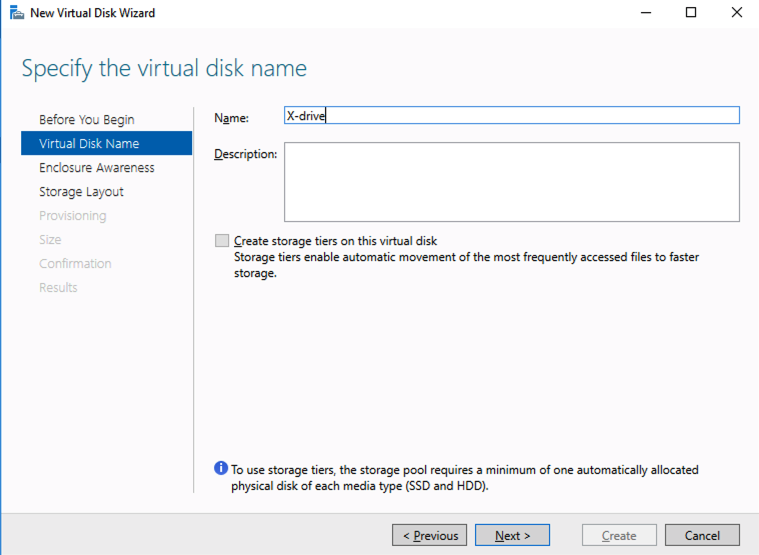
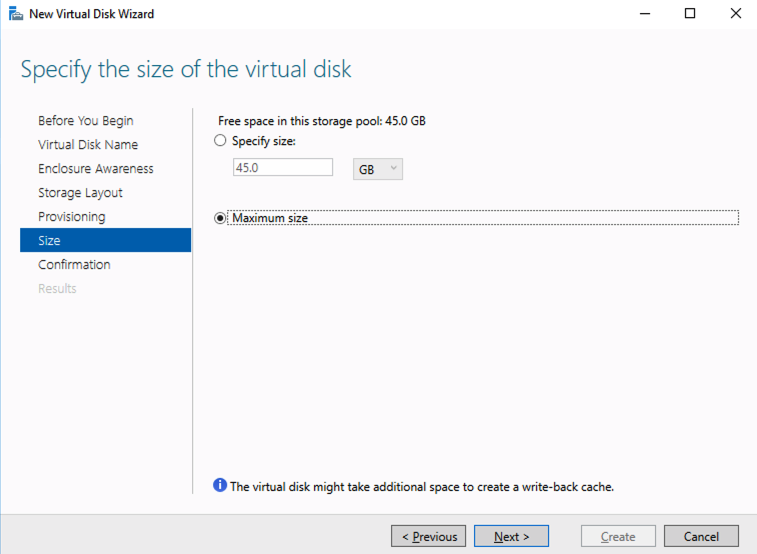
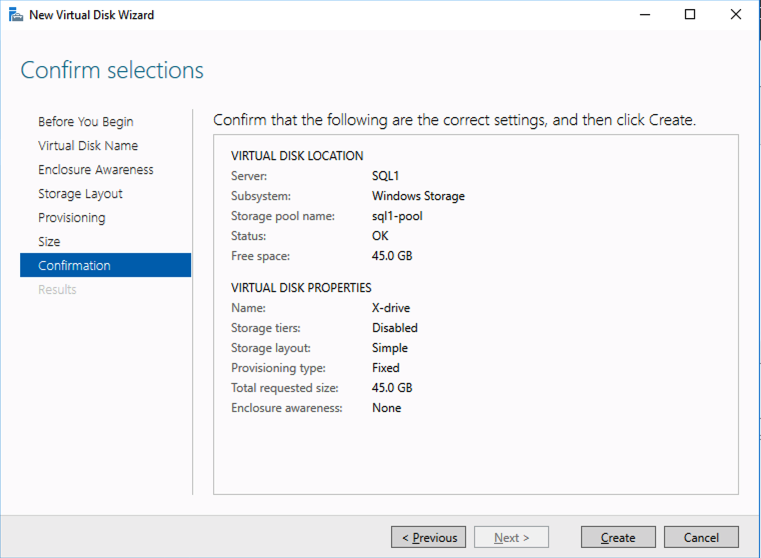
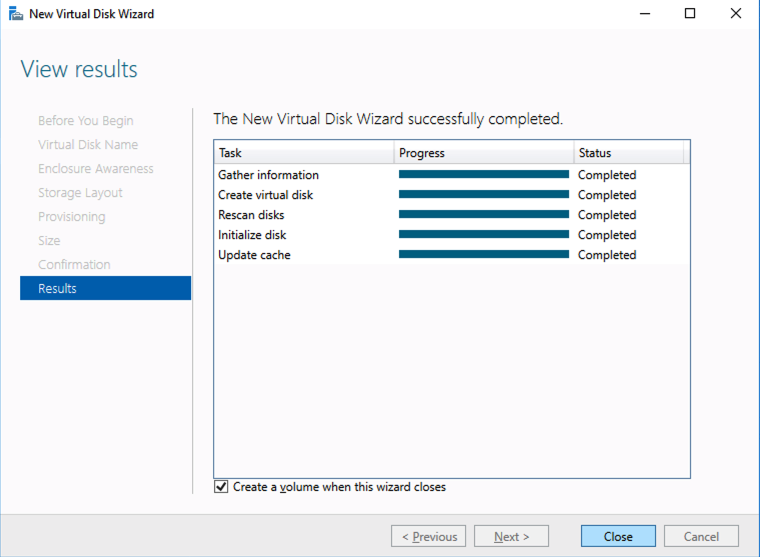
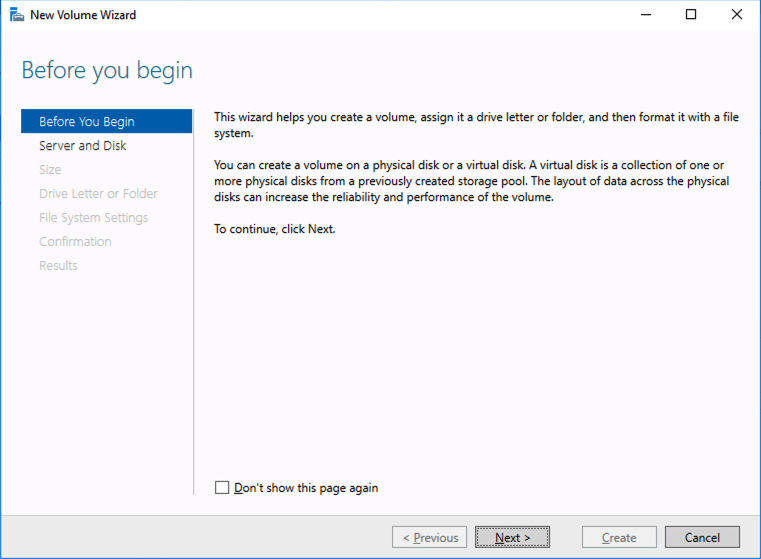
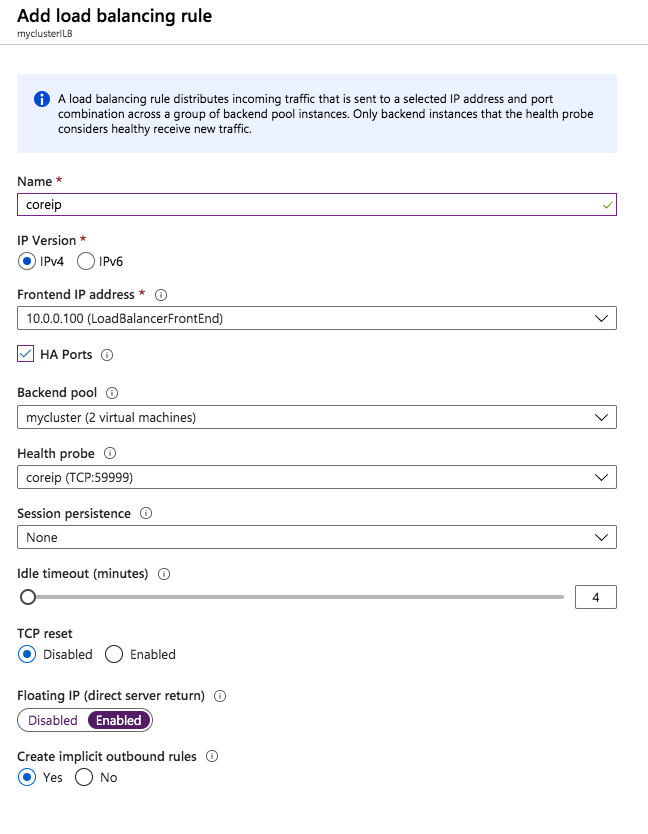
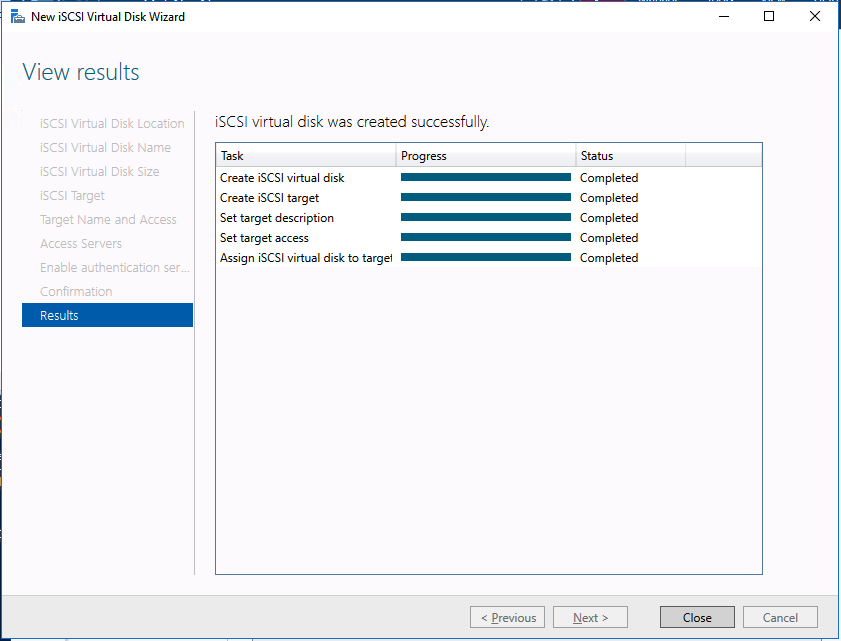
Test/QA Systems are a Critical Part of Enterprise Availability
“I could kiss you,” that’s what a friend blurted out to me nearly three decades ago as she ran towards me. She had dropped her reeds for her saxophone on the way to one of the biggest band competitions in our region. I didn’t know whose they were, but when I saw the pack of reeds on the seat on the bus I picked them up and took them with me to the warm-up area. Three minutes into her warm-up, her 1st reed cracked and she panicked as she reached into empty pockets for replacements. When I piped up that I had found them, she blurted out, “I could kiss you right now.”
