Date: September 15, 2023

Cara Melindungi Aplikasi di Platform Cloud
Platform cloud hanya melindungi aplikasi dari downtime yang disebabkan oleh kegagalan perangkat keras. Aplikasi misi penting memerlukan perlindungan HA/DR terlepas dari lingkungan cloud tempat mereka beroperasi.
Saat memberikan perlindungan ketersediaan tinggi, prinsip umum adalah memastikan semua komponen bersifat berlebihan untuk menghindari Titik Kegagalan Tunggal (SPOF). Artinya, pastikan tidak ada satu elemen pun yang menyebabkan seluruh sistem berhenti jika gagal. Namun, penting untuk dicatat bahwa infrastruktur operasional sulit diakses di cloud publik.
Dalam cluster ketersediaan tinggi berbasis cloud, ada kemungkinan bahwa node siaga akan ditempatkan di server host yang sama, di rak yang sama, dan menggunakan switch jaringan yang sama dengan node operasi. Kecuali Anda mengkonfigurasi elemen-elemen ini dengan redundansi, salah satu elemen tersebut bisa menjadi SPOF dan menempatkan aplikasi pada risiko kegagalan besar.
Penting untuk memastikan node cluster berada di “wilayah” dan “zona ketersediaan” cloud berbeda yang secara fisik memisahkan pusat data dan infrastruktur operasional di lokasi geografis berbeda.
Apa prinsip utama untuk memastikan ketersediaan di cloud?
Anda tidak dapat mengharapkan berbagai komponen yang membentuk infrastruktur TI fisik untuk beroperasi sesuai spesifikasi selamanya karena komponen-komponennya sudah aus, sistem menjadi tidak kompatibel, dan pengaturan berubah. Meskipun pemeliharaan rutin dapat mengurangi risiko waktu henti, kemungkinan besar akan terjadi kegagalan selama siklus hidup produk.
Dalam beberapa kasus yang jarang terjadi, Anda mungkin memiliki bug serius yang tersembunyi di OS atau perangkat lunak tertanam yang menyebabkan aplikasi berhenti bekerja.
Seperti yang mungkin sudah Anda ketahui, konfigurasi cluster HA sejalan dengan prinsip ini, dan satu titik kegagalan dihilangkan dengan membuat server penting dan sumber dayanya menjadi mubazir ke sistem aktif (sistem produksi). Namun, penting untuk mengingat dua hal: 1. perangkat keras server bukan satu-satunya komponen penting dan 2. komponen SPOF penting lainnya mungkin tidak terlihat oleh Anda di infrastruktur cloud publik.
Waspadai jebakan satu titik kegagalan yang tersembunyi di infrastruktur cloud yang tidak terlihat
Sebagian besar cloud publik beroperasi dalam apa yang disebut mode “multi-penyewa”. Artinya, mereka menjalankan VM dari beberapa perusahaan di server host fisik yang sama. Dan dengan kontrak reguler, Anda tidak dapat menentukan server host mana yang dijalankan sistem Anda. Hal ini dapat menyebabkan masalah seperti
node siaga di cluster cloud Anda dapat ditempatkan di server host yang sama yang mengoperasikan node aktif. Bahkan jika Anda mengonfigurasi konfigurasi kluster HA, jika server host mati, simpul operasi dan simpul siaga akan ikut mati juga. Dalam skenario ini, operator cloud Anda memutuskan kapan dan bagaimana sistem Anda akan dipulihkan.
Server host yang mengoperasikan node aktif dan server host yang mengoperasikan node siaga mungkin berada di rak yang sama. Dalam hal ini, rak menjadi SPOF, jadi jika terjadi kegagalan maka node aktif dan standby di bawahnya juga akan gagal.
Selain itu, di lapisan atas infrastruktur Anda seperti switch jaringan yang menggabungkan beberapa rak, gateway, dan router, serta unit catu daya di pusat data, node sistem operasi dan node sistem siaga dapat hidup berdampingan dalam sistem yang sama, dan jika kunci-kunci ini Jika komponen tidak mubazir, maka Anda akan menemui satu titik kegagalan yang tidak bisa dihindari. Sekali lagi, bagi perusahaan yang merupakan pengguna cloud publik, infrastruktur pusat data seperti itu adalah sebuah kotak hitam (black box), mungkin mustahil untuk melihat konfigurasi terperinci untuk mengidentifikasi SPOF.
Zona dan wilayah ketersediaan cloud publik harus dimanfaatkan untuk ketersediaan
Bagaimana kita dapat secara eksplisit menghindari satu titik kegagalan yang tersembunyi di cloud publik? Metode yang paling tangguh adalah dengan menggunakan “Availability Zone” dan “Wilayah” yang disiapkan di sisi cloud.
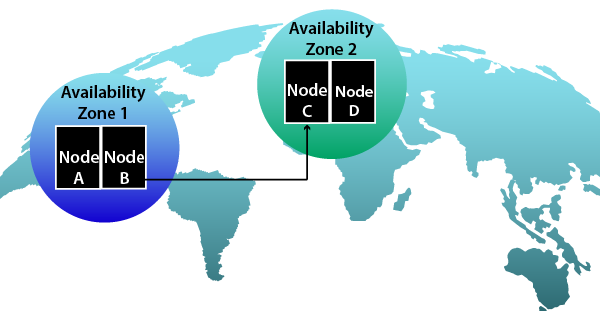
Availability Zone adalah pemisahan fisik independen dari infrastruktur dalam pusat data Anda. Dan wilayah merupakan pusat data independen yang terpisah secara geografis. Cloud publik memungkinkan Anda dengan sengaja menggunakan Availability Zone atau wilayah ini untuk tujuan yang berbeda.
Dengan membangun konfigurasi klaster HA di mana node operasi dan node siaga didistribusikan di zona ketersediaan berbeda di dua wilayah atau lebih, hampir semua SPOF dapat dihindari dengan pasti. Jika Anda mematuhi praktik terbaik ini, Anda dapat memastikan ketersediaannya dengan yakin, DR(Pemulihan bencana) dan BCP (Perencanaan Kesinambungan Bisnis).
Direproduksi dengan izin dariSIOS