Solution Brief: High Availability for SAP S4/HANA
 SIOS SAN and SANless clustering software provides comprehensive SAP certified protection for your applications and data, including high availability, data replication, and disaster recovery in an easy, cost-efficient solution.
SIOS SAN and SANless clustering software provides comprehensive SAP certified protection for your applications and data, including high availability, data replication, and disaster recovery in an easy, cost-efficient solution.
SIOS software lets you protect SAP and HANA in any configuration (or combination) of physical, virtual, cloud (public, private, and hybrid) and high performance flash storage environments. SIOS software provides easy and flexible configuration, fast replication, and comprehensive monitoring and protection of the entire SAP application environment.
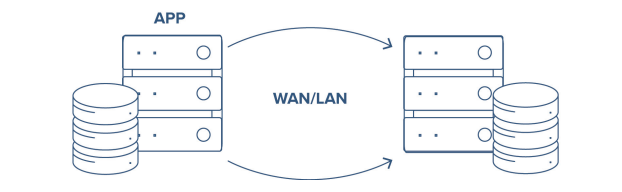
SAN and SANless Clusters You can use SIOS LifeKeeper software to build a traditional SAN-based cluster or build a SIOS SANless cluster by synchronizing local storage on the active SAP Server with local storage on a standby server using SIOS real time, block-level replication. Replication can operate in either synchronous or asynchronous mode.
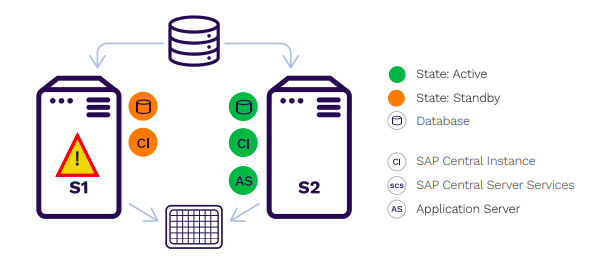
Continuous Monitoring of the Entire SAP S4/HANA Environment
Unlike traditional clustering software that only checks that the server is alive, SIOS LifeKeeper software monitors the health of the entire SAP environment and provides application-aware high availability to ensure maximum uptime. SIOS software verifies that SAP is running, file shares or NFS exports are available, databases are mounted and available, and clients are able to connect. SIOS software actively monitors: servers, operating systems, SAP Primary Application Server (PAS) Instance, ABAP SAP Central Service (ASCS) Instance, back-end databases (Oracle, DB2, MaxDB, MySQL and PostgreSQL), the SAP Central Services Instance (SCS), volumes or file systems, file shares or NFS mounts, IP and virtual IP, Enqueue and message servers,and Logical Volumes (LVM).
Automatic or Manual Failover
In the event of a failure on the active server, SIOS software moves SAP operation to the standby server. SIOS software lets you configure standby servers that are either local or remote over a LAN or WAN. Real-time replication ensures immediate recovery from a local system failure and allows you to create multiple real-time copies through one-to-many replication.
SIOS clusters can also stop and restart the application both locally and on another cluster server at either the same site or at another geographic location. When the SIOS software detects a problem, it automatically initiates one of three configurable recovery actions that will maximize uptime and protection for applications and data: it may attempt a restart on the same server; switchover to a standby server; or alert a system administrator. It performs both local recovery or complete failover quickly and easily.
SAP Disaster Recovery
The SIOS software makes DR testing easy by allowing administrators to move SAP to the DR site for testing and to move it back to the primary site when testing is done. It also lets you leave SAP in service in the primary site while completing DR testing with no impact to your production network by unlocking the target data, bringing SAP into service on the backup system to verify recovery.
Key Benefits
Provide Superior Protection:
• Protects your entire SAP stack with high availability clustering, continuous data replication, and disaster recovery functionality
• Enables single- and multi-site clusters using existing servers and storage
• Supports both JAVA and ABAP versions of SAP servers running on Red Hat Enterprise Linux, SUSE Linux Enterprise Server, or Windows and accommodates a wide range of storage architectures.
Make Clusters Easy
• Intuitive, wizard-driven GUI simplifies installation, configuration and management
• Supports physical, virtual or cloud environments and a wide range of storage architectures
Save Money
• Reduces data transfer costs in cloud environments • Efficient replication engine minimizes network traffic— without hardware accelerators or compression devices. • Saves labor cost by automating data replication tasks using an intuitive management console
Reproduced with permission from SIOS