SIOS Announces New Version 8.8 of SIOS Protection Suits for Windows
Enhanced HA Clustering for Business Critical Applications on AWS
SIOS is pleased to announce version 8.8 of SIOS Protection Suite for Windows – with innovations designed to make HA clustering in the cloud faster and easier.
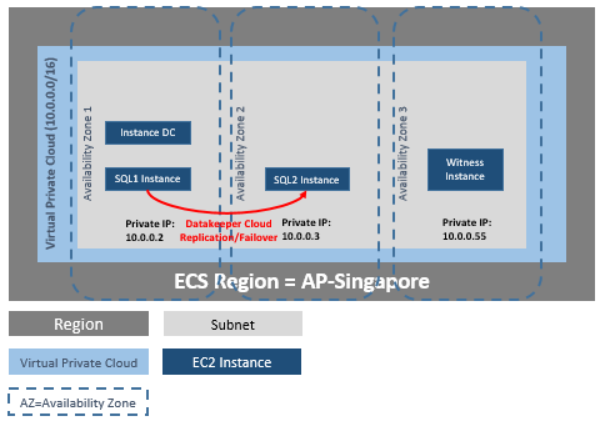
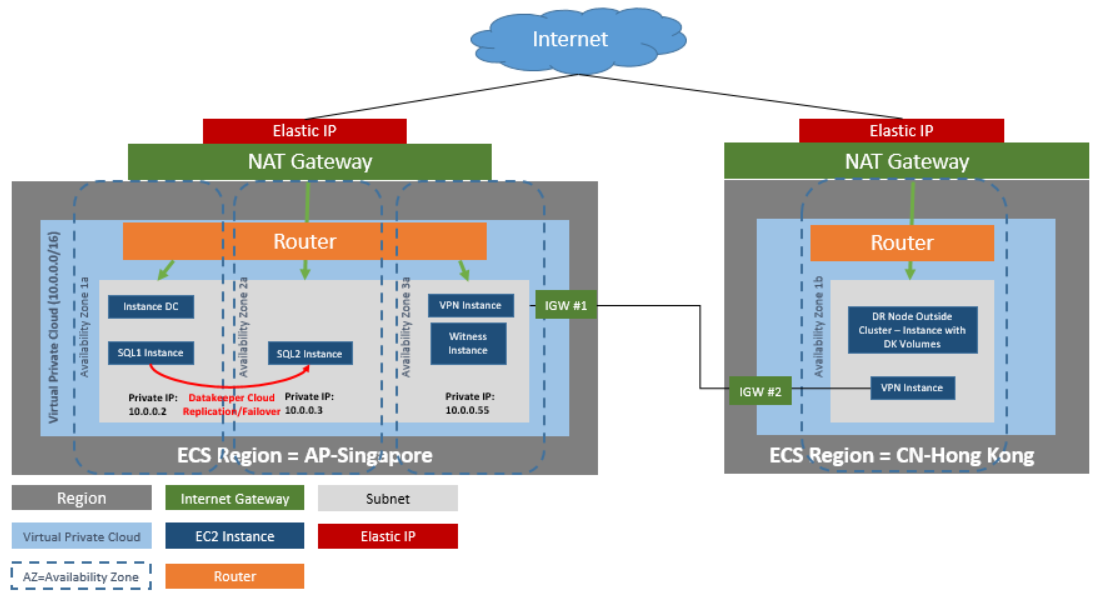
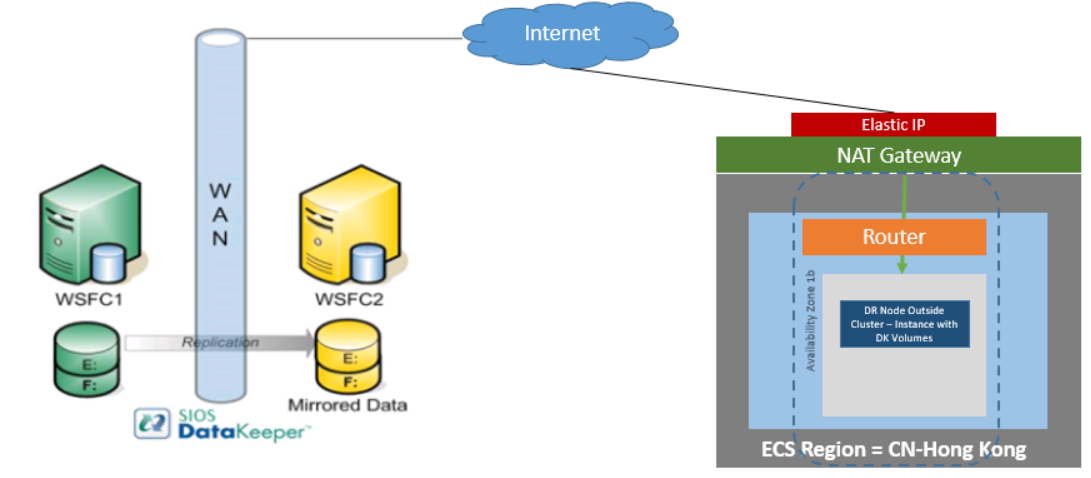
SIOS Protection Suite for Windows includes SIOS Datakeeper Cluster Edition for efficient host-based, block level replication, SIOS LifeKeeper for application monitoring and failover orchestration, and a variety of application recovery kits for advanced, application-specific intelligence. SIOS DataKeeper can also be used independently to add efficient replication to Windows Server Failover Clustering environments for SANless clustering in the cloud.
Improved High Availability for Business Critical Applications on AWS
In version 8.8, SIOS has added several enhancements to SIOS Protection Suite to make creating and managing clusters in public clouds easy and error free. New features include:
- Application Recovery Kit (ARK) support of AWS Route 53 DNS Service and EC2 Elastic Compute Cloud services
- Integration with these AWS services provides faster and more efficient recovery and access to protected applications after a switchover to a backup server in another AWS Region or Availability Zone.
- SIOS ARKs automate the interaction with cloud services, reducing manual tasks and ensuring configuration accuracy
- Streamlined failover of servers in Azure Cloud using the Internal Load Balancer (ILB)
These new features give enterprises additional confidence that the high availability they have always trusted from SIOS can be achieved in the public cloud, keeping applications and data safe and reducing downtime.