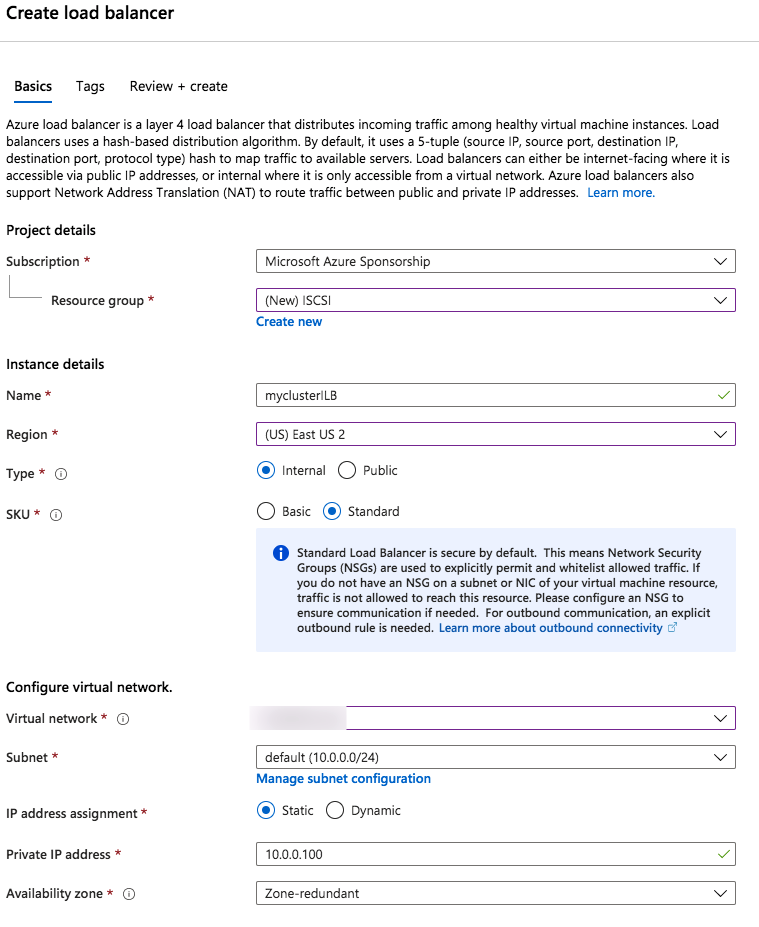
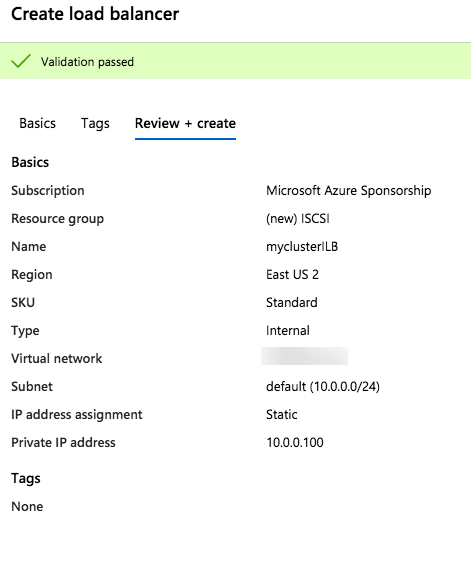
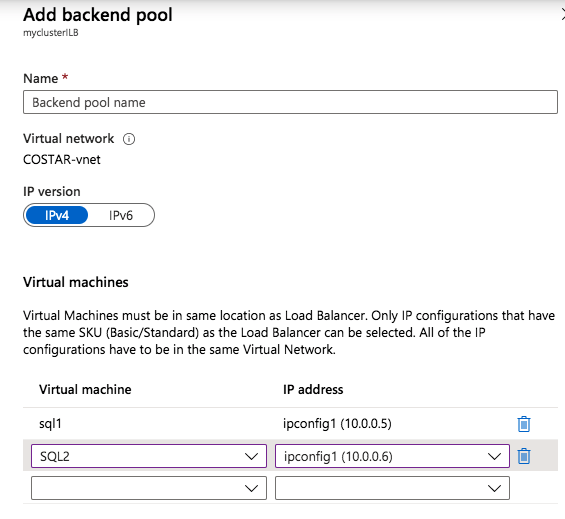
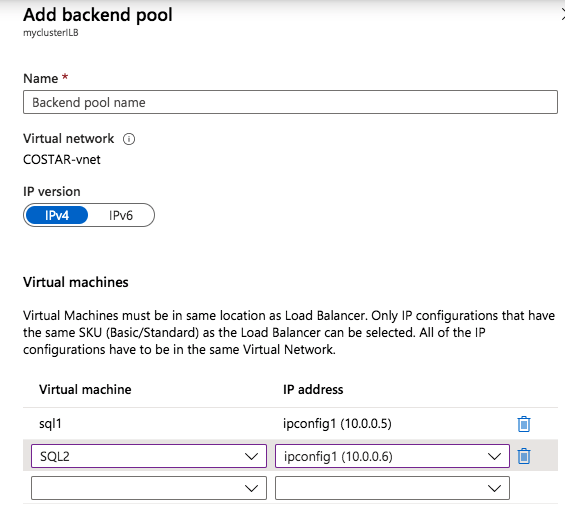
As the VP of Customer Experience at SIOS Technology Corp. I have the unique and distinct pleasure of working with a number of enterprise customers and partners at different phases of the availability spectrum. Sometimes I have the opportunity of working with end customers for issue resolution, mitigation, and improvements. At other times our teams are actively working with partners and customers to architect and implement enterprise availability to protect their systems from downtime. A recent customer experience reminded me of something that happened nearly 30 years ago when my friend blurted out, “I could kiss you.”
