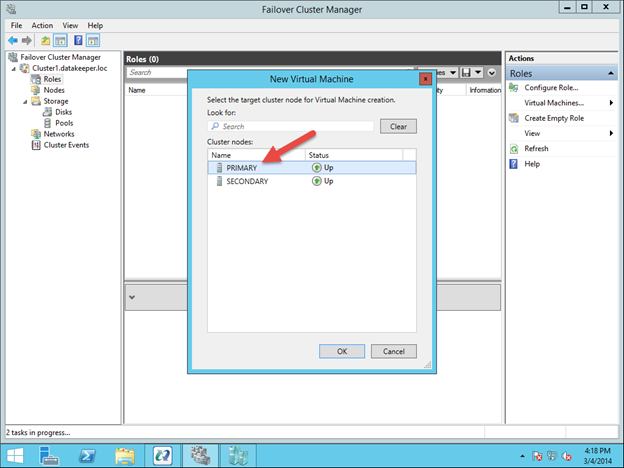
Pastikan saat menentukan Nama dan Lokasi VM, Anda memilih lokasi volume yang direplikasi.

Sisanya pilihan terserah Anda. Pastikan file VHD terletak pada volume yang direplikasi.


Anda akan melihat VM yang sangat tersedia dibuat, namun ada peringatan tentang penyimpanan. Anda perlu menambahkan DataKeeper Volume Resource ke VM Cluster Resource Group seperti yang ditunjukkan di bawah ini.
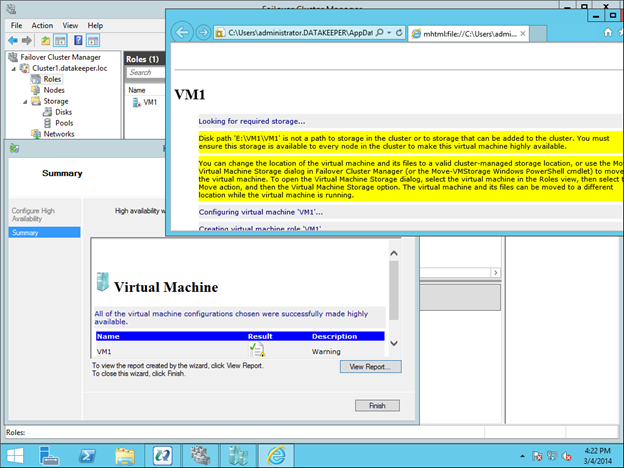
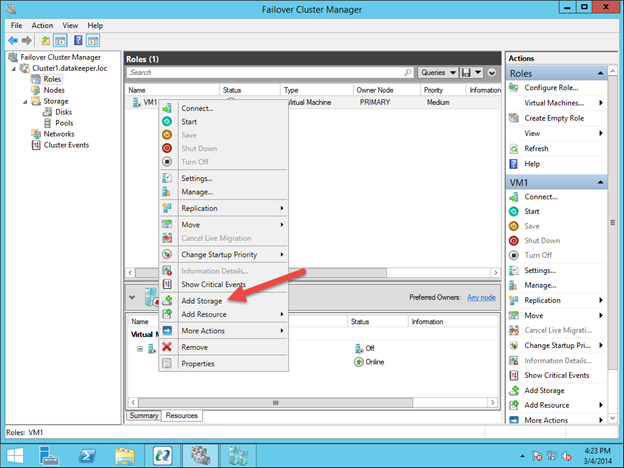

Setelah Volume DataKeeper ditambahkan ke VM Cluster Resource Group, tambahkan Volume DataKeeper sebagai ketergantungan sumber daya Konfigurasi Mesin Virtual.
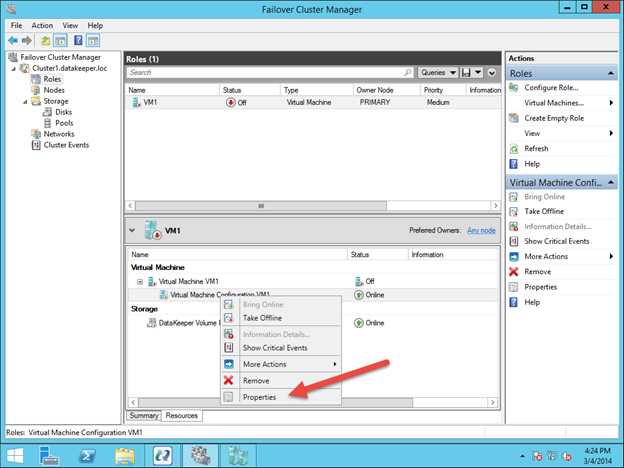

Anda sekarang memiliki mesin virtual yang sangat tersedia.

Ringkasan
Dalam posting blog ini, kami membahas apa yang merupakan kluster #SANLess. Kami memilih SIOS DataKeeper untuk Mengkonfigurasi Sanless Hyper-V Failover Cluster. Setelah dibangun, cluster tersebut berperilaku persis seperti cluster berbasis SAN, Ini mencakup kemampuan melakukan Live Migration, Quick Migration dan failover otomatis jika terjadi kegagalan yang tidak terduga.
Sebuah cluster #SANLess menghilangkan biaya SAN dan juga titik tunggal kegagalan SAN. DataKeeper Cluster Edition mendukung beberapa node dalam SAN. Jadi konfigurasi yang meregangkan kedua LAN dan WAN adalah semua solusi yang mungkin untuk ketersediaan tinggi Hyper-V dan pemulihan bencana. DataKeeper mendukung penyimpanan lokal manapun. Ini membuka kemungkinan penggunaan SSD SSD berkecepatan tinggi lokal atau penyimpanan NAND Flash untuk kinerja tinggi tanpa melepaskan ketersediaan tinggi.
Jika Anda menikmati tip membaca untuk Mengkonfigurasi Sanless Hyper-V Failover Cluster, baca selengkapnya tentang pengelompokan di sini
Dilaporkan dengan izin dari https://clusteringformeremortals.com/2014/03/04/configuring-a-sanless-hyper-v-failover-cluster-with-datakeeper-cluster-edition/