Demo Of SIOS DataKeeper For A Three-Node Cluster In AWS

The SQL Server 2016 Standard Edition can be limited as it only supports a single database per Availability Group so is best suited to the smallest environments. While the SQL Server Enterprise Edition does come with more features and capabilities, this is also reflected in the cost. However, there are various options for achieving high availability (HA) SQL Server with the Standard Edition.
In this video, Dave Bermingham, our Director of Customer Success, talks about how to configure SQL Server Standard Edition for achieving high availability on AWS. He goes into depth about the challenges people face with the Standard Edition and what options they have. Finally, he gives us a demo of how SIOS DataKeeper can be used for a three-node cluster in AWS, enabling a multi-availability zone cluster as well as a multi-region cluster.
Key highlights from this video interview are:
- Bermingham discusses how companies can save money by building a SQL Server FCI using SQL Server Standard.
- Bermingham takes us through the benefits of deploying SQL Server on EC2 and Always On Availability Groups and their benefits.
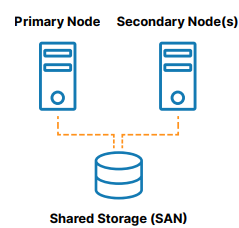
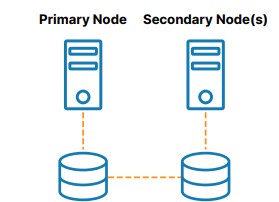
- One of the key challenges of building an SQL Server FCI in any environment is where to run the nodes in different data centers. Bermingham shows what options are there for users.
- Bermingham compares the features of the SQL Server Standard Edition to the Enterprise Edition.
- Bermingham takes us through a demo of a three-node cluster in AWS with two nodes in one region spread between two availability zones and a third node in a different region.