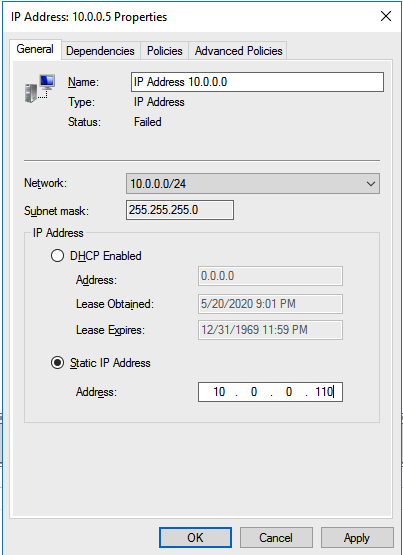
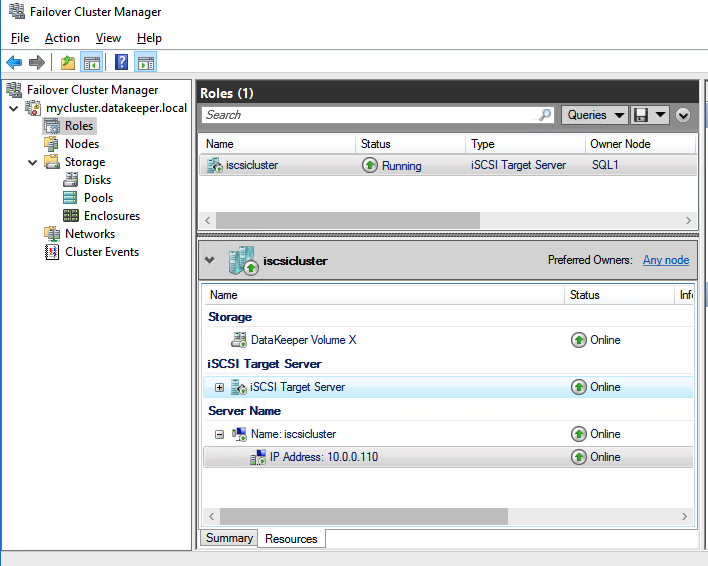
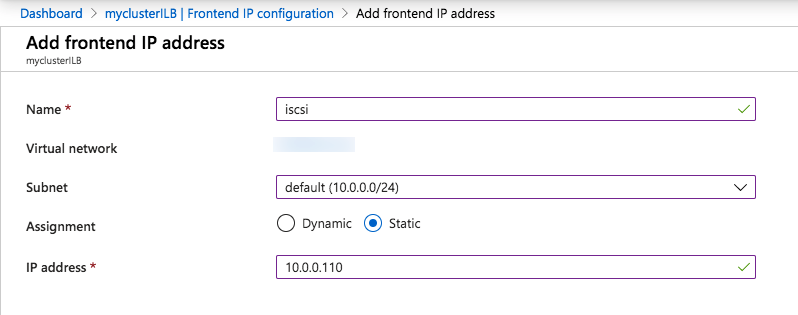
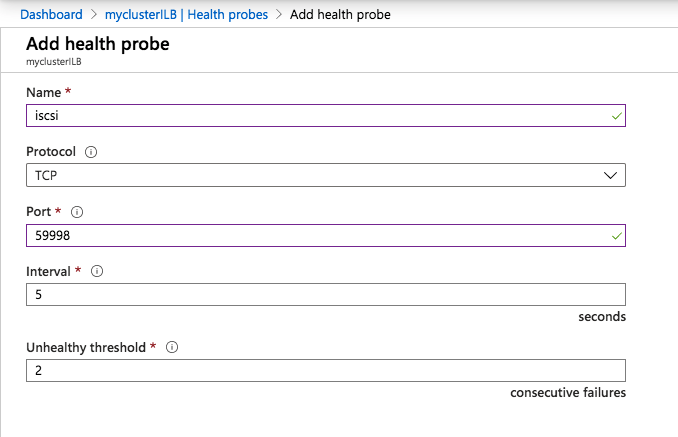
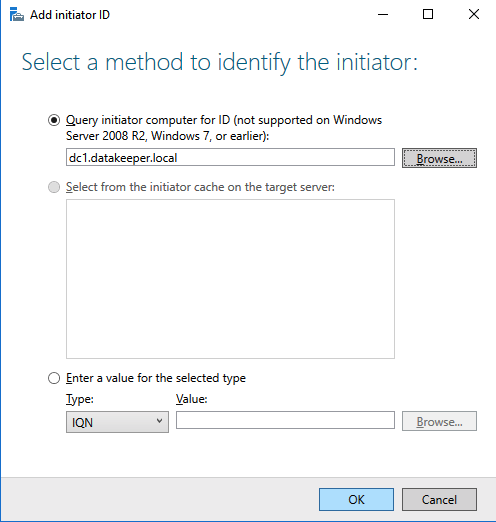
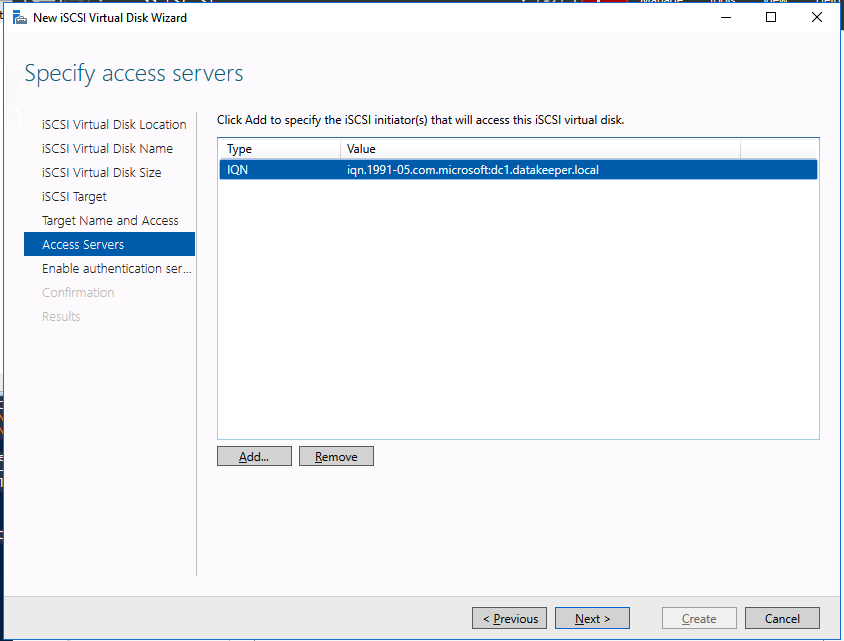
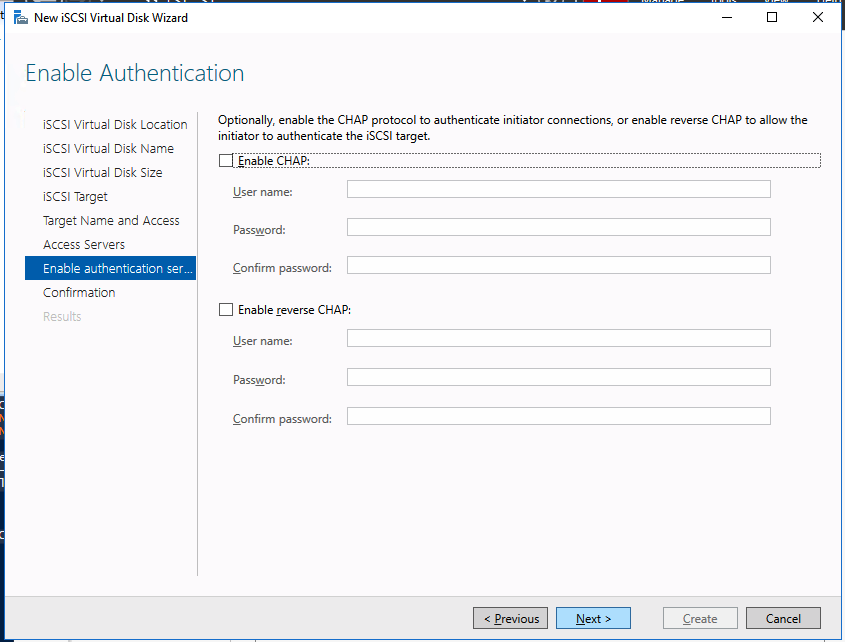
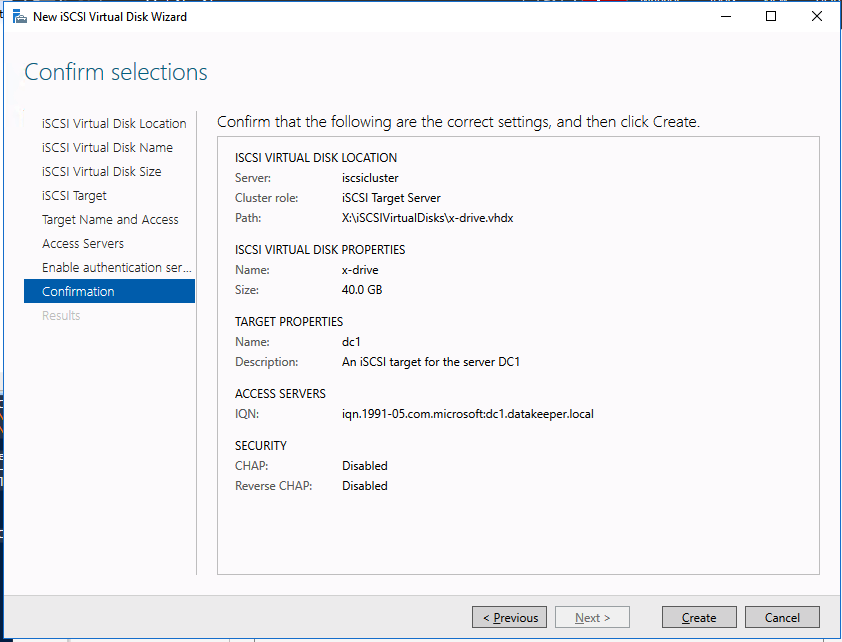
My team and I were on a customer call. The call began with the usual pleasantries, introductions, and an overview of the customer’s enterprise environment. Thirty minutes into the call, things were going so well. Their architecture was solid, thoughtful, and well documented. Their team was knowledgeable, technically sound, and experienced. But then, the customer intimated that due to cost savings they would not be planning to maintain a dedicated test/quality system. I took a deep breath. Actually it was more of an exhale like the rush of air from a gut punch. I prepared to respond, but before I could a voice broke through. “The number one cause of downtime is lack of process,” exclaimed the Partner Rep Architect on the call with us. After a brief banter, the customer agreed to maintain a test/QA system and I nearly blurted out, “I could kiss you!”
On the front lines of many Enterprise deployments (new systems, data center migrations, and system updates) my teams in Support and Services have seen dozens of issues that could have been mediated by utilizing a test system/cluster.
A test/quality system is an invaluable part of an HA strategy to avoid downtime. Common tasks associated with maintaining an enterprise deployment such as patches, updates, and configuration changes come with risk. Enormous risk.
Commonly identified risks of testing in production include several serious and potentially catastrophic issues:
- Corrupted or invalid data
- Leaked protected data
- Incorrect revenue recognition (canceled orders, etc.)
- Overloaded systems
- Unintended side effects or impacts on other production systems
- High error rates that set off alerts and page people on-call
- Skewed analytics (traffic funnels, A/B test results, etc.)
