Date: November 18, 2021
Tags: cluster, Clustering, SIOS

Introduction To Clusters – Part 1
What is clustering in the first place?
Clustering technology is a technology that allows you to connect multiple servers to act as a single functional unit.
Types of clustering
You can cluster servers for several purposes. For example, you can combine the processing power of multiple small servers for high performance. You can also distribute processing work to multiple nodes using a load balancer for added efficiency.
High availability (HA) clustering is a process of combining server nodes to protect important applications from downtime and data loss.
HA Clustering
High availability (HA) clustering is a mechanism that reduces downtime by eliminating single points of failure (SPOF). In an HA cluster, important applications are run on a primary node which is connected to one or more secondary or remote nodes in a cluster. Clustering software monitors the health of the application, server, and network. In the event of a failure on the primary node, it moves application operations over to a secondary node in a process called a failover, where operation continues.
High Availability
Application high availability is a measure of how much time in a given year an application is available and operational. In general, HA clusters provide 99.99% (Four nines) availability or a little more than 52 minutes of downtime over the course of a given year.
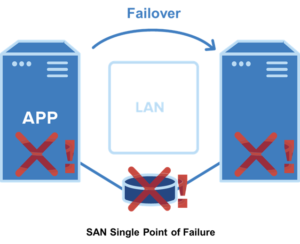
It is important to note that in a traditional HA cluster, all of the cluster nodes are connected to the same shared storage – typically a SAN. In this way, after a failover, the secondary node is accessing the same data as the primary node and operation can continue.
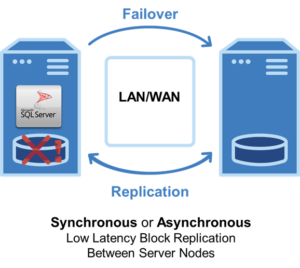
SANless Clusters
However, many companies prefer to use a SANless cluster for several reasons. First, shared storage represents a critical single point of failure. Second, shared storage is often not an option in public cloud environments. Third, SANs can sometimes impede performance of database applications, such as SQL Server, Oracle, and SAP.
Instead of shared storage, these companies use efficient, host-based, block-level replication to synchronize local storage on all cluster nodes. In the event of a failover, the secondary node is connected to local storage with an identical copy of the primary storage. This not only eliminates the SAN SPOF risk but also enables the addition of fast disk (SSD) to local on-premises storage for cost-efficient high performance. SANless clustering also enables companies to migrate on-premises HA environments to the cloud with minimal effort or disruption of ongoing business processes.
Reproduced from SIOS