Date: November 23, 2021
Tags: clusters

Introduction To Clusters – Part 2
What Types of Clusters Are There and How Do They Work?
An Overview of HA Clusters, and Load Balancing Clusters
Clustering helps improve reliability and performance of software and hardware systems by creating redundancy to compensate for unforeseen system failure. If a system is interrupted due to hardware or software failure or natural disaster, this can have a major impact on business and revenue, wasting crucial time and expense to get things back up and running.
This is where clustering comes in. There are three main types of clustering solutions – HA clusters, load balancing clusters, and HPC clusters. Which type will best increase system availability and performance for your business? Let’s have a look at the three types of clustering solutions in more detail below.
What is HA Clustering?
High Availability clustering, also known as HA clustering, is effective for mission-critical business applications, ERP systems, and databases, such as SQL Server SAP, and Oracle that require near-continuous availability.
HA clustering can be divided into two types, “Active-Active” configuration and active-passive configuration.
Let’s take a look at the difference between these two HA clustering types.
HA Clustering Type 1: Active-Active Configuration
In the active-active configuration, processing is performed on all nodes in the cluster. For example, in the case of two-node clustering, both nodes are active. If one node stops, the processing will be taken over the other.
However, if each node is operating at close to 100% and one node stops, it will be difficult for another node to take on the additional processing load. Therefore, capacity planning with a margin is important for HA clustering.
HA Clustering Type 2: Active-Standby Configuration
Let’s use our two-node example again. In the active-standby configuration, one node is configured as the active node and the other node is configured as the standby node. The active node and the standby node exchange signals called “heartbeats” to constantly check whether they are operating normally.
If the standby node cannot receive the heartbeat of the active node, the standby node determines that the active node has stopped and will take over the processing of the active node. This mechanism is called “failover”. Conversely, the mechanism that recovers the stopped operating node and transfers the processing back to the recovered active node is called “failback.”
In an active/standby configuration, when a failure occurs, the simple switch from the active node to the standby node makes recovery relatively easy. However, it is necessary to consider that the resources of the standby node when the operating node is operating normally will be wasted.
Two Components of HA Clustering: Application and Storage
For an HA cluster to be effective, two areas need to be addressed: application orchestration and storage protection. Clustering software monitors the health of the application being protected and, if it detects an issue, moves operation of that application over to the standby node. The standby node needs access to the most up-to-date versions of data – preferably identical to the data that the primary node was accessing before the incident. This can be accomplished in two ways: shared storage, share-nothing storage. In the shared storage model, both cluster nodes access the same storage – typically a SAN. In shared-nothing (aka SANless) configurations, local storage on all nodes are mirrored using replication software.
Clustering software products vary widely in their ability to monitor and detect issues that may cause application failure and in their ability to orchestrate failovers reliably. Many clustering products only detect whether the application server is operational, but do not detect a wide range of software, services, network, and other issues that can cause application failure.
Application Awareness is Essential
Similarly, complex ERP and database applications have multiple component parts that have to be stored on the correct server or instance, started up in the right order, and brought on line in accordance with complex best practices. Choose a clustering software with specialized software called application recovery kits designed specifically to maintain best practices for the application/database-specific requirements.
There are multiple ways to configure an HA Cluster:
Traditional Two Node Clusters with Shared Storage
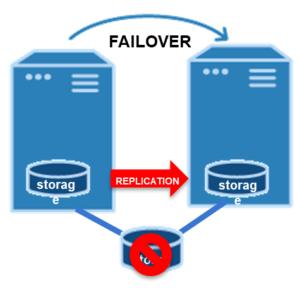
Two Node SANless Cluster
Clusters can be configured using local LAN and high speed synchronous block-level replication.
Real-time replication can be used to synchronize storage on the primary server with storage on a standby server located in the same data center, in your disaster recovery site, or both. This allows you to build high availability and disaster recovery configurations flexibly; Two node or multi-nodeSIOS block level replication is highly optimized for performance. You can even use super fast, high-speed locally attached storage such as PCIe flash type storage devices on your physical servers to achieve very low cost, high performance, high availability configurations. Your data is protected on the flash device and your application too.
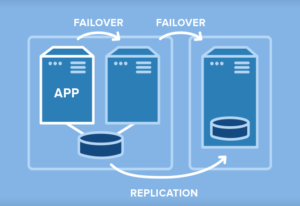
Third Node for Disaster Protection
This configuration uses a SAN-based cluster and adds a third, SANless node into a remote data center or the cloud and achieve full disaster recovery protection. In the event of a disaster, the standby remote physical server is brought into service automatically with no data loss, eliminating the hours needed for restoration from backup media.
What is a Load Balancing Cluster?
Load balancing clustering is a mechanism that can be used as a single system by distributing processing to multiple nodes using a load balancer to improve performance by distributing processing. While it can isolate a failed node to prevent node failure from affecting the entire system, the load balancer is a critical single point of failure risk and not a high availability option. It is only effective for applications such web server load balancing. If the load balancer itself fails, the entire system stops.
What is HPC Clustering?
You can also use clustering for performance instead of high availability. High-Performance Computing clusters, or HPC clusters combine the processing power of multiple (sometimes thousands of nodes) to get the CPU performance needed in CPU-intensive environments such as scientific and technological environments requiring large-scale simulations, CAE analysis, and parallel processing.
Are you ready to find the right HA clustering solution for your business?
Learn more about SIOS High Availability clustering here.
Reproduced with permission from SIOS