- Inaccurate traffic logs full of script and bot activity (a)
If a customer attempts to apply risky changes in production, the result can be quite damaging. On top of those listed above, there is an increased risk of downtime, corruption of application installations, and in some cases irreversible damage. Take the case of Customer X (a high profile SAP Enterprise shop in the manufacturing industry).
After reading a critical notice from a reputable site, the OS Administrator quickly updated his production nodes to the latest kernel update available. Within hours the Production nodes began a series of uninitiated crashes and kernel panics. In his haste, he had installed a kernel that was incompatible with his configuration; the combination of existing application packages, devices, file systems, and related packages. This caused a production outage and several high priority escalations to multiple vendors.
When patches are applied to a test/QA or sandbox system, patches and critical fixes can be managed and verified to reduce loss of productivity and unplanned downtime. Testing applications in a production-like environment allows you to identify unforeseen problems and correct the issues before they adversely impact your operations. Pre-production design and testing eliminate costly business disruption, improve your customer experience and protect your brand.
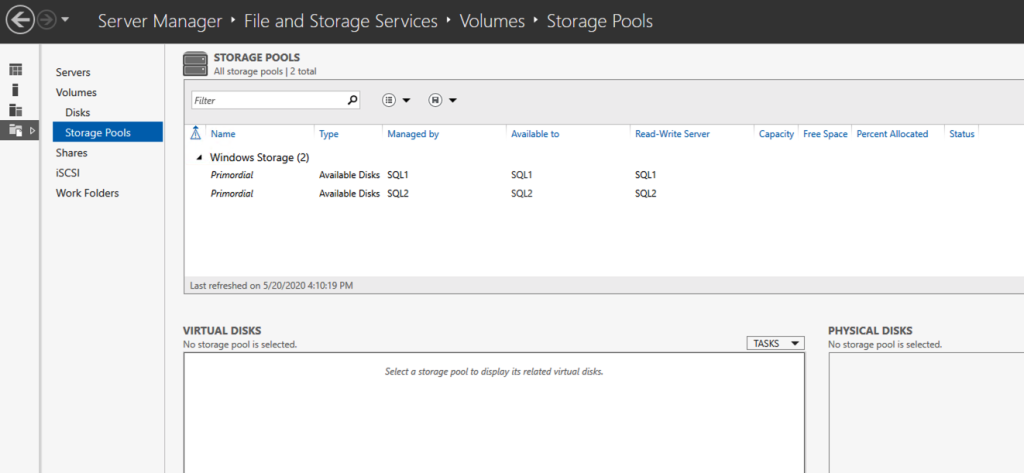
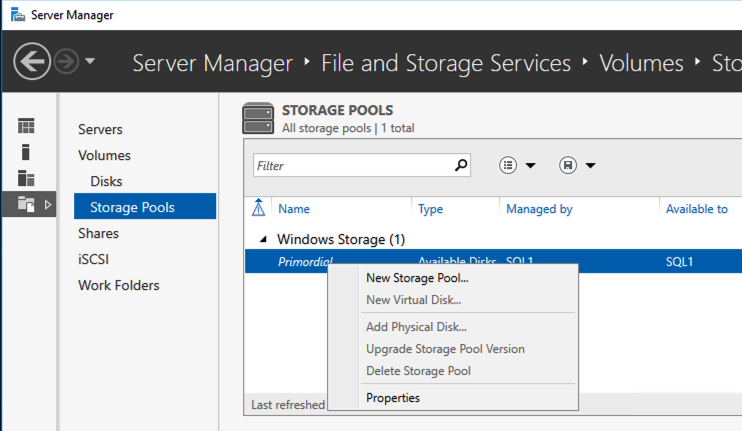
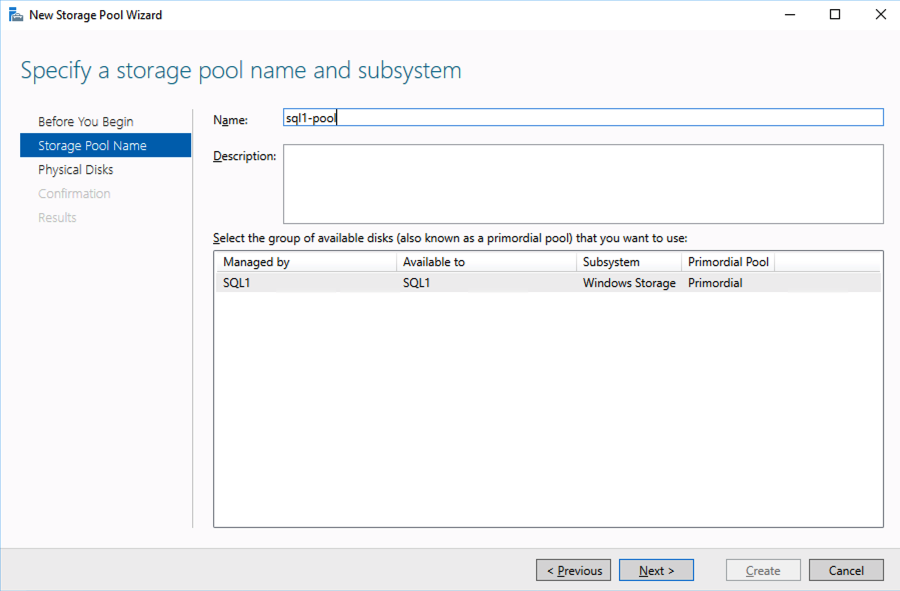
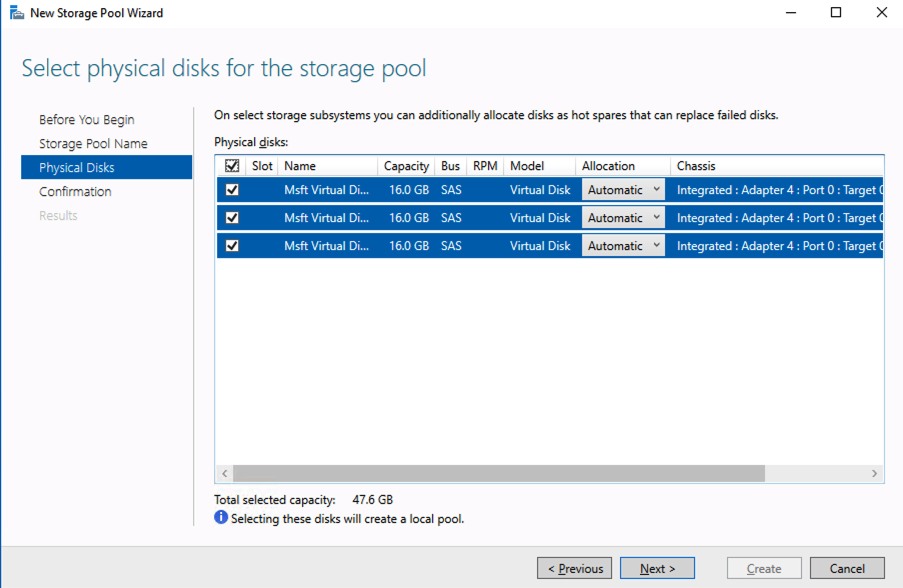
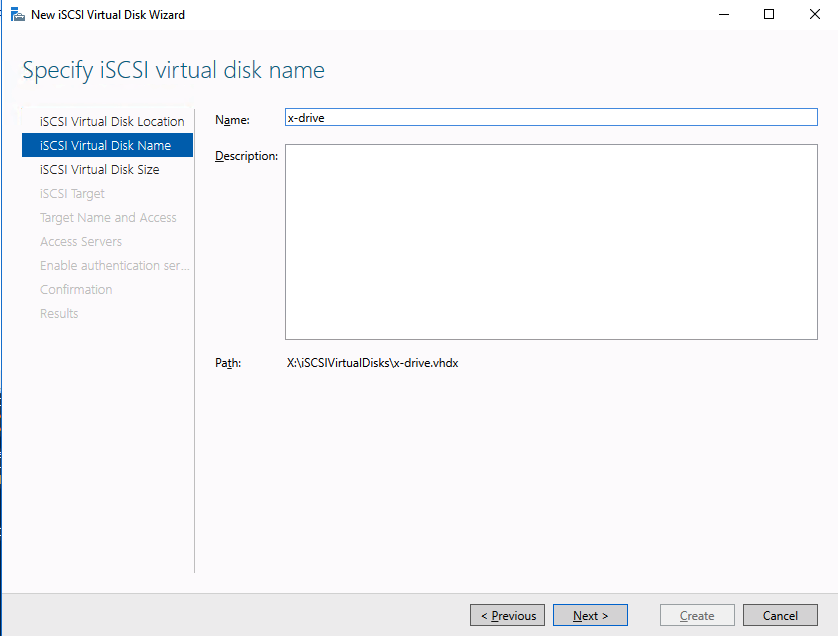
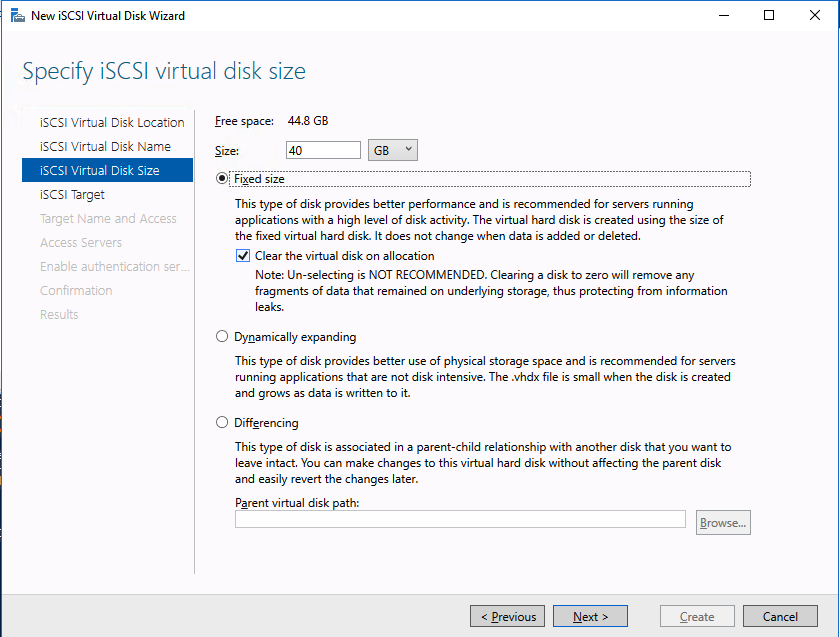
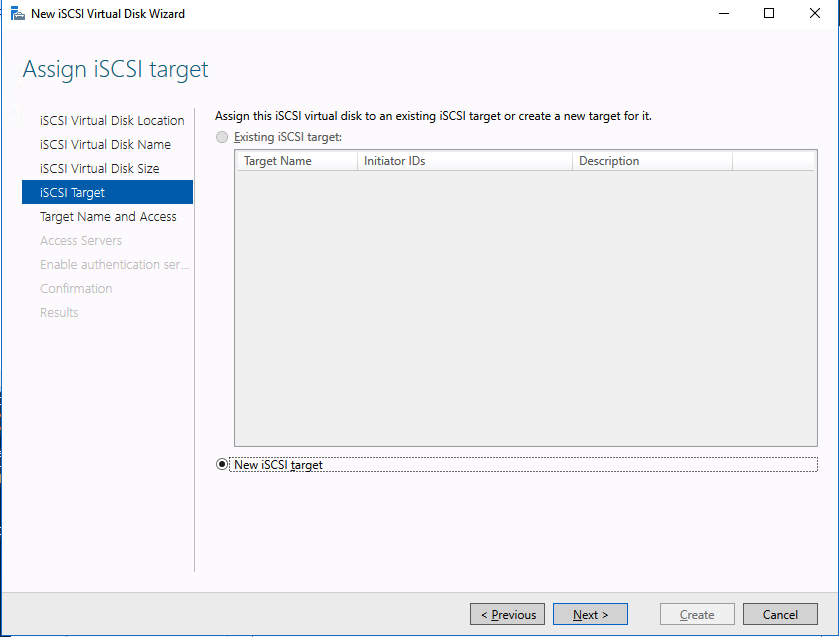
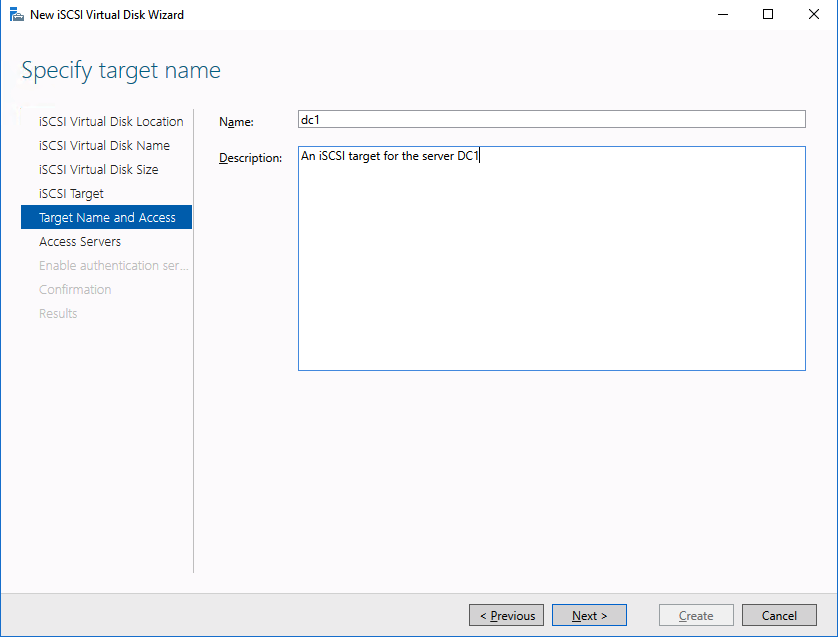
Using a test QA System to Improve Production Availability and Processes
Here are the basics that using a test/QA system, can provide for improving your production availability and processes. A controlled environment, that is similar (it must resemble production as close as possible) to the production environment, provides the ability to:
- Test kernel updates and security updates
- Validate settings and configuration tuning
- Reproduce production issues and test software updates and patches
- Verify application version compatibility and reduce the risk of downtime due to incompatible changes
- Provide a safe space to practice and revise go-live, maintenance, outage, and other enterprise procedural activities
- Train new hires and team members without impacting enterprise clients
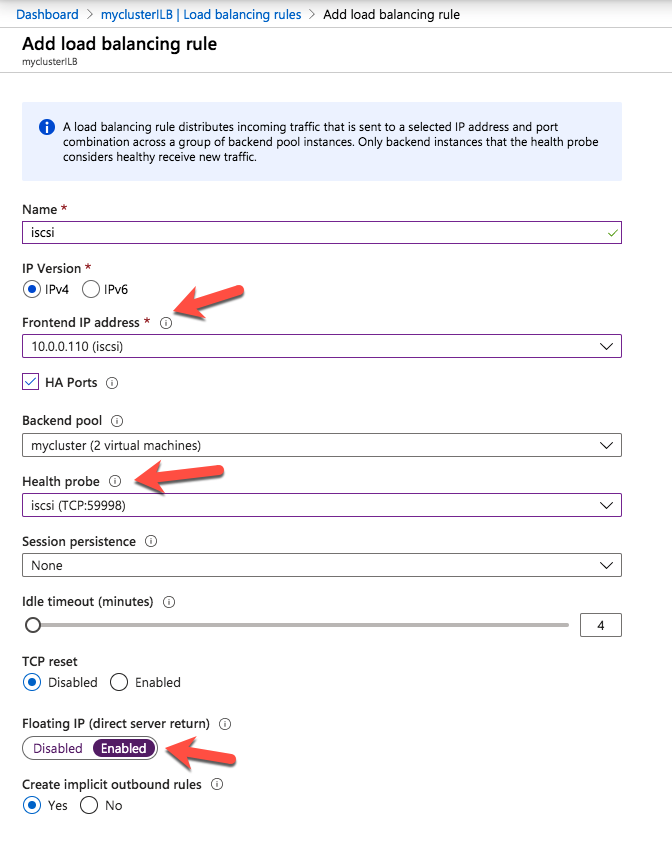
If you have a Test/QA environment for deploying your critical enterprise availability software, I could kiss you right now. Having this environment gives your team the ability “to test, validate and verify(2)” architecture, business requirements, user scenarios, and general integration with a system or set of systems that most closely resembles the production environment- you know the one that makes the money. Of course, you will still have to schedule windows to maintain your production systems and perform testing on them as well, but after a safe buffer step has been completed in between.
— Cassius Rhue, VP, Customer Experience
————-
References:
- https://opensource.com/article/19/5/dont-test-production Accessed 5/4/2020
- https://www.softwaretestingclass.com/system-testing-what-why-how/ Accessed 5/4/2020